 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling by Value-Driven Transport
May 21, 2026We propose a new framework for generative modeling based on a discrete-time stochastic control formulation of measure transport. Adapting classic results from control theory, we formulate our problem as a linear program whose dual variables correspond to the \emph{optimal value function} of the control problem, which directly encodes the optimal control policy. Exploiting this LP formulation, we develop an efficient simulation-free primal-dual algorithm for computing approximately optimal value functions and the associated \emph{value-driven transport} (VDT) policies which approximate the true optimal policy. We show that well-trained VDT policies enjoy numerous favorable properties in comparison with other state-of-the-art methods based on flows, diffusions, or Schrödinger bridges: they lead to straight transport paths which can be simulated quickly and robustly, and can be enhanced in all the same ways as diffusion and flow-based models (e.g., conditional generation, classifier-free guidance, unpaired data-to-data translation are all easy to incorporate). We evaluate our methodology in a range of experiments, with results that indicate strong performance and good potential for scalability.
Support Before Frequency in Discrete Diffusion
May 13, 2026Discrete diffusion models are increasingly competitive for language modeling, yet it remains unclear how their denoising objectives organize learning. Although these objectives target the full data distribution, we show that the exact reverse process induces a hierarchy between coarse support information and finer frequency information. For uniform and absorbing (a.k.a. masking) diffusion, we prove that, in the small-noise regime of the final denoising steps, each single-token reverse edit decomposes into a leading scale, determined by whether it moves toward the data support (e.g., grammatically valid sentences), and a finer coefficient, determining relative probabilities within the same scale. Thus, recovering validity structure only requires learning the correct order of magnitude of reverse probabilities, whereas recovering data frequencies requires coefficient-level estimation. The separation is mechanism-dependent: uniform diffusion exhibits a trichotomy into validity-improving, validity-preserving, and validity-worsening edits, while absorbing diffusion places its leading-order mass on validity-improving moves. Experiments on a masked language diffusion model and synthetic regular-language tasks support these predictions: support-localization emerges earlier than within-support frequency ranking, and the contrast between uniform and absorbing diffusion matches the predicted rate separation. Together, our results suggest that discrete diffusion models learn data support before data frequencies.
Best of Both Worlds: Regret Minimization versus Minimax Play
Feb 17, 2025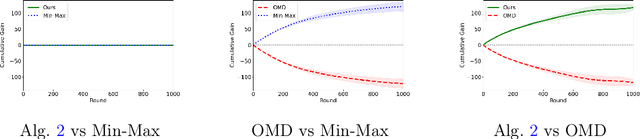


In this paper, we investigate the existence of online learning algorithms with bandit feedback that simultaneously guarantee $O(1)$ regret compared to a given comparator strategy, and $O(\sqrt{T})$ regret compared to the best strategy in hindsight, where $T$ is the number of rounds. We provide the first affirmative answer to this question. In the context of symmetric zero-sum games, both in normal- and extensive form, we show that our results allow us to guarantee to risk at most $O(1)$ loss while being able to gain $\Omega(T)$ from exploitable opponents, thereby combining the benefits of both no-regret algorithms and minimax play.
Truly No-Regret Learning in Constrained MDPs
Feb 24, 2024Constrained Markov decision processes (CMDPs) are a common way to model safety constraints in reinforcement learning. State-of-the-art methods for efficiently solving CMDPs are based on primal-dual algorithms. For these algorithms, all currently known regret bounds allow for error cancellations -- one can compensate for a constraint violation in one round with a strict constraint satisfaction in another. This makes the online learning process unsafe since it only guarantees safety for the final (mixture) policy but not during learning. As Efroni et al. (2020) pointed out, it is an open question whether primal-dual algorithms can provably achieve sublinear regret if we do not allow error cancellations. In this paper, we give the first affirmative answer. We first generalize a result on last-iterate convergence of regularized primal-dual schemes to CMDPs with multiple constraints. Building upon this insight, we propose a model-based primal-dual algorithm to learn in an unknown CMDP. We prove that our algorithm achieves sublinear regret without error cancellations.
Cancellation-Free Regret Bounds for Lagrangian Approaches in Constrained Markov Decision Processes
Jun 12, 2023
Constrained Markov Decision Processes (CMDPs) are one of the common ways to model safe reinforcement learning problems, where the safety objectives are modeled by constraint functions. Lagrangian-based dual or primal-dual algorithms provide efficient methods for learning in CMDPs. For these algorithms, the currently known regret bounds in the finite-horizon setting allow for a \textit{cancellation of errors}; that is, one can compensate for a constraint violation in one episode with a strict constraint satisfaction in another episode. However, in practical applications, we do not consider such a behavior safe. In this paper, we overcome this weakness by proposing a novel model-based dual algorithm \textsc{OptAug-CMDP} for tabular finite-horizon CMDPs. Our algorithm is motivated by the augmented Lagrangian method and can be performed efficiently. We show that during $K$ episodes of exploring the CMDP, our algorithm obtains a regret of $\tilde{O}(\sqrt{K})$ for both the objective and the constraint violation. Unlike existing Lagrangian approaches, our algorithm achieves this regret without the need for the cancellation of errors.