 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Private Linear Regression Through Better Private Feature Selection
Jun 01, 2023



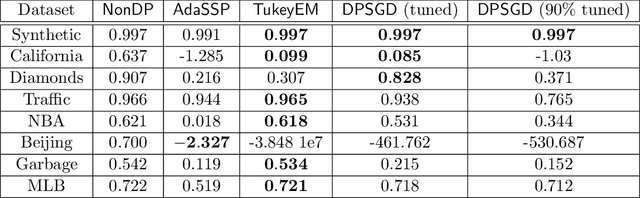
Existing work on differentially private linear regression typically assumes that end users can precisely set data bounds or algorithmic hyperparameters. End users often struggle to meet these requirements without directly examining the data (and violating privacy). Recent work has attempted to develop solutions that shift these burdens from users to algorithms, but they struggle to provide utility as the feature dimension grows. This work extends these algorithms to higher-dimensional problems by introducing a differentially private feature selection method based on Kendall rank correlation. We prove a utility guarantee for the setting where features are normally distributed and conduct experiments across 25 datasets. We find that adding this private feature selection step before regression significantly broadens the applicability of ``plug-and-play'' private linear regression algorithms at little additional cost to privacy, computation, or decision-making by the end user.
Easy Differentially Private Linear Regression
Aug 15, 2022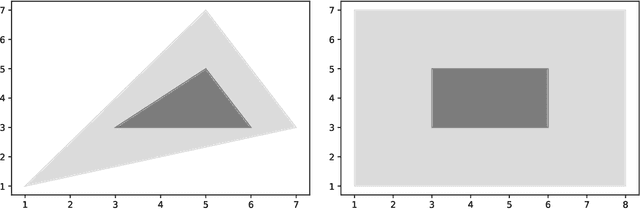
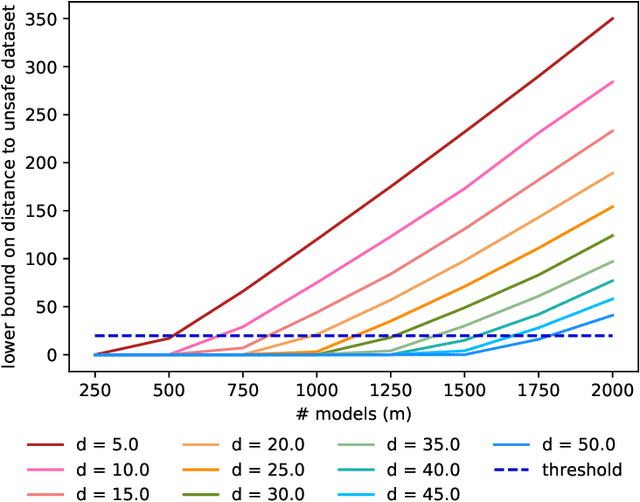
Linear regression is a fundamental tool for statistical analysis. This has motivated the development of linear regression methods that also satisfy differential privacy and thus guarantee that the learned model reveals little about any one data point used to construct it. However, existing differentially private solutions assume that the end user can easily specify good data bounds and hyperparameters. Both present significant practical obstacles. In this paper, we study an algorithm which uses the exponential mechanism to select a model with high Tukey depth from a collection of non-private regression models. Given $n$ samples of $d$-dimensional data used to train $m$ models, we construct an efficient analogue using an approximate Tukey depth that runs in time $O(d^2n + dm\log(m))$. We find that this algorithm obtains strong empirical performance in the data-rich setting with no data bounds or hyperparameter selection required.
Shuffle Private Stochastic Convex Optimization
Jun 17, 2021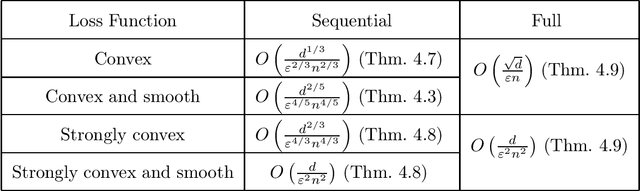
In shuffle privacy, each user sends a collection of randomized messages to a trusted shuffler, the shuffler randomly permutes these messages, and the resulting shuffled collection of messages must satisfy differential privacy. Prior work in this model has largely focused on protocols that use a single round of communication to compute algorithmic primitives like means, histograms, and counts. In this work, we present interactive shuffle protocols for stochastic convex optimization. Our optimization protocols rely on a new noninteractive protocol for summing vectors of bounded $\ell_2$ norm. By combining this sum subroutine with techniques including mini-batch stochastic gradient descent, accelerated gradient descent, and Nesterov's smoothing method, we obtain loss guarantees for a variety of convex loss functions that significantly improve on those of the local model and sometimes match those of the central model.
