 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
A New Benchmark for Online Learning with Budget-Balancing Constraints
Mar 19, 2025The adversarial Bandit with Knapsack problem is a multi-armed bandits problem with budget constraints and adversarial rewards and costs. In each round, a learner selects an action to take and observes the reward and cost of the selected action. The goal is to maximize the sum of rewards while satisfying the budget constraint. The classical benchmark to compare against is the best fixed distribution over actions that satisfies the budget constraint in expectation. Unlike its stochastic counterpart, where rewards and costs are drawn from some fixed distribution (Badanidiyuru et al., 2018), the adversarial BwK problem does not admit a no-regret algorithm for every problem instance due to the "spend-or-save" dilemma (Immorlica et al., 2022). A key problem left open by existing works is whether there exists a weaker but still meaningful benchmark to compare against such that no-regret learning is still possible. In this work, we present a new benchmark to compare against, motivated both by real-world applications such as autobidding and by its underlying mathematical structure. The benchmark is based on the Earth Mover's Distance (EMD), and we show that sublinear regret is attainable against any strategy whose spending pattern is within EMD $o(T^2)$ of any sub-pacing spending pattern. As a special case, we obtain results against the "pacing over windows" benchmark, where we partition time into disjoint windows of size $w$ and allow the benchmark strategies to choose a different distribution over actions for each window while satisfying a pacing budget constraint. Against this benchmark, our algorithm obtains a regret bound of $\tilde{O}(T/\sqrt{w}+\sqrt{wT})$. We also show a matching lower bound, proving the optimality of our algorithm in this important special case. In addition, we provide further evidence of the necessity of the EMD condition for obtaining a sublinear regret.
Retraining with Predicted Hard Labels Provably Increases Model Accuracy
Jun 17, 2024The performance of a model trained with \textit{noisy labels} is often improved by simply \textit{retraining} the model with its own predicted \textit{hard} labels (i.e., $1$/$0$ labels). Yet, a detailed theoretical characterization of this phenomenon is lacking. In this paper, we theoretically analyze retraining in a linearly separable setting with randomly corrupted labels given to us and prove that retraining can improve the population accuracy obtained by initially training with the given (noisy) labels. To the best of our knowledge, this is the first such theoretical result. Retraining finds application in improving training with label differential privacy (DP) which involves training with noisy labels. We empirically show that retraining selectively on the samples for which the predicted label matches the given label significantly improves label DP training at \textit{no extra privacy cost}; we call this \textit{consensus-based retraining}. For e.g., when training ResNet-18 on CIFAR-100 with $\epsilon=3$ label DP, we obtain $6.4\%$ improvement in accuracy with consensus-based retraining.
Learning across Data Owners with Joint Differential Privacy
May 25, 2023In this paper, we study the setting in which data owners train machine learning models collaboratively under a privacy notion called joint differential privacy [Kearns et al., 2018]. In this setting, the model trained for each data owner $j$ uses $j$'s data without privacy consideration and other owners' data with differential privacy guarantees. This setting was initiated in [Jain et al., 2021] with a focus on linear regressions. In this paper, we study this setting for stochastic convex optimization (SCO). We present an algorithm that is a variant of DP-SGD [Song et al., 2013; Abadi et al., 2016] and provides theoretical bounds on its population loss. We compare our algorithm to several baselines and discuss for what parameter setups our algorithm is more preferred. We also empirically study joint differential privacy in the multi-class classification problem over two public datasets. Our empirical findings are well-connected to the insights from our theoretical results.
