 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Local Stackelberg Equilibria from Repeated Interactions with a Learning Agent
Oct 26, 2025Motivated by the question of how a principal can maximize its utility in repeated interactions with a learning agent, we study repeated games between an principal and an agent employing a mean-based learning algorithm. Prior work has shown that computing or even approximating the global Stackelberg value in similar settings can require an exponential number of rounds in the size of the agent's action space, making it computationally intractable. In contrast, we shift focus to the computation of local Stackelberg equilibria and introduce an algorithm that, within the smoothed analysis framework, constitutes a Polynomial Time Approximation Scheme (PTAS) for finding an epsilon-approximate local Stackelberg equilibrium. Notably, the algorithm's runtime is polynomial in the size of the agent's action space yet exponential in (1/epsilon) - a dependency we prove to be unavoidable.
Computational Intractability of Strategizing against Online Learners
Mar 06, 2025Online learning algorithms are widely used in strategic multi-agent settings, including repeated auctions, contract design, and pricing competitions, where agents adapt their strategies over time. A key question in such environments is how an optimizing agent can best respond to a learning agent to improve its own long-term outcomes. While prior work has developed efficient algorithms for the optimizer in special cases - such as structured auction settings or contract design - no general efficient algorithm is known. In this paper, we establish a strong computational hardness result: unless $\mathsf{P} = \mathsf{NP}$, no polynomial-time optimizer can compute a near-optimal strategy against a learner using a standard no-regret algorithm, specifically Multiplicative Weights Update (MWU). Our result proves an $\Omega(T)$ hardness bound, significantly strengthening previous work that only showed an additive $\Theta(1)$ impossibility result. Furthermore, while the prior hardness result focused on learners using fictitious play - an algorithm that is not no-regret - we prove intractability for a widely used no-regret learning algorithm. This establishes a fundamental computational barrier to finding optimal strategies in general game-theoretic settings.
Fixed Point Computation: Beating Brute Force with Smoothed Analysis
Jan 18, 2025We propose a new algorithm that finds an $\varepsilon$-approximate fixed point of a smooth function from the $n$-dimensional $\ell_2$ unit ball to itself. We use the general framework of finding approximate solutions to a variational inequality, a problem that subsumes fixed point computation and the computation of a Nash Equilibrium. The algorithm's runtime is bounded by $e^{O(n)}/\varepsilon$, under the smoothed-analysis framework. This is the first known algorithm in such a generality whose runtime is faster than $(1/\varepsilon)^{O(n)}$, which is a time that suffices for an exhaustive search. We complement this result with a lower bound of $e^{\Omega(n)}$ on the query complexity for finding an $O(1)$-approximate fixed point on the unit ball, which holds even in the smoothed-analysis model, yet without the assumption that the function is smooth. Existing lower bounds are only known for the hypercube, and adapting them to the ball does not give non-trivial results even for finding $O(1/\sqrt{n})$-approximate fixed points.
Dimension-free Private Mean Estimation for Anisotropic Distributions
Nov 01, 2024We present differentially private algorithms for high-dimensional mean estimation. Previous private estimators on distributions over $\mathbb{R}^d$ suffer from a curse of dimensionality, as they require $\Omega(d^{1/2})$ samples to achieve non-trivial error, even in cases where $O(1)$ samples suffice without privacy. This rate is unavoidable when the distribution is isotropic, namely, when the covariance is a multiple of the identity matrix, or when accuracy is measured with respect to the affine-invariant Mahalanobis distance. Yet, real-world data is often highly anisotropic, with signals concentrated on a small number of principal components. We develop estimators that are appropriate for such signals$\unicode{x2013}$our estimators are $(\varepsilon,\delta)$-differentially private and have sample complexity that is dimension-independent for anisotropic subgaussian distributions. Given $n$ samples from a distribution with known covariance-proxy $\Sigma$ and unknown mean $\mu$, we present an estimator $\hat{\mu}$ that achieves error $\|\hat{\mu}-\mu\|_2\leq \alpha$, as long as $n\gtrsim\mathrm{tr}(\Sigma)/\alpha^2+ \mathrm{tr}(\Sigma^{1/2})/(\alpha\varepsilon)$. In particular, when $\pmb{\sigma}^2=(\sigma_1^2, \ldots, \sigma_d^2)$ are the singular values of $\Sigma$, we have $\mathrm{tr}(\Sigma)=\|\pmb{\sigma}\|_2^2$ and $\mathrm{tr}(\Sigma^{1/2})=\|\pmb{\sigma}\|_1$, and hence our bound avoids dimension-dependence when the signal is concentrated in a few principal components. We show that this is the optimal sample complexity for this task up to logarithmic factors. Moreover, for the case of unknown covariance, we present an algorithm whose sample complexity has improved dependence on the dimension, from $d^{1/2}$ to $d^{1/4}$.
