 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the Value of Censored Data? An Exact Analysis for the Data-driven Newsvendor
Feb 18, 2026We study the offline data-driven newsvendor problem with censored demand data. In contrast to prior works where demand is fully observed, we consider the setting where demand is censored at the inventory level and only sales are observed; sales match demand when there is sufficient inventory, and equal the available inventory otherwise. We provide a general procedure to compute the exact worst-case regret of classical data-driven inventory policies, evaluated over all demand distributions. Our main technical result shows that this infinite-dimensional, non-convex optimization problem can be reduced to a finite-dimensional one, enabling an exact characterization of the performance of policies for any sample size and censoring levels. We leverage this reduction to derive sharp insights on the achievable performance of standard inventory policies under demand censoring. In particular, our analysis of the Kaplan-Meier policy shows that while demand censoring fundamentally limits what can be learned from passive sales data, just a small amount of targeted exploration at high inventory levels can substantially improve worst-case guarantees, enabling near-optimal performance even under heavy censoring. In contrast, when the point-of-sale system does not record stockout events and only reports realized sales, a natural and commonly used approach is to treat sales as demand. Our results show that policies based on this sales-as-demand heuristic can suffer severe performance degradation as censored data accumulates, highlighting how the quality of point-of-sale information critically shapes what can, and cannot, be learned offline.
Online Generalized-mean Welfare Maximization: Achieving Near-Optimal Regret from Samples
Feb 11, 2026We study online fair allocation of $T$ sequentially arriving items among $n$ agents with heterogeneous preferences, with the objective of maximizing generalized-mean welfare, defined as the $p$-mean of agents' time-averaged utilities, with $p\in (-\infty, 1)$. We first consider the i.i.d. arrival model and show that the pure greedy algorithm -- which myopically chooses the welfare-maximizing integral allocation -- achieves $\widetilde{O}(1/T)$ average regret. Importantly, in contrast to prior work, our algorithm does not require distributional knowledge and achieves the optimal regret rate using only the online samples. We then go beyond i.i.d. arrivals and investigate a nonstationary model with time-varying independent distributions. In the absence of additional data about the distributions, it is known that every online algorithm must suffer $Ω(1)$ average regret. We show that only a single historical sample from each distribution is sufficient to recover the optimal $\widetilde{O}(1/T)$ average regret rate, even in the face of arbitrary non-stationarity. Our algorithms are based on the re-solving paradigm: they assume that the remaining items will be the ones seen historically in those periods and solve the resulting welfare-maximization problem to determine the decision in every period. Finally, we also account for distribution shifts that may distort the fidelity of historical samples and show that the performance of our re-solving algorithms is robust to such shifts.
Strategically-Robust Learning Algorithms for Bidding in First-Price Auctions
Feb 12, 2024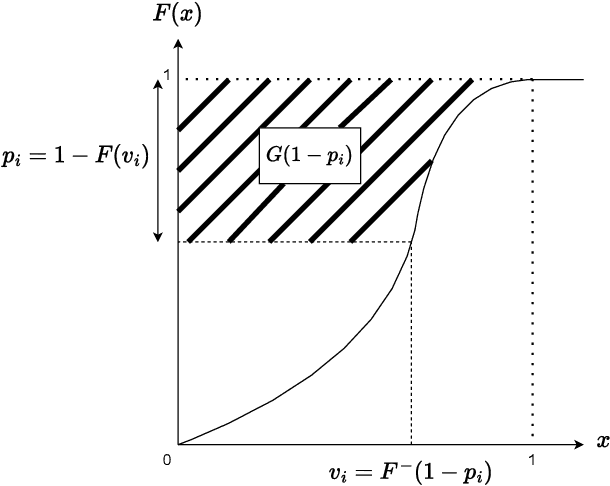
Learning to bid in repeated first-price auctions is a fundamental problem at the interface of game theory and machine learning, which has seen a recent surge in interest due to the transition of display advertising to first-price auctions. In this work, we propose a novel concave formulation for pure-strategy bidding in first-price auctions, and use it to analyze natural Gradient-Ascent-based algorithms for this problem. Importantly, our analysis goes beyond regret, which was the typical focus of past work, and also accounts for the strategic backdrop of online-advertising markets where bidding algorithms are deployed -- we prove that our algorithms cannot be exploited by a strategic seller and that they incentivize truth-telling for the buyer. Concretely, we show that our algorithms achieve $O(\sqrt{T})$ regret when the highest competing bids are generated adversarially, and show that no online algorithm can do better. We further prove that the regret improves to $O(\log T)$ when the competition is stationary and stochastic. Moving beyond regret, we show that a strategic seller cannot exploit our algorithms to extract more revenue on average than is possible under the optimal mechanism, i.e., the seller cannot do much better than posting the monopoly reserve price in each auction. Finally, we prove that our algorithm is also incentive compatible -- it is a (nearly) dominant strategy for the buyer to report her values truthfully to the algorithm as a whole.
Robust Budget Pacing with a Single Sample
Feb 03, 2023Major Internet advertising platforms offer budget pacing tools as a standard service for advertisers to manage their ad campaigns. Given the inherent non-stationarity in an advertiser's value and also competing advertisers' values over time, a commonly used approach is to learn a target expenditure plan that specifies a target spend as a function of time, and then run a controller that tracks this plan. This raises the question: how many historical samples are required to learn a good expenditure plan? We study this question by considering an advertiser repeatedly participating in $T$ second-price auctions, where the tuple of her value and the highest competing bid is drawn from an unknown time-varying distribution. The advertiser seeks to maximize her total utility subject to her budget constraint. Prior work has shown the sufficiency of $T\log T$ samples per distribution to achieve the optimal $O(\sqrt{T})$-regret. We dramatically improve this state-of-the-art and show that just one sample per distribution is enough to achieve the near-optimal $\tilde O(\sqrt{T})$-regret, while still being robust to noise in the sampling distributions.
