 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models: A Survey
Feb 20, 2024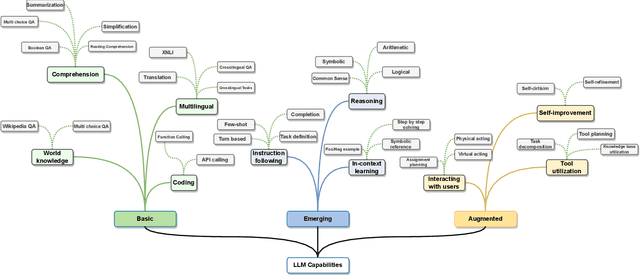
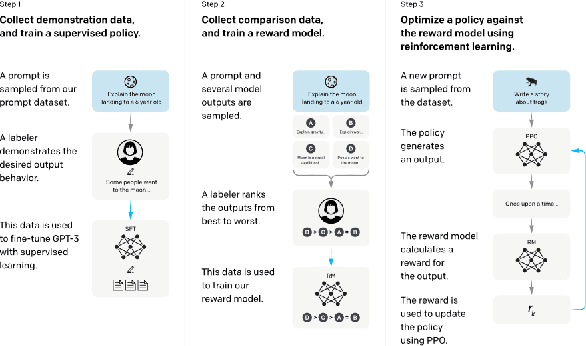
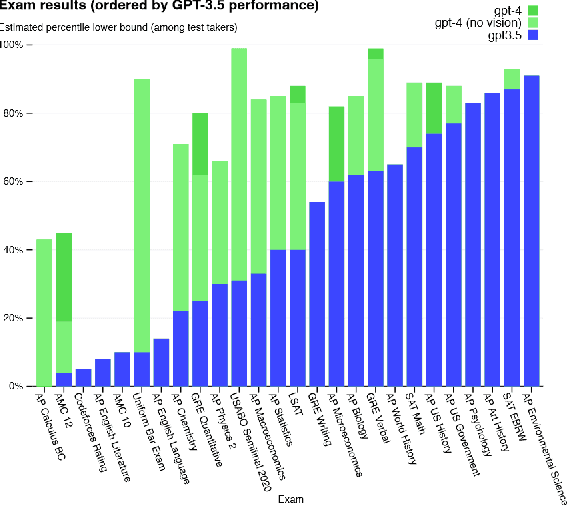
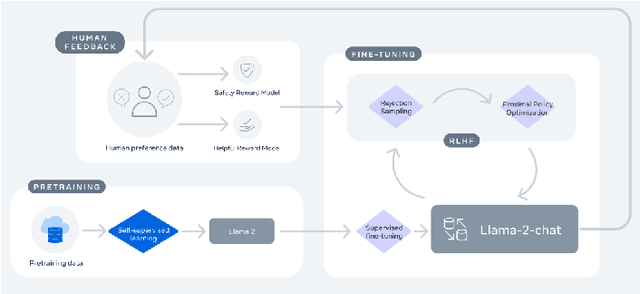
Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs' ability of general-purpose language understanding and generation is acquired by training billions of model's parameters on massive amounts of text data, as predicted by scaling laws \cite{kaplan2020scaling,hoffmann2022training}. The research area of LLMs, while very recent, is evolving rapidly in many different ways. In this paper, we review some of the most prominent LLMs, including three popular LLM families (GPT, LLaMA, PaLM), and discuss their characteristics, contributions and limitations. We also give an overview of techniques developed to build, and augment LLMs. We then survey popular datasets prepared for LLM training, fine-tuning, and evaluation, review widely used LLM evaluation metrics, and compare the performance of several popular LLMs on a set of representative benchmarks. Finally, we conclude the paper by discussing open challenges and future research directions.
Converse: A Tree-Based Modular Task-Oriented Dialogue System
Mar 30, 2022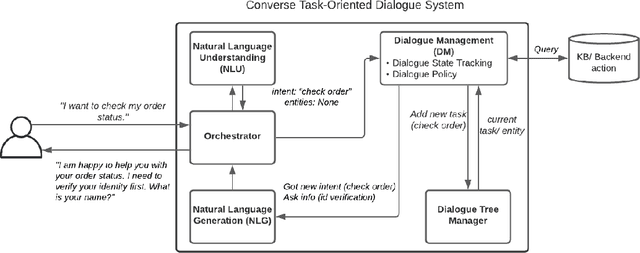

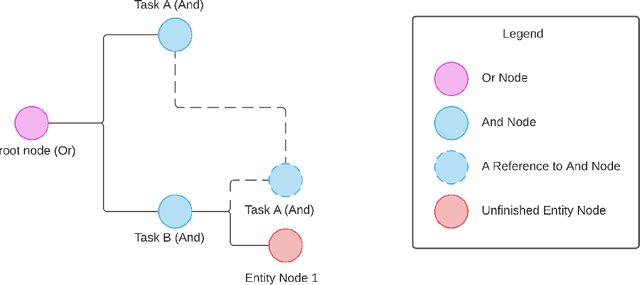
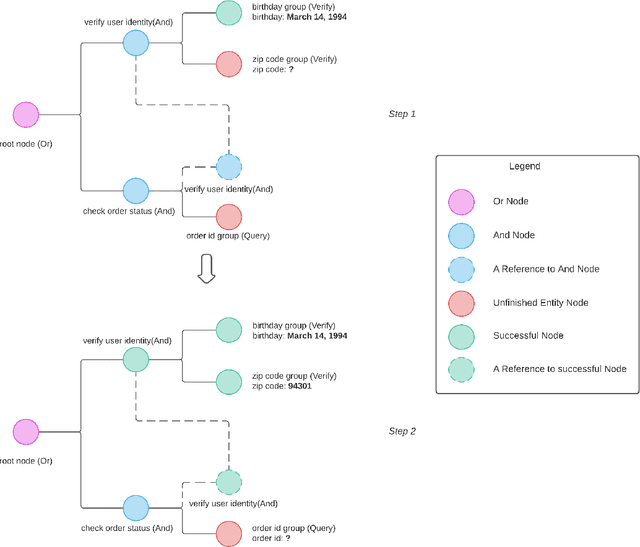
Creating a system that can have meaningful conversations with humans to help accomplish tasks is one of the ultimate goals of Artificial Intelligence (AI). It has defined the meaning of AI since the beginning. A lot has been accomplished in this area recently, with