 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunPRM: Function-as-Step Process Reward Model with Meta Reward Correction for Code Generation
Jan 29, 2026Code generation is a core application of large language models (LLMs), yet LLMs still frequently fail on complex programming tasks. Given its success in mathematical reasoning, test-time scaling approaches such as Process Reward Model (PRM)-based Best-of-N selection offer a promising way to improve performance. However, existing PRMs remain ineffective for code generation due to the lack of meaningful step decomposition in code and the noise of Monte Carlo-estimated partial-solution correctness scores (rewards). To address these challenges, we propose FunPRM. FunPRM prompts LLMs to encourage modular code generation organized into functions, with functions treated as PRM reasoning steps. Furthermore, FunPRM introduces a novel meta-learning-based reward correction mechanism that leverages clean final-solution rewards obtained via a unit-test-based evaluation system to purify noisy partial-solution rewards. Experiments on LiveCodeBench and BigCodeBench demonstrate that FunPRM consistently outperforms existing test-time scaling methods across five base LLMs, notably achieving state-of-the-art performance on LiveCodeBench when combined with O4-mini. Furthermore, FunPRM produces code that is more readable and reusable for developers.
MuseCPBench: an Empirical Study of Music Editing Methods through Music Context Preservation
Dec 16, 2025Music editing plays a vital role in modern music production, with applications in film, broadcasting, and game development. Recent advances in music generation models have enabled diverse editing tasks such as timbre transfer, instrument substitution, and genre transformation. However, many existing works overlook the evaluation of their ability to preserve musical facets that should remain unchanged during editing a property we define as Music Context Preservation (MCP). While some studies do consider MCP, they adopt inconsistent evaluation protocols and metrics, leading to unreliable and unfair comparisons. To address this gap, we introduce the first MCP evaluation benchmark, MuseCPBench, which covers four categories of musical facets and enables comprehensive comparisons across five representative music editing baselines. Through systematic analysis along musical facets, methods, and models, we identify consistent preservation gaps in current music editing methods and provide insightful explanations. We hope our findings offer practical guidance for developing more effective and reliable music editing strategies with strong MCP capability
Steganographic Backdoor Attacks in NLP: Ultra-Low Poisoning and Defense Evasion
Nov 18, 2025Transformer models are foundational to natural language processing (NLP) applications, yet remain vulnerable to backdoor attacks introduced through poisoned data, which implant hidden behaviors during training. To strengthen the ability to prevent such compromises, recent research has focused on designing increasingly stealthy attacks to stress-test existing defenses, pairing backdoor behaviors with stylized artifact or token-level perturbation triggers. However, this trend diverts attention from the harder and more realistic case: making the model respond to semantic triggers such as specific names or entities, where a successful backdoor could manipulate outputs tied to real people or events in deployed systems. Motivated by this growing disconnect, we introduce SteganoBackdoor, bringing stealth techniques back into line with practical threat models. Leveraging innocuous properties from natural-language steganography, SteganoBackdoor applies a gradient-guided data optimization process to transform semantic trigger seeds into steganographic carriers that embed a high backdoor payload, remain fluent, and exhibit no representational resemblance to the trigger. Across diverse experimental settings, SteganoBackdoor achieves over 99% attack success at an order-of-magnitude lower data-poisoning rate than prior approaches while maintaining unparalleled evasion against a comprehensive suite of data-level defenses. By revealing this practical and covert attack, SteganoBackdoor highlights an urgent blind spot in current defenses and demands immediate attention to adversarial data defenses and real-world threat modeling.
