 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbient Dataloops: Generative Models for Dataset Refinement
Jan 21, 2026We propose Ambient Dataloops, an iterative framework for refining datasets that makes it easier for diffusion models to learn the underlying data distribution. Modern datasets contain samples of highly varying quality, and training directly on such heterogeneous data often yields suboptimal models. We propose a dataset-model co-evolution process; at each iteration of our method, the dataset becomes progressively higher quality, and the model improves accordingly. To avoid destructive self-consuming loops, at each generation, we treat the synthetically improved samples as noisy, but at a slightly lower noisy level than the previous iteration, and we use Ambient Diffusion techniques for learning under corruption. Empirically, Ambient Dataloops achieve state-of-the-art performance in unconditional and text-conditional image generation and de novo protein design. We further provide a theoretical justification for the proposed framework that captures the benefits of the data looping procedure.
Ambient Diffusion Omni: Training Good Models with Bad Data
Jun 10, 2025We show how to use low-quality, synthetic, and out-of-distribution images to improve the quality of a diffusion model. Typically, diffusion models are trained on curated datasets that emerge from highly filtered data pools from the Web and other sources. We show that there is immense value in the lower-quality images that are often discarded. We present Ambient Diffusion Omni, a simple, principled framework to train diffusion models that can extract signal from all available images during training. Our framework exploits two properties of natural images -- spectral power law decay and locality. We first validate our framework by successfully training diffusion models with images synthetically corrupted by Gaussian blur, JPEG compression, and motion blur. We then use our framework to achieve state-of-the-art ImageNet FID, and we show significant improvements in both image quality and diversity for text-to-image generative modeling. The core insight is that noise dampens the initial skew between the desired high-quality distribution and the mixed distribution we actually observe. We provide rigorous theoretical justification for our approach by analyzing the trade-off between learning from biased data versus limited unbiased data across diffusion times.
Learning the Sherrington-Kirkpatrick Model Even at Low Temperature
Nov 17, 2024We consider the fundamental problem of learning the parameters of an undirected graphical model or Markov Random Field (MRF) in the setting where the edge weights are chosen at random. For Ising models, we show that a multiplicative-weight update algorithm due to Klivans and Meka learns the parameters in polynomial time for any inverse temperature $\beta \leq \sqrt{\log n}$. This immediately yields an algorithm for learning the Sherrington-Kirkpatrick (SK) model beyond the high-temperature regime of $\beta < 1$. Prior work breaks down at $\beta = 1$ and requires heavy machinery from statistical physics or functional inequalities. In contrast, our analysis is relatively simple and uses only subgaussian concentration. Our results extend to MRFs of higher order (such as pure $p$-spin models), where even results in the high-temperature regime were not known.
Smoothed Analysis for Learning Concepts with Low Intrinsic Dimension
Jul 01, 2024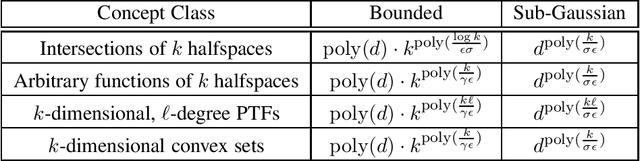
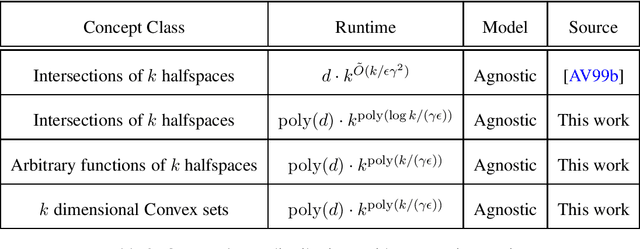

In traditional models of supervised learning, the goal of a learner -- given examples from an arbitrary joint distribution on $\mathbb{R}^d \times \{\pm 1\}$ -- is to output a hypothesis that is competitive (to within $\epsilon$) of the best fitting concept from some class. In order to escape strong hardness results for learning even simple concept classes, we introduce a smoothed-analysis framework that requires a learner to compete only with the best classifier that is robust to small random Gaussian perturbation. This subtle change allows us to give a wide array of learning results for any concept that (1) depends on a low-dimensional subspace (aka multi-index model) and (2) has a bounded Gaussian surface area. This class includes functions of halfspaces and (low-dimensional) convex sets, cases that are only known to be learnable in non-smoothed settings with respect to highly structured distributions such as Gaussians. Surprisingly, our analysis also yields new results for traditional non-smoothed frameworks such as learning with margin. In particular, we obtain the first algorithm for agnostically learning intersections of $k$-halfspaces in time $k^{poly(\frac{\log k}{\epsilon \gamma}) }$ where $\gamma$ is the margin parameter. Before our work, the best-known runtime was exponential in $k$ (Arriaga and Vempala, 1999).
Learning Mixtures of Gaussians Using the DDPM Objective
Jul 03, 2023Recent works have shown that diffusion models can learn essentially any distribution provided one can perform score estimation. Yet it remains poorly understood under what settings score estimation is possible, let alone when practical gradient-based algorithms for this task can provably succeed. In this work, we give the first provably efficient results along these lines for one of the most fundamental distribution families, Gaussian mixture models. We prove that gradient descent on the denoising diffusion probabilistic model (DDPM) objective can efficiently recover the ground truth parameters of the mixture model in the following two settings: 1) We show gradient descent with random initialization learns mixtures of two spherical Gaussians in $d$ dimensions with $1/\text{poly}(d)$-separated centers. 2) We show gradient descent with a warm start learns mixtures of $K$ spherical Gaussians with $\Omega(\sqrt{\log(\min(K,d))})$-separated centers. A key ingredient in our proofs is a new connection between score-based methods and two other approaches to distribution learning, the EM algorithm and spectral methods.
One-Dimensional Deep Image Prior for Curve Fitting of S-Parameters from Electromagnetic Solvers
Jun 06, 2023A key problem when modeling signal integrity for passive filters and interconnects in IC packages is the need for multiple S-parameter measurements within a desired frequency band to obtain adequate resolution. These samples are often computationally expensive to obtain using electromagnetic (EM) field solvers. Therefore, a common approach is to select a small subset of the necessary samples and use an appropriate fitting mechanism to recreate a densely-sampled broadband representation. We present the first deep generative model-based approach to fit S-parameters from EM solvers using one-dimensional Deep Image Prior (DIP). DIP is a technique that optimizes the weights of a randomly-initialized convolutional neural network to fit a signal from noisy or under-determined measurements. We design a custom architecture and propose a novel regularization inspired by smoothing splines that penalizes discontinuous jumps. We experimentally compare DIP to publicly available and proprietary industrial implementations of Vector Fitting (VF), the industry-standard tool for fitting S-parameters. Relative to publicly available implementations of VF, our method shows superior performance on nearly all test examples using only 5-15% of the frequency samples. Our method is also competitive to proprietary VF tools and often outperforms them for challenging input instances.
Ambient Diffusion: Learning Clean Distributions from Corrupted Data
May 30, 2023



