 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Token Prediction and Regret Minimization
Mar 30, 2026We consider the question of how to employ next-token prediction algorithms in adversarial online decision-making environments. Specifically, if we train a next-token prediction model on a distribution $\mathcal{D}$ over sequences of opponent actions, when is it the case that the induced online decision-making algorithm (by approximately best responding to the model's predictions) has low adversarial regret (i.e., when is $\mathcal{D}$ a \emph{low-regret distribution})? For unbounded context windows (where the prediction made by the model can depend on all the actions taken by the adversary thus far), we show that although not every distribution $\mathcal{D}$ is a low-regret distribution, every distribution $\mathcal{D}$ is exponentially close (in TV distance) to one low-regret distribution, and hence sublinear regret can always be achieved at negligible cost to the accuracy of the original next-token prediction model. In contrast to this, for bounded context windows (where the prediction made by the model can depend only on the past $w$ actions taken by the adversary, as may be the case in modern transformer architectures), we show that there are some distributions $\mathcal{D}$ of opponent play that are $Θ(1)$-far from any low-regret distribution $\mathcal{D'}$ (even when $w = Ω(T)$ and such distributions exist). Finally, we complement these results by showing that the unbounded context robustification procedure can be implemented by layers of a standard transformer architecture, and provide empirical evidence that transformer models can be efficiently trained to represent these new low-regret distributions.
Efficient Opportunistic Approachability
Feb 24, 2026We study the problem of opportunistic approachability: a generalization of Blackwell approachability where the learner would like to obtain stronger guarantees (i.e., approach a smaller set) when their adversary limits themselves to a subset of their possible action space. Bernstein et al. (2014) introduced this problem in 2014 and presented an algorithm that guarantees sublinear approachability rates for opportunistic approachability. However, this algorithm requires the ability to produce calibrated online predictions of the adversary's actions, a problem whose standard implementations require time exponential in the ambient dimension and result in approachability rates that scale as $T^{-O(1/d)}$. In this paper, we present an efficient algorithm for opportunistic approachability that achieves a rate of $O(T^{-1/4})$ (and an inefficient one that achieves a rate of $O(T^{-1/3})$), bypassing the need for an online calibration subroutine. Moreover, in the case where the dimension of the adversary's action set is at most two, we show it is possible to obtain the optimal rate of $O(T^{-1/2})$.
Near-optimal Swap Regret Minimization for Convex Losses
Feb 09, 2026We give a randomized online algorithm that guarantees near-optimal $\widetilde O(\sqrt T)$ expected swap regret against any sequence of $T$ adaptively chosen Lipschitz convex losses on the unit interval. This improves the previous best bound of $\widetilde O(T^{2/3})$ and answers an open question of Fishelson et al. [2025b]. In addition, our algorithm is efficient: it runs in $\mathsf{poly}(T)$ time. A key technical idea we develop to obtain this result is to discretize the unit interval into bins at multiple scales of granularity and simultaneously use all scales to make randomized predictions, which we call multi-scale binning and may be of independent interest. A direct corollary of our result is an efficient online algorithm for minimizing the calibration error for general elicitable properties. This result does not require the Lipschitzness assumption of the identification function needed in prior work, making it applicable to median calibration, for which we achieve the first $\widetilde O(\sqrt T)$ calibration error guarantee.
