 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit the Differences, Pool the Rest: Provably Efficient Multi-Objective Imitation
May 12, 2026This work investigates multi-objective imitation learning: the problem of recovering policies that lie on the Pareto front given demonstrations from multiple Pareto-optimal experts in a Multi-Objective Markov Decision Process (MOMDP). Standard imitation approaches are ill-equipped for this regime, as naively aggregating conflicting expert trajectories can result in dominated policies. To address this, we introduce Multi-Output Augmented Behavioral Cloning (MA-BC), an algorithm that systematically partitions divergent expert data while pooling state-action pairs where no behavior conflict is observed. Theoretically, we prove that MA-BC converges to Pareto-optimal policies at a faster statistical rate than any learner that considers each expert dataset independently. Furthermore, we establish a novel lower bound for multi-objective imitation learning, demonstrating that MA-BC is minimax optimal. Finally, we empirically validate our algorithm across diverse discrete environments and, guided by our theoretical insights, extend and evaluate MA-BC on a continuous Linear Quadratic Regulator (LQR) control task.
Multi-agent imitation learning with function approximation: Linear Markov games and beyond
Feb 26, 2026In this work, we present the first theoretical analysis of multi-agent imitation learning (MAIL) in linear Markov games where both the transition dynamics and each agent's reward function are linear in some given features. We demonstrate that by leveraging this structure, it is possible to replace the state-action level "all policy deviation concentrability coefficient" (Freihaut et al., arXiv:2510.09325) with a concentrability coefficient defined at the feature level which can be much smaller than the state-action analog when the features are informative about states' similarity. Furthermore, to circumvent the need for any concentrability coefficient, we turn to the interactive setting. We provide the first, computationally efficient, interactive MAIL algorithm for linear Markov games and show that its sample complexity depends only on the dimension of the feature map $d$. Building on these theoretical findings, we propose a deep MAIL interactive algorithm which clearly outperforms BC on games such as Tic-Tac-Toe and Connect4.
Provably avoiding over-optimization in Direct Preference Optimization without knowing the data distribution
Feb 05, 2026We introduce PEPO (Pessimistic Ensemble based Preference Optimization), a single-step Direct Preference Optimization (DPO)-like algorithm to mitigate the well-known over-optimization issue in preference learning without requiring the knowledge of the data-generating distribution or learning an explicit reward model. PEPO achieves pessimism via an ensemble of preference-optimized policies trained on disjoint data subsets and then aggregates them through a worst case construction that favors the agreement across models. In the tabular setting, PEPO achieves sample complexity guarantees depending only on a single-policy concentrability coefficient, thus avoiding the all-policy concentrability which affects the guarantees of algorithms prone to over-optimization, such as DPO. The theoretical findings are corroborated by a convincing practical performance, while retaining the simplicity and the practicality of DPO-style training.
Direct Preference Optimization with Rating Information: Practical Algorithms and Provable Gains
Jan 31, 2026The class of direct preference optimization (DPO) algorithms has emerged as a promising approach for solving the alignment problem in foundation models. These algorithms work with very limited feedback in the form of pairwise preferences and fine-tune models to align with these preferences without explicitly learning a reward model. While the form of feedback used by these algorithms makes the data collection process easy and relatively more accurate, its ambiguity in terms of the quality of responses could have negative implications. For example, it is not clear if a decrease (increase) in the likelihood of preferred (dispreferred) responses during the execution of these algorithms could be interpreted as a positive or negative phenomenon. In this paper, we study how to design algorithms that can leverage additional information in the form of rating gap, which informs the learner how much the chosen response is better than the rejected one. We present new algorithms that can achieve faster statistical rates than DPO in presence of accurate rating gap information. Moreover, we theoretically prove and empirically show that the performance of our algorithms is robust to inaccuracy in rating gaps. Finally, we demonstrate the solid performance of our methods in comparison to a number of DPO-style algorithms across a wide range of LLMs and evaluation benchmarks.
Inverse Q-Learning Done Right: Offline Imitation Learning in $Q^π$-Realizable MDPs
May 26, 2025We study the problem of offline imitation learning in Markov decision processes (MDPs), where the goal is to learn a well-performing policy given a dataset of state-action pairs generated by an expert policy. Complementing a recent line of work on this topic that assumes the expert belongs to a tractable class of known policies, we approach this problem from a new angle and leverage a different type of structural assumption about the environment. Specifically, for the class of linear $Q^\pi$-realizable MDPs, we introduce a new algorithm called saddle-point offline imitation learning (\SPOIL), which is guaranteed to match the performance of any expert up to an additive error $\varepsilon$ with access to $\mathcal{O}(\varepsilon^{-2})$ samples. Moreover, we extend this result to possibly non-linear $Q^\pi$-realizable MDPs at the cost of a worse sample complexity of order $\mathcal{O}(\varepsilon^{-4})$. Finally, our analysis suggests a new loss function for training critic networks from expert data in deep imitation learning. Empirical evaluations on standard benchmarks demonstrate that the neural net implementation of \SPOIL is superior to behavior cloning and competitive with state-of-the-art algorithms.