Online Resource Allocation under Horizon Uncertainty
Jun 27, 2022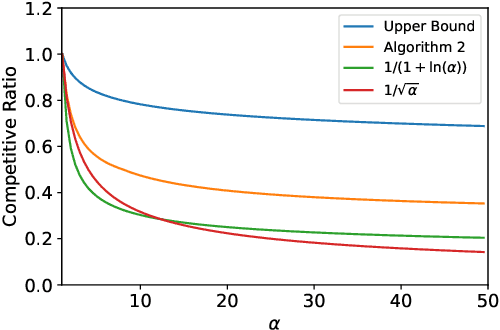
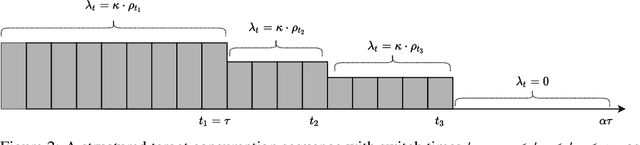
We study stochastic online resource allocation: a decision maker needs to allocate limited resources to stochastically-generated sequentially-arriving requests in order to maximize reward. Motivated by practice, we consider a data-driven setting in which requests are drawn independently from a distribution that is unknown to the decision maker. Online resource allocation and its special cases have been studied extensively in the past, but these previous results crucially and universally rely on a practically-untenable assumption: the total number of requests (the horizon) is known to the decision maker in advance. In many applications, such as revenue management and online advertising, the number of requests can vary widely because of fluctuations in demand or user traffic intensity. In this work, we develop online algorithms that are robust to horizon uncertainty. In sharp contrast to the known-horizon setting, we show that no algorithm can achieve a constant asymptotic competitive ratio that is independent of the horizon uncertainty. We then introduce a novel algorithm that combines dual mirror descent with a carefully-chosen target consumption sequence and prove that it achieves a bounded competitive ratio. Our algorithm is near-optimal in the sense that its competitive ratio attains the optimal rate of growth when the horizon uncertainty grows large.
Single-Leg Revenue Management with Advice
Feb 18, 2022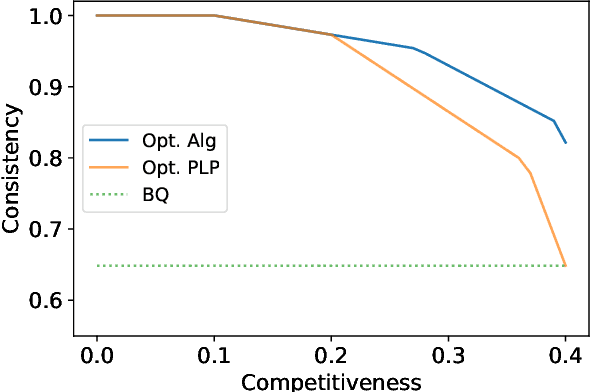
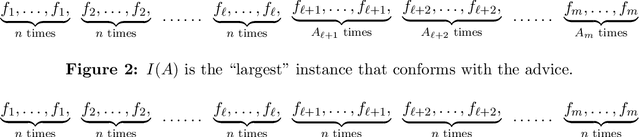
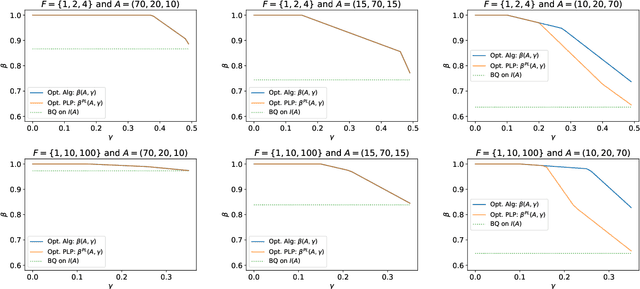
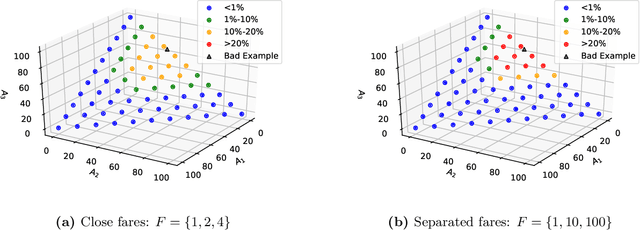
Single-leg revenue management is a foundational problem of revenue management that has been particularly impactful in the airline and hotel industry: Given $n$ units of a resource, e.g. flight seats, and a stream of sequentially-arriving customers segmented by fares, what is the optimal online policy for allocating the resource. Previous work focused on designing algorithms when forecasts are available, which are not robust to inaccuracies in the forecast, or online algorithms with worst-case performance guarantees, which can be too conservative in practice. In this work, we look at the single-leg revenue management problem through the lens of the algorithms-with-advice framework, which attempts to optimally incorporate advice/predictions about the future into online algorithms. In particular, we characterize the Pareto frontier that captures the tradeoff between consistency (performance when advice is accurate) and competitiveness (performance when advice is inaccurate) for every advice. Moreover, we provide an online algorithm that always achieves performance on this Pareto frontier. We also study the class of protection level policies, which is the most widely-deployed technique for single-leg revenue management: we provide an algorithm to incorporate advice into protection levels that optimally trades off consistency and competitiveness. Moreover, we empirically evaluate the performance of these algorithms on synthetic data. We find that our algorithm for protection level policies performs remarkably well on most instances, even if it is not guaranteed to be on the Pareto frontier in theory.