Swap Regret Minimization Through Response-Based Approachability
Feb 05, 2026We consider the problem of minimizing different notions of swap regret in online optimization. These forms of regret are tightly connected to correlated equilibrium concepts in games, and have been more recently shown to guarantee non-manipulability against strategic adversaries. The only computationally efficient algorithm for minimizing linear swap regret over a general convex set in $\mathbb{R}^d$ was developed recently by Daskalakis, Farina, Fishelson, Pipis, and Schneider (STOC '25). However, it incurs a highly suboptimal regret bound of $Ω(d^4 \sqrt{T})$ and also relies on computationally intensive calls to the ellipsoid algorithm at each iteration. In this paper, we develop a significantly simpler, computationally efficient algorithm that guarantees $O(d^{3/2} \sqrt{T})$ linear swap regret for a general convex set and $O(d \sqrt{T})$ when the set is centrally symmetric. Our approach leverages the powerful response-based approachability framework of Bernstein and Shimkin (JMLR '15) -- previously overlooked in the line of work on swap regret minimization -- combined with geometric preconditioning via the John ellipsoid. Our algorithm simultaneously minimizes profile swap regret, which was recently shown to guarantee non-manipulability. Moreover, we establish a matching information-theoretic lower bound: any learner must incur in expectation $Ω(d \sqrt{T})$ linear swap regret for large enough $T$, even when the set is centrally symmetric. This also shows that the classic algorithm of Gordon, Greenwald, and Marks (ICML '08) is existentially optimal for minimizing linear swap regret, although it is computationally inefficient. Finally, we extend our approach to minimize regret with respect to the set of swap deviations with polynomial dimension, unifying and strengthening recent results in equilibrium computation and online learning.
Coherence Mechanisms for Provable Self-Improvement
Nov 11, 2025Self-improvement is a critical capability for large language models and other intelligent systems, enabling them to refine their behavior and internal consistency without external supervision. Despite its importance, prior approaches largely rely on empirical heuristics and lack formal guarantees. In this paper, we propose a principled framework for self-improvement based on the concept of \emph{coherence}, which requires that a model's outputs remain consistent under task-preserving transformations of the input. We formalize this concept using projection-based mechanisms that update a baseline model to be coherent while remaining as close as possible to its original behavior. We provide rigorous theoretical guarantees that these mechanisms achieve \emph{monotonic improvement}, measured by a reduction in expected Bregman divergence. Our analysis is comprehensive, covering both \emph{direct} and \emph{two-step} projection methods, and robustly extends these guarantees to non-realizable settings, empirical (finite-sample) distributions, and relaxed coherence constraints. Furthermore, we establish a general \emph{characterization theorem}, showing that any mechanism with similar provable improvement guarantees must inherently conform to a coherence-based structure. This culminates in rigidity results under the demand for universal improvement, establishing coherence as a fundamental and, in a formal sense, necessary principle for provable self-improvement.
High-Dimensional Calibration from Swap Regret
May 27, 2025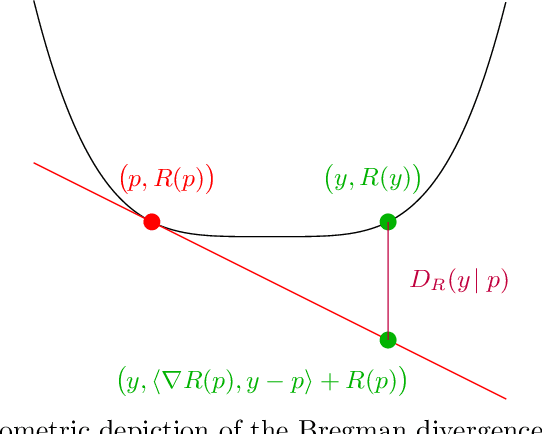
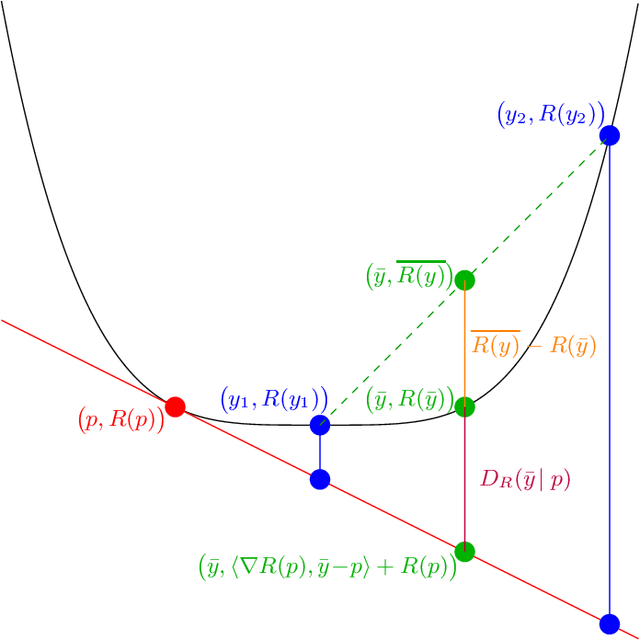