A New Benchmark for Online Learning with Budget-Balancing Constraints
Mar 19, 2025The adversarial Bandit with Knapsack problem is a multi-armed bandits problem with budget constraints and adversarial rewards and costs. In each round, a learner selects an action to take and observes the reward and cost of the selected action. The goal is to maximize the sum of rewards while satisfying the budget constraint. The classical benchmark to compare against is the best fixed distribution over actions that satisfies the budget constraint in expectation. Unlike its stochastic counterpart, where rewards and costs are drawn from some fixed distribution (Badanidiyuru et al., 2018), the adversarial BwK problem does not admit a no-regret algorithm for every problem instance due to the "spend-or-save" dilemma (Immorlica et al., 2022). A key problem left open by existing works is whether there exists a weaker but still meaningful benchmark to compare against such that no-regret learning is still possible. In this work, we present a new benchmark to compare against, motivated both by real-world applications such as autobidding and by its underlying mathematical structure. The benchmark is based on the Earth Mover's Distance (EMD), and we show that sublinear regret is attainable against any strategy whose spending pattern is within EMD $o(T^2)$ of any sub-pacing spending pattern. As a special case, we obtain results against the "pacing over windows" benchmark, where we partition time into disjoint windows of size $w$ and allow the benchmark strategies to choose a different distribution over actions for each window while satisfying a pacing budget constraint. Against this benchmark, our algorithm obtains a regret bound of $\tilde{O}(T/\sqrt{w}+\sqrt{wT})$. We also show a matching lower bound, proving the optimality of our algorithm in this important special case. In addition, we provide further evidence of the necessity of the EMD condition for obtaining a sublinear regret.
IMPROVE: Iterative Model Pipeline Refinement and Optimization Leveraging LLM Agents
Feb 25, 2025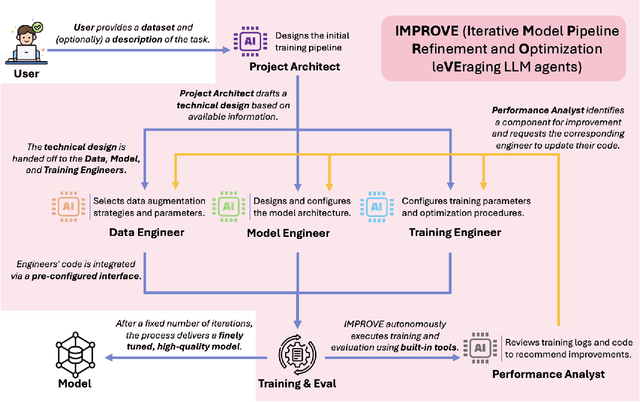



Computer vision is a critical component in a wide range of real-world applications, including plant monitoring in agriculture and handwriting classification in digital systems. However, developing high-performance computer vision models traditionally demands both machine learning (ML) expertise and domain-specific knowledge, making the process costly, labor-intensive, and inaccessible to many. Large language model (LLM) agents have emerged as a promising solution to automate this workflow, but most existing methods share a common limitation: they attempt to optimize entire pipelines in a single step before evaluation, making it difficult to attribute improvements to specific changes. This lack of granularity leads to unstable optimization and slower convergence, limiting their effectiveness. To address this, we introduce Iterative Refinement, a novel strategy for LLM-driven ML pipeline design inspired by how human ML experts iteratively refine models, focusing on one component at a time rather than making sweeping changes all at once. By systematically updating individual components based on real training feedback, Iterative Refinement improves stability, interpretability, and overall model performance. We implement this strategy in IMPROVE, an end-to-end LLM agent framework for automating and optimizing object classification pipelines. Through extensive evaluations across datasets of varying sizes and domains, including standard benchmarks and Kaggle competition datasets, we demonstrate that Iterative Refinement enables IMPROVE to consistently achieve better performance over existing zero-shot LLM-based approaches. These findings establish Iterative Refinement as an effective new strategy for LLM-driven ML automation and position IMPROVE as an accessible solution for building high-quality computer vision models without requiring ML expertise.