We present the first diffusion-based framework that can learn an unknown distribution using only highly-corrupted samples. This problem arises in scientific applications where access to uncorrupted samples is impossible or expensive to acquire. Another benefit of our approach is the ability to train generative models that are less likely to memorize individual training samples since they never observe clean training data. Our main idea is to introduce additional measurement distortion during the diffusion process and require the model to predict the original corrupted image from the further corrupted image. We prove that our method leads to models that learn the conditional expectation of the full uncorrupted image given this additional measurement corruption. This holds for any corruption process that satisfies some technical conditions (and in particular includes inpainting and compressed sensing). We train models on standard benchmarks (CelebA, CIFAR-10 and AFHQ) and show that we can learn the distribution even when all the training samples have $90\%$ of their pixels missing. We also show that we can finetune foundation models on small corrupted datasets (e.g. MRI scans with block corruptions) and learn the clean distribution without memorizing the training set.
Tight Hardness Results for Training Depth-2 ReLU Networks
Nov 27, 2020We prove several hardness results for training depth-2 neural networks with the ReLU activation function; these networks are simply weighted sums (that may include negative coefficients) of ReLUs. Our goal is to output a depth-2 neural network that minimizes the square loss with respect to a given training set. We prove that this problem is NP-hard already for a network with a single ReLU. We also prove NP-hardness for outputting a weighted sum of $k$ ReLUs minimizing the squared error (for $k>1$) even in the realizable setting (i.e., when the labels are consistent with an unknown depth-2 ReLU network). We are also able to obtain lower bounds on the running time in terms of the desired additive error $\epsilon$. To obtain our lower bounds, we use the Gap Exponential Time Hypothesis (Gap-ETH) as well as a new hypothesis regarding the hardness of approximating the well known Densest $\kappa$-Subgraph problem in subexponential time (these hypotheses are used separately in proving different lower bounds). For example, we prove that under reasonable hardness assumptions, any proper learning algorithm for finding the best fitting ReLU must run in time exponential in $1/\epsilon^2$. Together with a previous work regarding improperly learning a ReLU (Goel et al., COLT'17), this implies the first separation between proper and improper algorithms for learning a ReLU. We also study the problem of properly learning a depth-2 network of ReLUs with bounded weights giving new (worst-case) upper bounds on the running time needed to learn such networks both in the realizable and agnostic settings. Our upper bounds on the running time essentially matches our lower bounds in terms of the dependency on $\epsilon$.
The Polynomial Method is Universal for Distribution-Free Correlational SQ Learning
Oct 29, 2020We consider the problem of distribution-free learning for Boolean function classes in the PAC and agnostic models. Generalizing a recent beautiful work of Malach and Shalev-Shwartz (2020) who gave the first tight correlational SQ (CSQ) lower bounds for learning DNF formulas, we show that lower bounds on the threshold or approximate degree of any function class directly imply CSQ lower bounds for PAC or agnostic learning respectively. These match corresponding positive results using upper bounds on the threshold or approximate degree in the SQ model for PAC or agnostic learning. Many of these results were implicit in earlier works of Feldman and Sherstov.
From Boltzmann Machines to Neural Networks and Back Again
Jul 25, 2020



Graphical models are powerful tools for modeling high-dimensional data, but learning graphical models in the presence of latent variables is well-known to be difficult. In this work we give new results for learning Restricted Boltzmann Machines, probably the most well-studied class of latent variable models. Our results are based on new connections to learning two-layer neural networks under $\ell_{\infty}$ bounded input; for both problems, we give nearly optimal results under the conjectured hardness of sparse parity with noise. Using the connection between RBMs and feedforward networks, we also initiate the theoretical study of $supervised~RBMs$ [Hinton, 2012], a version of neural-network learning that couples distributional assumptions induced from the underlying graphical model with the architecture of the unknown function class. We then give an algorithm for learning a natural class of supervised RBMs with better runtime than what is possible for its related class of networks without distributional assumptions.