We study the online calibration of multi-dimensional forecasts over an arbitrary convex set $\mathcal{P} \subset \mathbb{R}^d$ relative to an arbitrary norm $\Vert\cdot\Vert$. We connect this with the problem of external regret minimization for online linear optimization, showing that if it is possible to guarantee $O(\sqrt{\rho T})$ worst-case regret after $T$ rounds when actions are drawn from $\mathcal{P}$ and losses are drawn from the dual $\Vert \cdot \Vert_*$ unit norm ball, then it is also possible to obtain $\epsilon$-calibrated forecasts after $T = \exp(O(\rho /\epsilon^2))$ rounds. When $\mathcal{P}$ is the $d$-dimensional simplex and $\Vert \cdot \Vert$ is the $\ell_1$-norm, the existence of $O(\sqrt{T\log d})$-regret algorithms for learning with experts implies that it is possible to obtain $\epsilon$-calibrated forecasts after $T = \exp(O(\log{d}/\epsilon^2)) = d^{O(1/\epsilon^2)}$ rounds, recovering a recent result of Peng (2025). Interestingly, our algorithm obtains this guarantee without requiring access to any online linear optimization subroutine or knowledge of the optimal rate $\rho$ -- in fact, our algorithm is identical for every setting of $\mathcal{P}$ and $\Vert \cdot \Vert$. Instead, we show that the optimal regularizer for the above OLO problem can be used to upper bound the above calibration error by a swap regret, which we then minimize by running the recent TreeSwap algorithm with Follow-The-Leader as a subroutine. Finally, we prove that any online calibration algorithm that guarantees $\epsilon T$ $\ell_1$-calibration error over the $d$-dimensional simplex requires $T \geq \exp(\mathrm{poly}(1/\epsilon))$ (assuming $d \geq \mathrm{poly}(1/\epsilon)$). This strengthens the corresponding $d^{\Omega(\log{1/\epsilon})}$ lower bound of Peng, and shows that an exponential dependence on $1/\epsilon$ is necessary.
A New Benchmark for Online Learning with Budget-Balancing Constraints
Mar 19, 2025The adversarial Bandit with Knapsack problem is a multi-armed bandits problem with budget constraints and adversarial rewards and costs. In each round, a learner selects an action to take and observes the reward and cost of the selected action. The goal is to maximize the sum of rewards while satisfying the budget constraint. The classical benchmark to compare against is the best fixed distribution over actions that satisfies the budget constraint in expectation. Unlike its stochastic counterpart, where rewards and costs are drawn from some fixed distribution (Badanidiyuru et al., 2018), the adversarial BwK problem does not admit a no-regret algorithm for every problem instance due to the "spend-or-save" dilemma (Immorlica et al., 2022). A key problem left open by existing works is whether there exists a weaker but still meaningful benchmark to compare against such that no-regret learning is still possible. In this work, we present a new benchmark to compare against, motivated both by real-world applications such as autobidding and by its underlying mathematical structure. The benchmark is based on the Earth Mover's Distance (EMD), and we show that sublinear regret is attainable against any strategy whose spending pattern is within EMD $o(T^2)$ of any sub-pacing spending pattern. As a special case, we obtain results against the "pacing over windows" benchmark, where we partition time into disjoint windows of size $w$ and allow the benchmark strategies to choose a different distribution over actions for each window while satisfying a pacing budget constraint. Against this benchmark, our algorithm obtains a regret bound of $\tilde{O}(T/\sqrt{w}+\sqrt{wT})$. We also show a matching lower bound, proving the optimality of our algorithm in this important special case. In addition, we provide further evidence of the necessity of the EMD condition for obtaining a sublinear regret.
