 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwap Regret and Correlated Equilibria Beyond Normal-Form Games
Feb 27, 2025Swap regret is a notion that has proven itself to be central to the study of general-sum normal-form games, with swap-regret minimization leading to convergence to the set of correlated equilibria and guaranteeing non-manipulability against a self-interested opponent. However, the situation for more general classes of games -- such as Bayesian games and extensive-form games -- is less clear-cut, with multiple candidate definitions for swap-regret but no known efficiently minimizable variant of swap regret that implies analogous non-manipulability guarantees. In this paper, we present a new variant of swap regret for polytope games that we call ``profile swap regret'', with the property that obtaining sublinear profile swap regret is both necessary and sufficient for any learning algorithm to be non-manipulable by an opponent (resolving an open problem of Mansour et al., 2022). Although we show profile swap regret is NP-hard to compute given a transcript of play, we show it is nonetheless possible to design efficient learning algorithms that guarantee at most $O(\sqrt{T})$ profile swap regret. Finally, we explore the correlated equilibrium notion induced by low-profile-swap-regret play, and demonstrate a gap between the set of outcomes that can be implemented by this learning process and the set of outcomes that can be implemented by a third-party mediator (in contrast to the situation in normal-form games).
Learning to Play Against Unknown Opponents
Dec 24, 2024
We consider the problem of a learning agent who has to repeatedly play a general sum game against a strategic opponent who acts to maximize their own payoff by optimally responding against the learner's algorithm. The learning agent knows their own payoff function, but is uncertain about the payoff of their opponent (knowing only that it is drawn from some distribution $\mathcal{D}$). What learning algorithm should the agent run in order to maximize their own total utility? We demonstrate how to construct an $\varepsilon$-optimal learning algorithm (obtaining average utility within $\varepsilon$ of the optimal utility) for this problem in time polynomial in the size of the input and $1/\varepsilon$ when either the size of the game or the support of $\mathcal{D}$ is constant. When the learning algorithm is further constrained to be a no-regret algorithm, we demonstrate how to efficiently construct an optimal learning algorithm (asymptotically achieving the optimal utility) in polynomial time, independent of any other assumptions. Both results make use of recently developed machinery that converts the analysis of learning algorithms to the study of the class of corresponding geometric objects known as menus.
Algorithmic Collusion Without Threats
Sep 06, 2024There has been substantial recent concern that pricing algorithms might learn to ``collude.'' Supra-competitive prices can emerge as a Nash equilibrium of repeated pricing games, in which sellers play strategies which threaten to punish their competitors who refuse to support high prices, and these strategies can be automatically learned. In fact, a standard economic intuition is that supra-competitive prices emerge from either the use of threats, or a failure of one party to optimize their payoff. Is this intuition correct? Would preventing threats in algorithmic decision-making prevent supra-competitive prices when sellers are optimizing for their own revenue? No. We show that supra-competitive prices can emerge even when both players are using algorithms which do not encode threats, and which optimize for their own revenue. We study sequential pricing games in which a first mover deploys an algorithm and then a second mover optimizes within the resulting environment. We show that if the first mover deploys any algorithm with a no-regret guarantee, and then the second mover even approximately optimizes within this now static environment, monopoly-like prices arise. The result holds for any no-regret learning algorithm deployed by the first mover and for any pricing policy of the second mover that obtains them profit at least as high as a random pricing would -- and hence the result applies even when the second mover is optimizing only within a space of non-responsive pricing distributions which are incapable of encoding threats. In fact, there exists a set of strategies, neither of which explicitly encode threats that form a Nash equilibrium of the simultaneous pricing game in algorithm space, and lead to near monopoly prices. This suggests that the definition of ``algorithmic collusion'' may need to be expanded, to include strategies without explicitly encoded threats.
An Elementary Predictor Obtaining $2\sqrt{T}$ Distance to Calibration
Feb 18, 2024Blasiok et al. [2023] proposed distance to calibration as a natural measure of calibration error that unlike expected calibration error (ECE) is continuous. Recently, Qiao and Zheng [2024] gave a non-constructive argument establishing the existence of an online predictor that can obtain $O(\sqrt{T})$ distance to calibration in the adversarial setting, which is known to be impossible for ECE. They leave as an open problem finding an explicit, efficient algorithm. We resolve this problem and give an extremely simple, efficient, deterministic algorithm that obtains distance to calibration error at most $2\sqrt{T}$.