Maximizing utility in multi-agent environments by anticipating the behavior of other learners
Jul 05, 2024
Learning algorithms are often used to make decisions in sequential decision-making environments. In multi-agent settings, the decisions of each agent can affect the utilities/losses of the other agents. Therefore, if an agent is good at anticipating the behavior of the other agents, in particular how they will make decisions in each round as a function of their experience that far, it could try to judiciously make its own decisions over the rounds of the interaction so as to influence the other agents to behave in a way that ultimately benefits its own utility. In this paper, we study repeated two-player games involving two types of agents: a learner, which employs an online learning algorithm to choose its strategy in each round; and an optimizer, which knows the learner's utility function and the learner's online learning algorithm. The optimizer wants to plan ahead to maximize its own utility, while taking into account the learner's behavior. We provide two results: a positive result for repeated zero-sum games and a negative result for repeated general-sum games. Our positive result is an algorithm for the optimizer, which exactly maximizes its utility against a learner that plays the Replicator Dynamics -- the continuous-time analogue of Multiplicative Weights Update (MWU). Additionally, we use this result to provide an algorithm for the optimizer against MWU, i.e.~for the discrete-time setting, which guarantees an average utility for the optimizer that is higher than the value of the one-shot game. Our negative result shows that, unless P=NP, there is no Fully Polynomial Time Approximation Scheme (FPTAS) for maximizing the utility of an optimizer against a learner that best-responds to the history in each round. Yet, this still leaves open the question of whether there exists a polynomial-time algorithm that optimizes the utility up to $o(T)$.
Improved bounds for calibration via stronger sign preservation games
Jun 19, 2024A set of probabilistic forecasts is calibrated if each prediction of the forecaster closely approximates the empirical distribution of outcomes on the subset of timesteps where that prediction was made. We study the fundamental problem of online calibrated forecasting of binary sequences, which was initially studied by Foster & Vohra (1998). They derived an algorithm with $O(T^{2/3})$ calibration error after $T$ time steps, and showed a lower bound of $\Omega(T^{1/2})$. These bounds remained stagnant for two decades, until Qiao & Valiant (2021) improved the lower bound to $\Omega(T^{0.528})$ by introducing a combinatorial game called sign preservation and showing that lower bounds for this game imply lower bounds for calibration. We introduce a strengthening of Qiao & Valiant's game that we call sign preservation with reuse (SPR). We prove that the relationship between SPR and calibrated forecasting is bidirectional: not only do lower bounds for SPR translate into lower bounds for calibration, but algorithms for SPR also translate into new algorithms for calibrated forecasting. In particular, any strategy that improves the trivial upper bound for the value of the SPR game would imply a forecasting algorithm with calibration error exponent less than 2/3, improving Foster & Vohra's upper bound for the first time. Using similar ideas, we then prove a slightly stronger lower bound than that of Qiao & Valiant, namely $\Omega(T^{0.54389})$. Our lower bound is obtained by an oblivious adversary, marking the first $\omega(T^{1/2})$ calibration lower bound for oblivious adversaries.
From External to Swap Regret 2.0: An Efficient Reduction and Oblivious Adversary for Large Action Spaces
Oct 31, 2023We provide a novel reduction from swap-regret minimization to external-regret minimization, which improves upon the classical reductions of Blum-Mansour [BM07] and Stolz-Lugosi [SL05] in that it does not require finiteness of the space of actions. We show that, whenever there exists a no-external-regret algorithm for some hypothesis class, there must also exist a no-swap-regret algorithm for that same class. For the problem of learning with expert advice, our result implies that it is possible to guarantee that the swap regret is bounded by {\epsilon} after $\log(N)^{O(1/\epsilon)}$ rounds and with $O(N)$ per iteration complexity, where $N$ is the number of experts, while the classical reductions of Blum-Mansour and Stolz-Lugosi require $O(N/\epsilon^2)$ rounds and at least $\Omega(N^2)$ per iteration complexity. Our result comes with an associated lower bound, which -- in contrast to that in [BM07] -- holds for oblivious and $\ell_1$-constrained adversaries and learners that can employ distributions over experts, showing that the number of rounds must be $\tilde\Omega(N/\epsilon^2)$ or exponential in $1/\epsilon$. Our reduction implies that, if no-regret learning is possible in some game, then this game must have approximate correlated equilibria, of arbitrarily good approximation. This strengthens the folklore implication of no-regret learning that approximate coarse correlated equilibria exist. Importantly, it provides a sufficient condition for the existence of correlated equilibrium which vastly extends the requirement that the action set is finite, thus answering a question left open by [DG22; Ass+23]. Moreover, it answers several outstanding questions about equilibrium computation and/or learning in games.
