 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwap Regret Minimization Through Response-Based Approachability
Feb 05, 2026We consider the problem of minimizing different notions of swap regret in online optimization. These forms of regret are tightly connected to correlated equilibrium concepts in games, and have been more recently shown to guarantee non-manipulability against strategic adversaries. The only computationally efficient algorithm for minimizing linear swap regret over a general convex set in $\mathbb{R}^d$ was developed recently by Daskalakis, Farina, Fishelson, Pipis, and Schneider (STOC '25). However, it incurs a highly suboptimal regret bound of $Ω(d^4 \sqrt{T})$ and also relies on computationally intensive calls to the ellipsoid algorithm at each iteration. In this paper, we develop a significantly simpler, computationally efficient algorithm that guarantees $O(d^{3/2} \sqrt{T})$ linear swap regret for a general convex set and $O(d \sqrt{T})$ when the set is centrally symmetric. Our approach leverages the powerful response-based approachability framework of Bernstein and Shimkin (JMLR '15) -- previously overlooked in the line of work on swap regret minimization -- combined with geometric preconditioning via the John ellipsoid. Our algorithm simultaneously minimizes profile swap regret, which was recently shown to guarantee non-manipulability. Moreover, we establish a matching information-theoretic lower bound: any learner must incur in expectation $Ω(d \sqrt{T})$ linear swap regret for large enough $T$, even when the set is centrally symmetric. This also shows that the classic algorithm of Gordon, Greenwald, and Marks (ICML '08) is existentially optimal for minimizing linear swap regret, although it is computationally inefficient. Finally, we extend our approach to minimize regret with respect to the set of swap deviations with polynomial dimension, unifying and strengthening recent results in equilibrium computation and online learning.
High-Dimensional Calibration from Swap Regret
May 27, 2025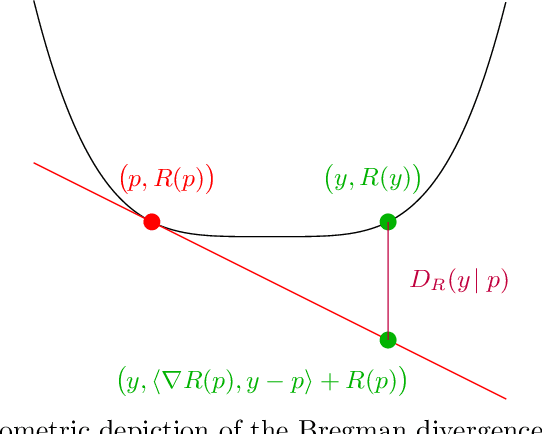

We study the online calibration of multi-dimensional forecasts over an arbitrary convex set $\mathcal{P} \subset \mathbb{R}^d$ relative to an arbitrary norm $\Vert\cdot\Vert$. We connect this with the problem of external regret minimization for online linear optimization, showing that if it is possible to guarantee $O(\sqrt{\rho T})$ worst-case regret after $T$ rounds when actions are drawn from $\mathcal{P}$ and losses are drawn from the dual $\Vert \cdot \Vert_*$ unit norm ball, then it is also possible to obtain $\epsilon$-calibrated forecasts after $T = \exp(O(\rho /\epsilon^2))$ rounds. When $\mathcal{P}$ is the $d$-dimensional simplex and $\Vert \cdot \Vert$ is the $\ell_1$-norm, the existence of $O(\sqrt{T\log d})$-regret algorithms for learning with experts implies that it is possible to obtain $\epsilon$-calibrated forecasts after $T = \exp(O(\log{d}/\epsilon^2)) = d^{O(1/\epsilon^2)}$ rounds, recovering a recent result of Peng (2025). Interestingly, our algorithm obtains this guarantee without requiring access to any online linear optimization subroutine or knowledge of the optimal rate $\rho$ -- in fact, our algorithm is identical for every setting of $\mathcal{P}$ and $\Vert \cdot \Vert$. Instead, we show that the optimal regularizer for the above OLO problem can be used to upper bound the above calibration error by a swap regret, which we then minimize by running the recent TreeSwap algorithm with Follow-The-Leader as a subroutine. Finally, we prove that any online calibration algorithm that guarantees $\epsilon T$ $\ell_1$-calibration error over the $d$-dimensional simplex requires $T \geq \exp(\mathrm{poly}(1/\epsilon))$ (assuming $d \geq \mathrm{poly}(1/\epsilon)$). This strengthens the corresponding $d^{\Omega(\log{1/\epsilon})}$ lower bound of Peng, and shows that an exponential dependence on $1/\epsilon$ is necessary.