Differentially Private Quantiles
Feb 16, 2021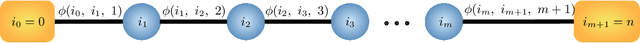

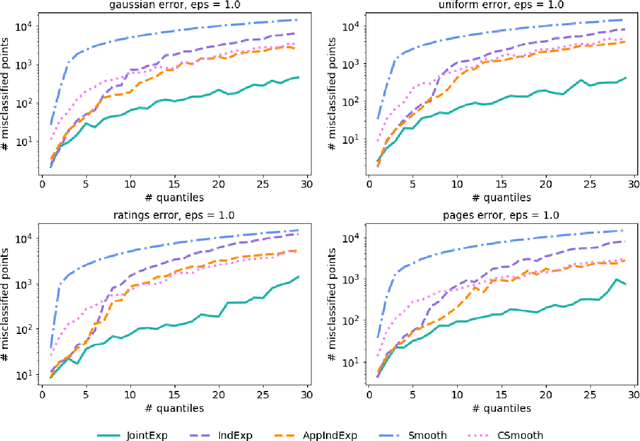
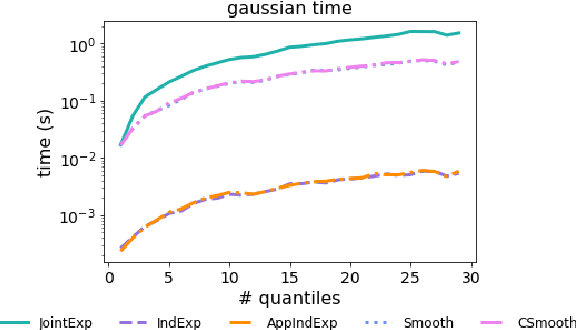
Quantiles are often used for summarizing and understanding data. If that data is sensitive, it may be necessary to compute quantiles in a way that is differentially private, providing theoretical guarantees that the result does not reveal private information. However, in the common case where multiple quantiles are needed, existing differentially private algorithms scale poorly: they compute each quantile individually, splitting their privacy budget and thus decreasing accuracy. In this work we propose an instance of the exponential mechanism that simultaneously estimates $m$ quantiles from $n$ data points while guaranteeing differential privacy. The utility function is carefully structured to allow for an efficient implementation that avoids exponential dependence on $m$ and returns estimates of all $m$ quantiles in time $O(mn^2 + m^2n)$. Experiments show that our method significantly outperforms the current state of the art on both real and synthetic data while remaining efficient enough to be practical.
Connecting Robust Shuffle Privacy and Pan-Privacy
Apr 30, 2020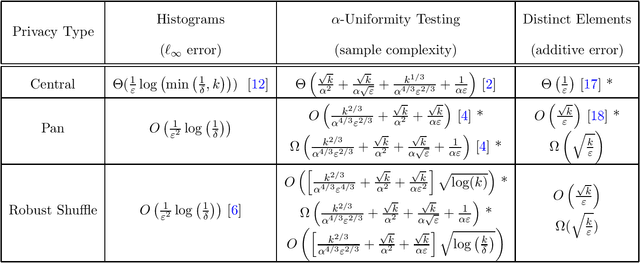
In the shuffle model of differential privacy, data-holding users send randomized messages to a secure shuffler, the shuffler permutes the messages, and the resulting collection of messages must be differentially private with regard to user data. In the pan-private model, an algorithm processes a stream of data while maintaining an internal state that is differentially private with regard to the stream data. We give evidence connecting these two apparently different models. Our results focus on robustly shuffle private protocols whose privacy guarantees are not greatly affected by malicious users. First, we give robustly shuffle private protocols and upper bounds for counting distinct elements and uniformity testing. Second, we use pan-private lower bounds to prove robustly shuffle private lower bounds for both problems. Focusing on the dependence on the domain size $k$, we find that both robust shuffle privacy and pan-privacy have additive accuracy $\Theta(\sqrt{k})$ for counting distinct elements and sample complexity $\tilde \Theta(k^{2/3})$ for uniformity testing. Both results polynomially separate central privacy and robust shuffle privacy. Finally, we show that this connection is useful in both directions: we give a pan-private adaptation of recent work on shuffle private histograms and use it to recover further separations between pan-privacy and interactive local privacy.