Learning Equilibria from Data: Provably Efficient Multi-Agent Imitation Learning
May 23, 2025This paper provides the first expert sample complexity characterization for learning a Nash equilibrium from expert data in Markov Games. We show that a new quantity named the single policy deviation concentrability coefficient is unavoidable in the non-interactive imitation learning setting, and we provide an upper bound for behavioral cloning (BC) featuring such coefficient. BC exhibits substantial regret in games with high concentrability coefficient, leading us to utilize expert queries to develop and introduce two novel solution algorithms: MAIL-BRO and MURMAIL. The former employs a best response oracle and learns an $\varepsilon$-Nash equilibrium with $\mathcal{O}(\varepsilon^{-4})$ expert and oracle queries. The latter bypasses completely the best response oracle at the cost of a worse expert query complexity of order $\mathcal{O}(\varepsilon^{-8})$. Finally, we provide numerical evidence, confirming our theoretical findings.
IL-SOAR : Imitation Learning with Soft Optimistic Actor cRitic
Feb 27, 2025This paper introduces the SOAR framework for imitation learning. SOAR is an algorithmic template that learns a policy from expert demonstrations with a primal dual style algorithm that alternates cost and policy updates. Within the policy updates, the SOAR framework uses an actor critic method with multiple critics to estimate the critic uncertainty and build an optimistic critic fundamental to drive exploration. When instantiated in the tabular setting, we get a provable algorithm with guarantees that matches the best known results in $\epsilon$. Practically, the SOAR template is shown to boost consistently the performance of imitation learning algorithms based on Soft Actor Critic such as f-IRL, ML-IRL and CSIL in several MuJoCo environments. Overall, thanks to SOAR, the required number of episodes to achieve the same performance is reduced by half.
Optimistically Optimistic Exploration for Provably Efficient Infinite-Horizon Reinforcement and Imitation Learning
Feb 19, 2025We study the problem of reinforcement learning in infinite-horizon discounted linear Markov decision processes (MDPs), and propose the first computationally efficient algorithm achieving near-optimal regret guarantees in this setting. Our main idea is to combine two classic techniques for optimistic exploration: additive exploration bonuses applied to the reward function, and artificial transitions made to an absorbing state with maximal return. We show that, combined with a regularized approximate dynamic-programming scheme, the resulting algorithm achieves a regret of order $\tilde{\mathcal{O}} (\sqrt{d^3 (1 - \gamma)^{- 7 / 2} T})$, where $T$ is the total number of sample transitions, $\gamma \in (0,1)$ is the discount factor, and $d$ is the feature dimensionality. The results continue to hold against adversarial reward sequences, enabling application of our method to the problem of imitation learning in linear MDPs, where we achieve state-of-the-art results.
Multi-Step Alignment as Markov Games: An Optimistic Online Gradient Descent Approach with Convergence Guarantees
Feb 18, 2025



Reinforcement Learning from Human Feedback (RLHF) has been highly successful in aligning large language models with human preferences. While prevalent methods like DPO have demonstrated strong performance, they frame interactions with the language model as a bandit problem, which limits their applicability in real-world scenarios where multi-turn conversations are common. Additionally, DPO relies on the Bradley-Terry model assumption, which does not adequately capture the non-transitive nature of human preferences. In this paper, we address these challenges by modeling the alignment problem as a two-player constant-sum Markov game, where each player seeks to maximize their winning rate against the other across all steps of the conversation. Our approach Multi-step Preference Optimization (MPO) is built upon the natural actor-critic framework~\citep{peters2008natural}. We further develop OMPO based on the optimistic online gradient descent algorithm~\citep{rakhlin2013online,joulani17a}. Theoretically, we provide a rigorous analysis for both algorithms on convergence and show that OMPO requires $\mathcal{O}(\epsilon^{-1})$ policy updates to converge to an $\epsilon$-approximate Nash equilibrium. We also validate the effectiveness of our method on multi-turn conversations dataset and math reasoning dataset.
Best of Both Worlds: Regret Minimization versus Minimax Play
Feb 17, 2025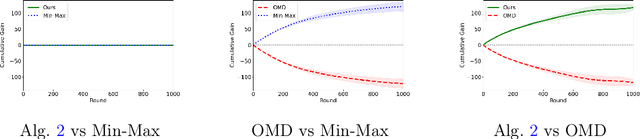


In this paper, we investigate the existence of online learning algorithms with bandit feedback that simultaneously guarantee $O(1)$ regret compared to a given comparator strategy, and $O(\sqrt{T})$ regret compared to the best strategy in hindsight, where $T$ is the number of rounds. We provide the first affirmative answer to this question. In the context of symmetric zero-sum games, both in normal- and extensive form, we show that our results allow us to guarantee to risk at most $O(1)$ loss while being able to gain $\Omega(T)$ from exploitable opponents, thereby combining the benefits of both no-regret algorithms and minimax play.