Full Swap Regret and Discretized Calibration
Feb 13, 2025We study the problem of minimizing swap regret in structured normal-form games. Players have a very large (potentially infinite) number of pure actions, but each action has an embedding into $d$-dimensional space and payoffs are given by bilinear functions of these embeddings. We provide an efficient learning algorithm for this setting that incurs at most $\tilde{O}(T^{(d+1)/(d+3)})$ swap regret after $T$ rounds. To achieve this, we introduce a new online learning problem we call \emph{full swap regret minimization}. In this problem, a learner repeatedly takes a (randomized) action in a bounded convex $d$-dimensional action set $\mathcal{K}$ and then receives a loss from the adversary, with the goal of minimizing their regret with respect to the \emph{worst-case} swap function mapping $\mathcal{K}$ to $\mathcal{K}$. For varied assumptions about the convexity and smoothness of the loss functions, we design algorithms with full swap regret bounds ranging from $O(T^{d/(d+2)})$ to $O(T^{(d+1)/(d+2)})$. Finally, we apply these tools to the problem of online forecasting to minimize calibration error, showing that several notions of calibration can be viewed as specific instances of full swap regret. In particular, we design efficient algorithms for online forecasting that guarantee at most $O(T^{1/3})$ $\ell_2$-calibration error and $O(\max(\sqrt{\epsilon T}, T^{1/3}))$ \emph{discretized-calibration} error (when the forecaster is restricted to predicting multiples of $\epsilon$).
Improved bounds for calibration via stronger sign preservation games
Jun 19, 2024A set of probabilistic forecasts is calibrated if each prediction of the forecaster closely approximates the empirical distribution of outcomes on the subset of timesteps where that prediction was made. We study the fundamental problem of online calibrated forecasting of binary sequences, which was initially studied by Foster & Vohra (1998). They derived an algorithm with $O(T^{2/3})$ calibration error after $T$ time steps, and showed a lower bound of $\Omega(T^{1/2})$. These bounds remained stagnant for two decades, until Qiao & Valiant (2021) improved the lower bound to $\Omega(T^{0.528})$ by introducing a combinatorial game called sign preservation and showing that lower bounds for this game imply lower bounds for calibration. We introduce a strengthening of Qiao & Valiant's game that we call sign preservation with reuse (SPR). We prove that the relationship between SPR and calibrated forecasting is bidirectional: not only do lower bounds for SPR translate into lower bounds for calibration, but algorithms for SPR also translate into new algorithms for calibrated forecasting. In particular, any strategy that improves the trivial upper bound for the value of the SPR game would imply a forecasting algorithm with calibration error exponent less than 2/3, improving Foster & Vohra's upper bound for the first time. Using similar ideas, we then prove a slightly stronger lower bound than that of Qiao & Valiant, namely $\Omega(T^{0.54389})$. Our lower bound is obtained by an oblivious adversary, marking the first $\omega(T^{1/2})$ calibration lower bound for oblivious adversaries.
From External to Swap Regret 2.0: An Efficient Reduction and Oblivious Adversary for Large Action Spaces
Oct 31, 2023We provide a novel reduction from swap-regret minimization to external-regret minimization, which improves upon the classical reductions of Blum-Mansour [BM07] and Stolz-Lugosi [SL05] in that it does not require finiteness of the space of actions. We show that, whenever there exists a no-external-regret algorithm for some hypothesis class, there must also exist a no-swap-regret algorithm for that same class. For the problem of learning with expert advice, our result implies that it is possible to guarantee that the swap regret is bounded by {\epsilon} after $\log(N)^{O(1/\epsilon)}$ rounds and with $O(N)$ per iteration complexity, where $N$ is the number of experts, while the classical reductions of Blum-Mansour and Stolz-Lugosi require $O(N/\epsilon^2)$ rounds and at least $\Omega(N^2)$ per iteration complexity. Our result comes with an associated lower bound, which -- in contrast to that in [BM07] -- holds for oblivious and $\ell_1$-constrained adversaries and learners that can employ distributions over experts, showing that the number of rounds must be $\tilde\Omega(N/\epsilon^2)$ or exponential in $1/\epsilon$. Our reduction implies that, if no-regret learning is possible in some game, then this game must have approximate correlated equilibria, of arbitrarily good approximation. This strengthens the folklore implication of no-regret learning that approximate coarse correlated equilibria exist. Importantly, it provides a sufficient condition for the existence of correlated equilibrium which vastly extends the requirement that the action set is finite, thus answering a question left open by [DG22; Ass+23]. Moreover, it answers several outstanding questions about equilibrium computation and/or learning in games.