Pan-Private Uniformity Testing
Nov 04, 2019
A centrally differentially private algorithm maps raw data to differentially private outputs. In contrast, a locally differentially private algorithm may only access data through public interaction with data holders, and this interaction must be a differentially private function of the data. We study the intermediate model of pan-privacy. Unlike a locally private algorithm, a pan-private algorithm receives data in the clear. Unlike a centrally private algorithm, the algorithm receives data one element at a time and must maintain a differentially private internal state while processing this stream. First, we show that pan-privacy against multiple intrusions on the internal state is equivalent to sequentially interactive local privacy. Next, we contextualize pan-privacy against a single intrusion by analyzing the sample complexity of uniformity testing over domain $[k]$. Focusing on the dependence on $k$, centrally private uniformity testing has sample complexity $\Theta(\sqrt{k})$, while noninteractive locally private uniformity testing has sample complexity $\Theta(k)$. We show that the sample complexity of pan-private uniformity testing is $\Theta(k^{2/3})$. By a new $\Omega(k)$ lower bound for the sequentially interactive setting, we also separate pan-private from sequentially interactive locally private and multi-intrusion pan-private uniformity testing.
Exponential Separations in Local Differential Privacy Through Communication Complexity
Jul 01, 2019
We prove a general connection between the communication complexity of two-player games and the sample complexity of their multi-player locally private analogues. We use this connection to prove sample complexity lower bounds for locally differentially private protocols as straightforward corollaries of results from communication complexity. In particular, we 1) use a communication lower bound for the hidden layers problem to prove an exponential sample complexity separation between sequentially and fully interactive locally private protocols, and 2) use a communication lower bound for the pointer chasing problem to prove an exponential sample complexity separation between $k$ round and $k+1$ round sequentially interactive locally private protocols, for every $k$.
The Role of Interactivity in Local Differential Privacy
Apr 07, 2019
We study the power of interactivity in local differential privacy. First, we focus on the difference between fully interactive and sequentially interactive protocols. Sequentially interactive protocols may query users adaptively in sequence, but they cannot return to previously queried users. The vast majority of existing lower bounds for local differential privacy apply only to sequentially interactive protocols, and before this paper it was not known whether fully interactive protocols were more powerful. We resolve this question. First, we classify locally private protocols by their compositionality, the multiplicative factor $k \geq 1$ by which the sum of a protocol's single-round privacy parameters exceeds its overall privacy guarantee. We then show how to efficiently transform any fully interactive $k$-compositional protocol into an equivalent sequentially interactive protocol with an $O(k)$ blowup in sample complexity. Next, we show that our reduction is tight by exhibiting a family of problems such that for any $k$, there is a fully interactive $k$-compositional protocol which solves the problem, while no sequentially interactive protocol can solve the problem without at least an $\tilde \Omega(k)$ factor more examples. We then turn our attention to hypothesis testing problems. We show that for a large class of compound hypothesis testing problems --- which include all simple hypothesis testing problems as a special case --- a simple noninteractive test is optimal among the class of all (possibly fully interactive) tests.
Locally Private Gaussian Estimation
Nov 20, 2018
We study a basic private estimation problem: each of $n$ users draws a single i.i.d. sample from an unknown Gaussian distribution, and the goal is to estimate the mean of this Gaussian distribution while satisfying local differential privacy for each user. Informally, local differential privacy requires that each data point is individually and independently privatized before it is passed to a learning algorithm. Locally private Gaussian estimation is therefore difficult because the data domain is unbounded: users may draw arbitrarily different inputs, but local differential privacy nonetheless mandates that different users have (worst-case) similar privatized output distributions. We provide both adaptive two-round solutions and nonadaptive one-round solutions for locally private Gaussian estimation. We then partially match these upper bounds with an information-theoretic lower bound. This lower bound shows that our accuracy guarantees are tight up to logarithmic factors for all sequentially interactive $(\varepsilon,\delta)$-locally private protocols.
Local Differential Privacy for Evolving Data
May 22, 2018There are now several large scale deployments of differential privacy used to collect statistical information about users. However, these deployments periodically recollect the data and recompute the statistics using algorithms designed for a single use. As a result, these systems do not provide meaningful privacy guarantees over long time scales. Moreover, existing techniques to mitigate this effect do not apply in the "local model" of differential privacy that these systems use. In this paper, we introduce a new technique for local differential privacy that makes it possible to maintain up-to-date statistics over time, with privacy guarantees that degrade only in the number of changes in the underlying distribution rather than the number of collection periods. We use our technique for tracking a changing statistic in the setting where users are partitioned into an unknown collection of groups, and at every time period each user draws a single bit from a common (but changing) group-specific distribution. We also provide an application to frequency and heavy-hitter estimation.