Regret Minimization with Noisy Observations
Jul 19, 2022In a typical optimization problem, the task is to pick one of a number of options with the lowest cost or the highest value. In practice, these cost/value quantities often come through processes such as measurement or machine learning, which are noisy, with quantifiable noise distributions. To take these noise distributions into account, one approach is to assume a prior for the values, use it to build a posterior, and then apply standard stochastic optimization to pick a solution. However, in many practical applications, such prior distributions may not be available. In this paper, we study such scenarios using a regret minimization model. In our model, the task is to pick the highest one out of $n$ values. The values are unknown and chosen by an adversary, but can be observed through noisy channels, where additive noises are stochastically drawn from known distributions. The goal is to minimize the regret of our selection, defined as the expected difference between the highest and the selected value on the worst-case choices of values. We show that the na\"ive algorithm of picking the highest observed value has regret arbitrarily worse than the optimum, even when $n = 2$ and the noises are unbiased in expectation. On the other hand, we propose an algorithm which gives a constant-approximation to the optimal regret for any $n$. Our algorithm is conceptually simple, computationally efficient, and requires only minimal knowledge of the noise distributions.
Shuffle Private Stochastic Convex Optimization
Jun 17, 2021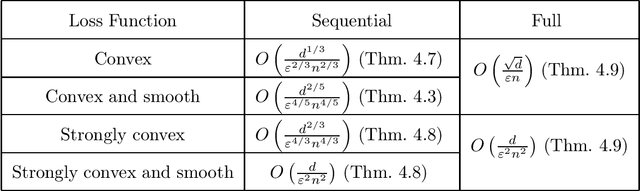
In shuffle privacy, each user sends a collection of randomized messages to a trusted shuffler, the shuffler randomly permutes these messages, and the resulting shuffled collection of messages must satisfy differential privacy. Prior work in this model has largely focused on protocols that use a single round of communication to compute algorithmic primitives like means, histograms, and counts. In this work, we present interactive shuffle protocols for stochastic convex optimization. Our optimization protocols rely on a new noninteractive protocol for summing vectors of bounded $\ell_2$ norm. By combining this sum subroutine with techniques including mini-batch stochastic gradient descent, accelerated gradient descent, and Nesterov's smoothing method, we obtain loss guarantees for a variety of convex loss functions that significantly improve on those of the local model and sometimes match those of the central model.
Connecting Robust Shuffle Privacy and Pan-Privacy
Apr 30, 2020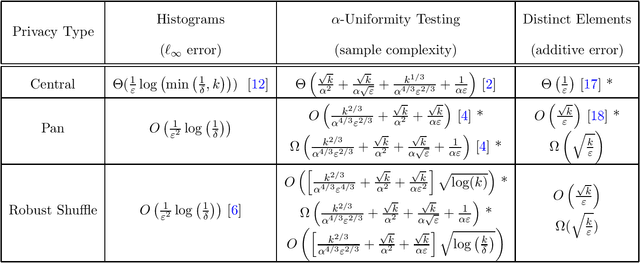
In the shuffle model of differential privacy, data-holding users send randomized messages to a secure shuffler, the shuffler permutes the messages, and the resulting collection of messages must be differentially private with regard to user data. In the pan-private model, an algorithm processes a stream of data while maintaining an internal state that is differentially private with regard to the stream data. We give evidence connecting these two apparently different models. Our results focus on robustly shuffle private protocols whose privacy guarantees are not greatly affected by malicious users. First, we give robustly shuffle private protocols and upper bounds for counting distinct elements and uniformity testing. Second, we use pan-private lower bounds to prove robustly shuffle private lower bounds for both problems. Focusing on the dependence on the domain size $k$, we find that both robust shuffle privacy and pan-privacy have additive accuracy $\Theta(\sqrt{k})$ for counting distinct elements and sample complexity $\tilde \Theta(k^{2/3})$ for uniformity testing. Both results polynomially separate central privacy and robust shuffle privacy. Finally, we show that this connection is useful in both directions: we give a pan-private adaptation of recent work on shuffle private histograms and use it to recover further separations between pan-privacy and interactive local privacy.