Online Learning and Solving Infinite Games with an ERM Oracle
Jul 10, 2023

While ERM suffices to attain near-optimal generalization error in the stochastic learning setting, this is not known to be the case in the online learning setting, where algorithms for general concept classes rely on computationally inefficient oracles such as the Standard Optimal Algorithm (SOA). In this work, we propose an algorithm for online binary classification setting that relies solely on ERM oracle calls, and show that it has finite regret in the realizable setting and sublinearly growing regret in the agnostic setting. We bound the regret in terms of the Littlestone and threshold dimensions of the underlying concept class. We obtain similar results for nonparametric games, where the ERM oracle can be interpreted as a best response oracle, finding the best response of a player to a given history of play of the other players. In this setting, we provide learning algorithms that only rely on best response oracles and converge to approximate-minimax equilibria in two-player zero-sum games and approximate coarse correlated equilibria in multi-player general-sum games, as long as the game has a bounded fat-threshold dimension. Our algorithms apply to both binary-valued and real-valued games and can be viewed as providing justification for the wide use of double oracle and multiple oracle algorithms in the practice of solving large games.
Ambient Diffusion: Learning Clean Distributions from Corrupted Data
May 30, 2023



We present the first diffusion-based framework that can learn an unknown distribution using only highly-corrupted samples. This problem arises in scientific applications where access to uncorrupted samples is impossible or expensive to acquire. Another benefit of our approach is the ability to train generative models that are less likely to memorize individual training samples since they never observe clean training data. Our main idea is to introduce additional measurement distortion during the diffusion process and require the model to predict the original corrupted image from the further corrupted image. We prove that our method leads to models that learn the conditional expectation of the full uncorrupted image given this additional measurement corruption. This holds for any corruption process that satisfies some technical conditions (and in particular includes inpainting and compressed sensing). We train models on standard benchmarks (CelebA, CIFAR-10 and AFHQ) and show that we can learn the distribution even when all the training samples have $90\%$ of their pixels missing. We also show that we can finetune foundation models on small corrupted datasets (e.g. MRI scans with block corruptions) and learn the clean distribution without memorizing the training set.
Consistent Diffusion Models: Mitigating Sampling Drift by Learning to be Consistent
Feb 17, 2023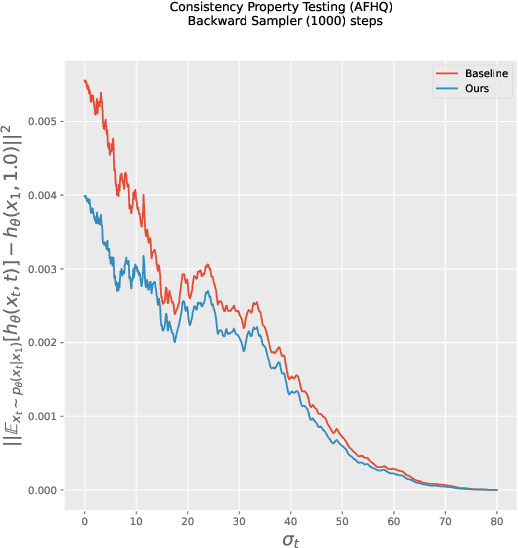
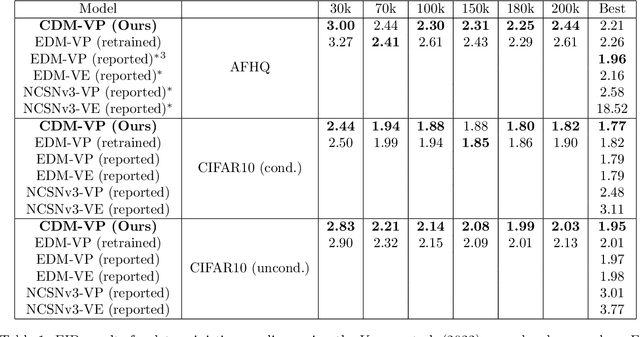


Imperfect score-matching leads to a shift between the training and the sampling distribution of diffusion models. Due to the recursive nature of the generation process, errors in previous steps yield sampling iterates that drift away from the training distribution. Yet, the standard training objective via Denoising Score Matching (DSM) is only designed to optimize over non-drifted data. To train on drifted data, we propose to enforce a \emph{consistency} property which states that predictions of the model on its own generated data are consistent across time. Theoretically, we show that if the score is learned perfectly on some non-drifted points (via DSM) and if the consistency property is enforced everywhere, then the score is learned accurately everywhere. Empirically we show that our novel training objective yields state-of-the-art results for conditional and unconditional generation in CIFAR-10 and baseline improvements in AFHQ and FFHQ. We open-source our code and models: https://github.com/giannisdaras/cdm