Swap Regret and Correlated Equilibria Beyond Normal-Form Games
Feb 27, 2025Swap regret is a notion that has proven itself to be central to the study of general-sum normal-form games, with swap-regret minimization leading to convergence to the set of correlated equilibria and guaranteeing non-manipulability against a self-interested opponent. However, the situation for more general classes of games -- such as Bayesian games and extensive-form games -- is less clear-cut, with multiple candidate definitions for swap-regret but no known efficiently minimizable variant of swap regret that implies analogous non-manipulability guarantees. In this paper, we present a new variant of swap regret for polytope games that we call ``profile swap regret'', with the property that obtaining sublinear profile swap regret is both necessary and sufficient for any learning algorithm to be non-manipulable by an opponent (resolving an open problem of Mansour et al., 2022). Although we show profile swap regret is NP-hard to compute given a transcript of play, we show it is nonetheless possible to design efficient learning algorithms that guarantee at most $O(\sqrt{T})$ profile swap regret. Finally, we explore the correlated equilibrium notion induced by low-profile-swap-regret play, and demonstrate a gap between the set of outcomes that can be implemented by this learning process and the set of outcomes that can be implemented by a third-party mediator (in contrast to the situation in normal-form games).
Best of Both Worlds: Regret Minimization versus Minimax Play
Feb 17, 2025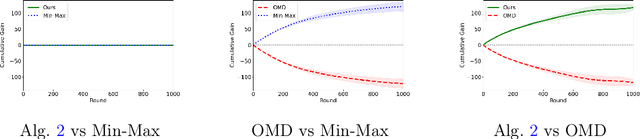


In this paper, we investigate the existence of online learning algorithms with bandit feedback that simultaneously guarantee $O(1)$ regret compared to a given comparator strategy, and $O(\sqrt{T})$ regret compared to the best strategy in hindsight, where $T$ is the number of rounds. We provide the first affirmative answer to this question. In the context of symmetric zero-sum games, both in normal- and extensive form, we show that our results allow us to guarantee to risk at most $O(1)$ loss while being able to gain $\Omega(T)$ from exploitable opponents, thereby combining the benefits of both no-regret algorithms and minimax play.
Full Swap Regret and Discretized Calibration
Feb 13, 2025We study the problem of minimizing swap regret in structured normal-form games. Players have a very large (potentially infinite) number of pure actions, but each action has an embedding into $d$-dimensional space and payoffs are given by bilinear functions of these embeddings. We provide an efficient learning algorithm for this setting that incurs at most $\tilde{O}(T^{(d+1)/(d+3)})$ swap regret after $T$ rounds. To achieve this, we introduce a new online learning problem we call \emph{full swap regret minimization}. In this problem, a learner repeatedly takes a (randomized) action in a bounded convex $d$-dimensional action set $\mathcal{K}$ and then receives a loss from the adversary, with the goal of minimizing their regret with respect to the \emph{worst-case} swap function mapping $\mathcal{K}$ to $\mathcal{K}$. For varied assumptions about the convexity and smoothness of the loss functions, we design algorithms with full swap regret bounds ranging from $O(T^{d/(d+2)})$ to $O(T^{(d+1)/(d+2)})$. Finally, we apply these tools to the problem of online forecasting to minimize calibration error, showing that several notions of calibration can be viewed as specific instances of full swap regret. In particular, we design efficient algorithms for online forecasting that guarantee at most $O(T^{1/3})$ $\ell_2$-calibration error and $O(\max(\sqrt{\epsilon T}, T^{1/3}))$ \emph{discretized-calibration} error (when the forecaster is restricted to predicting multiples of $\epsilon$).