Pan-Private Uniformity Testing
Nov 04, 2019
A centrally differentially private algorithm maps raw data to differentially private outputs. In contrast, a locally differentially private algorithm may only access data through public interaction with data holders, and this interaction must be a differentially private function of the data. We study the intermediate model of pan-privacy. Unlike a locally private algorithm, a pan-private algorithm receives data in the clear. Unlike a centrally private algorithm, the algorithm receives data one element at a time and must maintain a differentially private internal state while processing this stream. First, we show that pan-privacy against multiple intrusions on the internal state is equivalent to sequentially interactive local privacy. Next, we contextualize pan-privacy against a single intrusion by analyzing the sample complexity of uniformity testing over domain $[k]$. Focusing on the dependence on $k$, centrally private uniformity testing has sample complexity $\Theta(\sqrt{k})$, while noninteractive locally private uniformity testing has sample complexity $\Theta(k)$. We show that the sample complexity of pan-private uniformity testing is $\Theta(k^{2/3})$. By a new $\Omega(k)$ lower bound for the sequentially interactive setting, we also separate pan-private from sequentially interactive locally private and multi-intrusion pan-private uniformity testing.
Exponential Separations in Local Differential Privacy Through Communication Complexity
Jul 01, 2019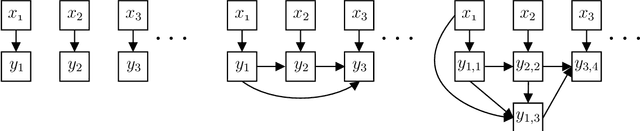
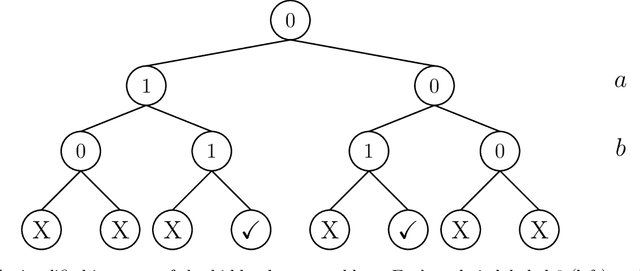
We prove a general connection between the communication complexity of two-player games and the sample complexity of their multi-player locally private analogues. We use this connection to prove sample complexity lower bounds for locally differentially private protocols as straightforward corollaries of results from communication complexity. In particular, we 1) use a communication lower bound for the hidden layers problem to prove an exponential sample complexity separation between sequentially and fully interactive locally private protocols, and 2) use a communication lower bound for the pointer chasing problem to prove an exponential sample complexity separation between $k$ round and $k+1$ round sequentially interactive locally private protocols, for every $k$.
Sorted Top-k in Rounds
Jun 12, 2019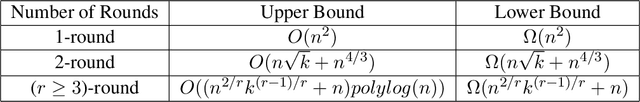

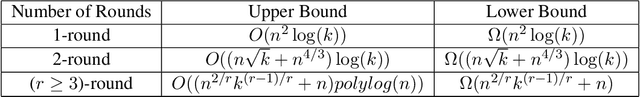

We consider the sorted top-$k$ problem whose goal is to recover the top-$k$ items with the correct order out of $n$ items using pairwise comparisons. In many applications, multiple rounds of interaction can be costly. We restrict our attention to algorithms with a constant number of rounds $r$ and try to minimize the sample complexity, i.e. the number of comparisons. When the comparisons are noiseless, we characterize how the optimal sample complexity depends on the number of rounds (up to a polylogarithmic factor for general $r$ and up to a constant factor for $r=1$ or 2). In particular, the sample complexity is $\Theta(n^2)$ for $r=1$, $\Theta(n\sqrt{k} + n^{4/3})$ for $r=2$ and $\tilde{\Theta}\left(n^{2/r} k^{(r-1)/r} + n\right)$ for $r \geq 3$. We extend our results of sorted top-$k$ to the noisy case where each comparison is correct with probability $2/3$. When $r=1$ or 2, we show that the sample complexity gets an extra $\Theta(\log(k))$ factor when we transition from the noiseless case to the noisy case. We also prove new results for top-$k$ and sorting in the noisy case. We believe our techniques can be generally useful for understanding the trade-off between round complexities and sample complexities of rank aggregation problems.