Oracle Efficient Algorithms for Groupwise Regret
Oct 07, 2023We study the problem of online prediction, in which at each time step $t$, an individual $x_t$ arrives, whose label we must predict. Each individual is associated with various groups, defined based on their features such as age, sex, race etc., which may intersect. Our goal is to make predictions that have regret guarantees not just overall but also simultaneously on each sub-sequence comprised of the members of any single group. Previous work such as [Blum & Lykouris] and [Lee et al] provide attractive regret guarantees for these problems; however, these are computationally intractable on large model classes. We show that a simple modification of the sleeping experts technique of [Blum & Lykouris] yields an efficient reduction to the well-understood problem of obtaining diminishing external regret absent group considerations. Our approach gives similar regret guarantees compared to [Blum & Lykouris]; however, we run in time linear in the number of groups, and are oracle-efficient in the hypothesis class. This in particular implies that our algorithm is efficient whenever the number of groups is polynomially bounded and the external-regret problem can be solved efficiently, an improvement on [Blum & Lykouris]'s stronger condition that the model class must be small. Our approach can handle online linear regression and online combinatorial optimization problems like online shortest paths. Beyond providing theoretical regret bounds, we evaluate this algorithm with an extensive set of experiments on synthetic data and on two real data sets -- Medical costs and the Adult income dataset, both instantiated with intersecting groups defined in terms of race, sex, and other demographic characteristics. We find that uniformly across groups, our algorithm gives substantial error improvements compared to running a standard online linear regression algorithm with no groupwise regret guarantees.
Pipeline Interventions
Feb 16, 2020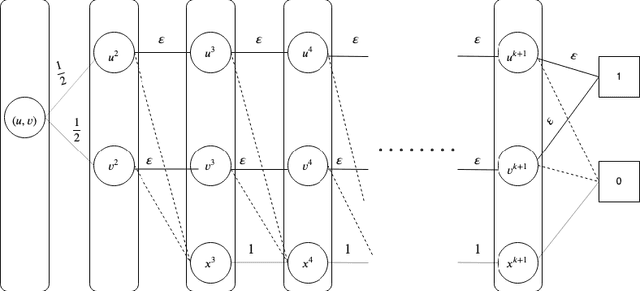
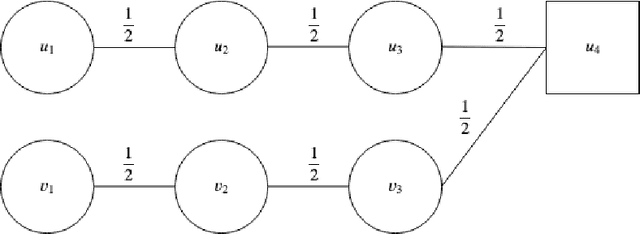
We introduce the \emph{pipeline intervention} problem, defined by a layered directed acyclic graph and a set of stochastic matrices governing transitions between successive layers. The graph is a stylized model for how people from different populations are presented opportunities, eventually leading to some reward. In our model, individuals are born into an initial position (i.e. some node in the first layer of the graph) according to a fixed probability distribution, and then stochastically progress through the graph according to the transition matrices, until they reach a node in the final layer of the graph; each node in the final layer has a \emph{reward} associated with it. The pipeline intervention problem asks how to best make costly changes to the transition matrices governing people's stochastic transitions through the graph, subject to a budget constraint. We consider two objectives: social welfare maximization, and a fairness-motivated maximin objective that seeks to maximize the value to the population (starting node) with the \emph{least} expected value. We consider two variants of the maximin objective that turn out to be distinct, depending on whether we demand a deterministic solution or allow randomization. For each objective, we give an efficient approximation algorithm (an additive FPTAS) for constant width networks. We also tightly characterize the "price of fairness" in our setting: the ratio between the highest achievable social welfare and the highest social welfare consistent with a maximin optimal solution. Finally we show that for polynomial width networks, even approximating the maximin objective to any constant factor is NP hard, even for networks with constant depth. This shows that the restriction on the width in our positive results is essential.