Towards Adversarially Robust Dataset Distillation by Curvature Regularization
Mar 15, 2024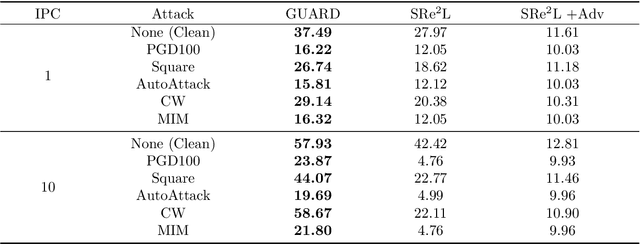

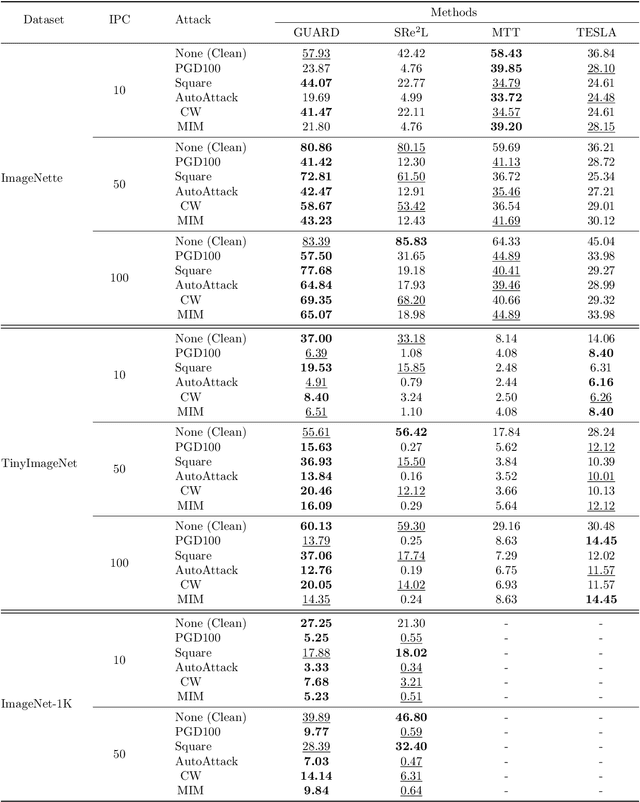
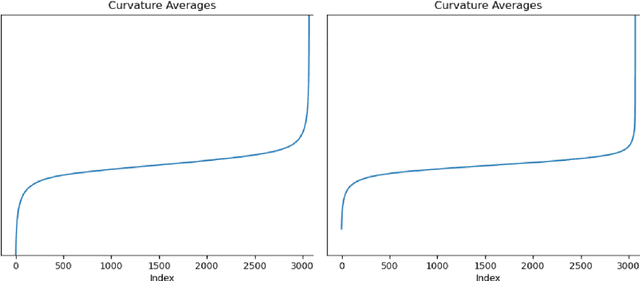
Dataset distillation (DD) allows datasets to be distilled to fractions of their original size while preserving the rich distributional information so that models trained on the distilled datasets can achieve a comparable accuracy while saving significant computational loads. Recent research in this area has been focusing on improving the accuracy of models trained on distilled datasets. In this paper, we aim to explore a new perspective of DD. We study how to embed adversarial robustness in distilled datasets, so that models trained on these datasets maintain the high accuracy and meanwhile acquire better adversarial robustness. We propose a new method that achieves this goal by incorporating curvature regularization into the distillation process with much less computational overhead than standard adversarial training. Extensive empirical experiments suggest that our method not only outperforms standard adversarial training on both accuracy and robustness with less computation overhead but is also capable of generating robust distilled datasets that can withstand various adversarial attacks.
CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
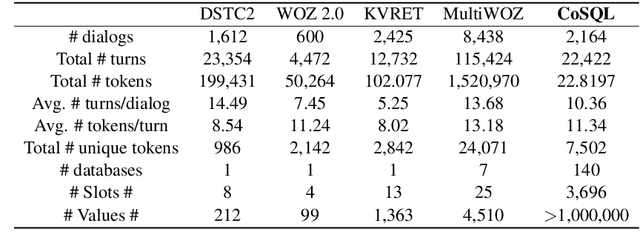
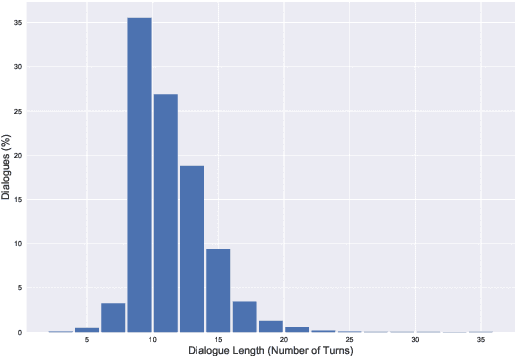
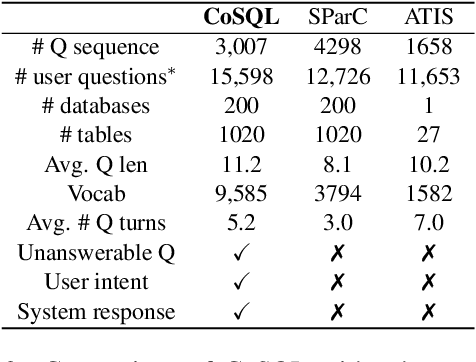
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
Editing-Based SQL Query Generation for Cross-Domain Context-Dependent Questions
Sep 10, 2019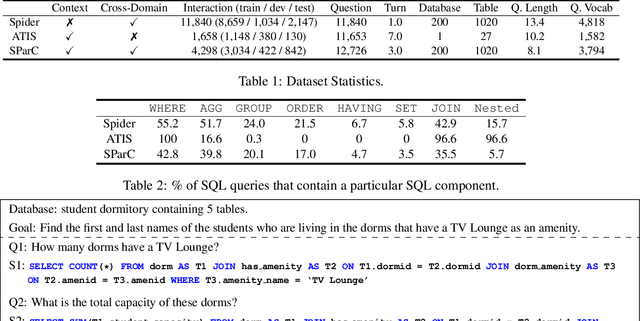
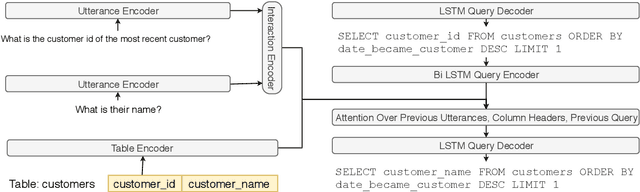
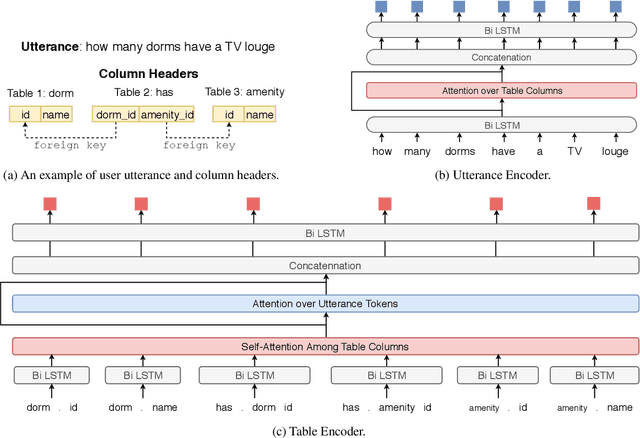
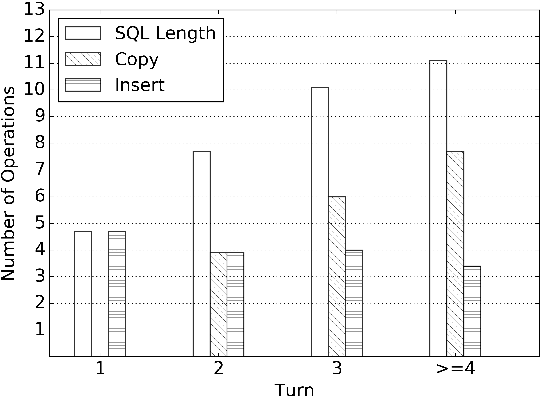
We focus on the cross-domain context-dependent text-to-SQL generation task. Based on the observation that adjacent natural language questions are often linguistically dependent and their corresponding SQL queries tend to overlap, we utilize the interaction history by editing the previous predicted query to improve the generation quality. Our editing mechanism views SQL as sequences and reuses generation results at the token level in a simple manner. It is flexible to change individual tokens and robust to error propagation. Furthermore, to deal with complex table structures in different domains, we employ an utterance-table encoder and a table-aware decoder to incorporate the context of the user utterance and the table schema. We evaluate our approach on the SParC dataset and demonstrate the benefit of editing compared with the state-of-the-art baselines which generate SQL from scratch. Our code is available at https://github.com/ryanzhumich/sparc_atis_pytorch.