Online Learning and Solving Infinite Games with an ERM Oracle
Jul 10, 2023

While ERM suffices to attain near-optimal generalization error in the stochastic learning setting, this is not known to be the case in the online learning setting, where algorithms for general concept classes rely on computationally inefficient oracles such as the Standard Optimal Algorithm (SOA). In this work, we propose an algorithm for online binary classification setting that relies solely on ERM oracle calls, and show that it has finite regret in the realizable setting and sublinearly growing regret in the agnostic setting. We bound the regret in terms of the Littlestone and threshold dimensions of the underlying concept class. We obtain similar results for nonparametric games, where the ERM oracle can be interpreted as a best response oracle, finding the best response of a player to a given history of play of the other players. In this setting, we provide learning algorithms that only rely on best response oracles and converge to approximate-minimax equilibria in two-player zero-sum games and approximate coarse correlated equilibria in multi-player general-sum games, as long as the game has a bounded fat-threshold dimension. Our algorithms apply to both binary-valued and real-valued games and can be viewed as providing justification for the wide use of double oracle and multiple oracle algorithms in the practice of solving large games.
Near-Optimal No-Regret Learning for Correlated Equilibria in Multi-Player General-Sum Games
Nov 11, 2021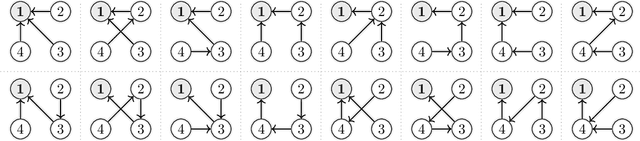

Recently, Daskalakis, Fishelson, and Golowich (DFG) (NeurIPS`21) showed that if all agents in a multi-player general-sum normal-form game employ Optimistic Multiplicative Weights Update (OMWU), the external regret of every player is $O(\textrm{polylog}(T))$ after $T$ repetitions of the game. We extend their result from external regret to internal regret and swap regret, thereby establishing uncoupled learning dynamics that converge to an approximate correlated equilibrium at the rate of $\tilde{O}(T^{-1})$. This substantially improves over the prior best rate of convergence for correlated equilibria of $O(T^{-3/4})$ due to Chen and Peng (NeurIPS`20), and it is optimal -- within the no-regret framework -- up to polylogarithmic factors in $T$. To obtain these results, we develop new techniques for establishing higher-order smoothness for learning dynamics involving fixed point operations. Specifically, we establish that the no-internal-regret learning dynamics of Stoltz and Lugosi (Mach Learn`05) are equivalently simulated by no-external-regret dynamics on a combinatorial space. This allows us to trade the computation of the stationary distribution on a polynomial-sized Markov chain for a (much more well-behaved) linear transformation on an exponential-sized set, enabling us to leverage similar techniques as DGF to near-optimally bound the internal regret. Moreover, we establish an $O(\textrm{polylog}(T))$ no-swap-regret bound for the classic algorithm of Blum and Mansour (BM) (JMLR`07). We do so by introducing a technique based on the Cauchy Integral Formula that circumvents the more limited combinatorial arguments of DFG. In addition to shedding clarity on the near-optimal regret guarantees of BM, our arguments provide insights into the various ways in which the techniques by DFG can be extended and leveraged in the analysis of more involved learning algorithms.
Near-Optimal No-Regret Learning in General Games
Aug 16, 2021
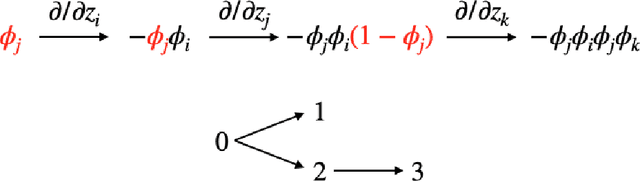
We show that Optimistic Hedge -- a common variant of multiplicative-weights-updates with recency bias -- attains ${\rm poly}(\log T)$ regret in multi-player general-sum games. In particular, when every player of the game uses Optimistic Hedge to iteratively update her strategy in response to the history of play so far, then after $T$ rounds of interaction, each player experiences total regret that is ${\rm poly}(\log T)$. Our bound improves, exponentially, the $O({T}^{1/2})$ regret attainable by standard no-regret learners in games, the $O(T^{1/4})$ regret attainable by no-regret learners with recency bias (Syrgkanis et al., 2015), and the ${O}(T^{1/6})$ bound that was recently shown for Optimistic Hedge in the special case of two-player games (Chen & Pen, 2020). A corollary of our bound is that Optimistic Hedge converges to coarse correlated equilibrium in general games at a rate of $\tilde{O}\left(\frac 1T\right)$.