voice assistant products entering our daily lives and chat bot systems becoming commonplace in customer service. At first glance there seems to be no shortage of options for dialogue systems. However, the frequently deployed dialogue systems today seem to all struggle with a critical weakness - they are hard to build and harder to maintain. At the core of the struggle is the need to script every single turn of interactions between the bot and the human user. This makes the dialogue systems more difficult to maintain as the tasks become more complex and more tasks are added to the system. In this paper, we propose Converse, a flexible tree-based modular task-oriented dialogue system. Converse uses an and-or tree structure to represent tasks and offers powerful multi-task dialogue management. Converse supports task dependency and task switching, which are unique features compared to other open-source dialogue frameworks. At the same time, Converse aims to make the bot building process easy and simple, for both professional and non-professional software developers. The code is available at https://github.com/salesforce/Converse.
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning
Aug 05, 2021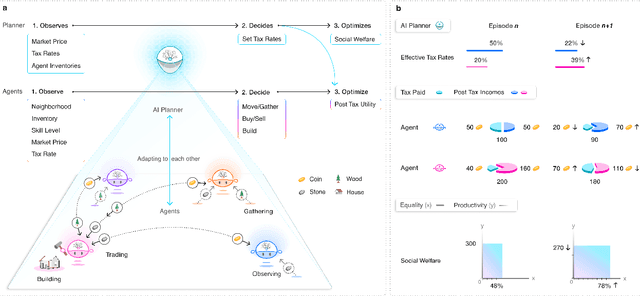
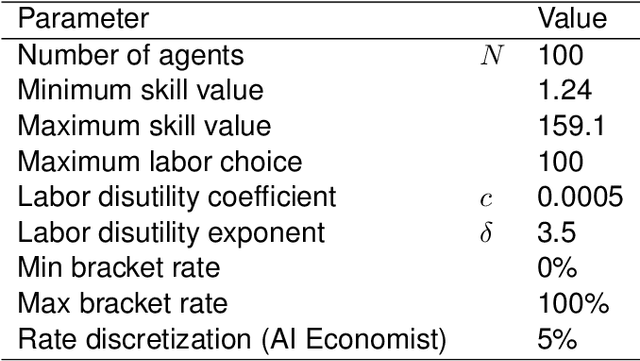
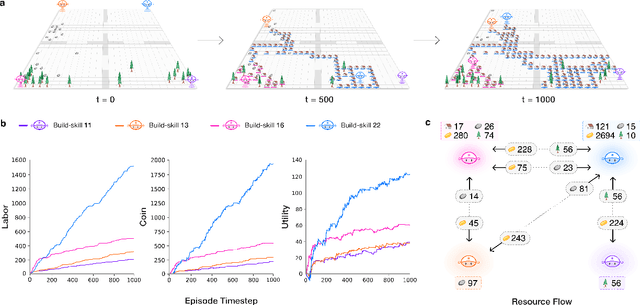
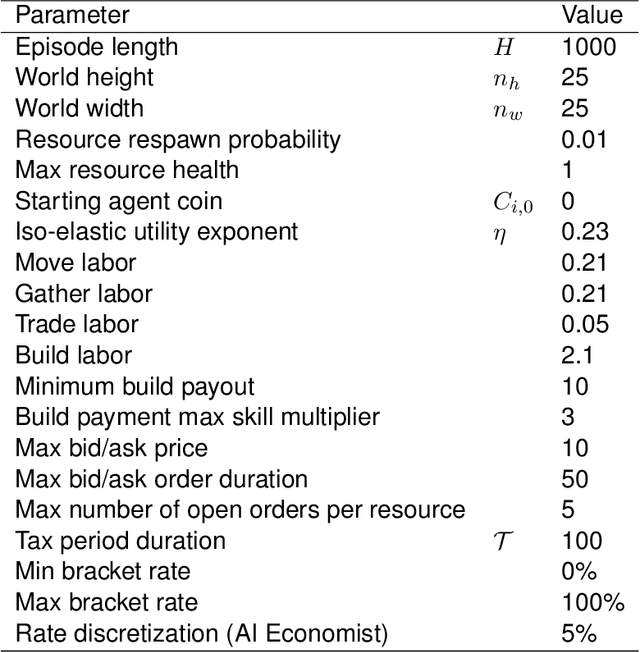
AI and reinforcement learning (RL) have improved many areas, but are not yet widely adopted in economic policy design, mechanism design, or economics at large. At the same time, current economic methodology is limited by a lack of counterfactual data, simplistic behavioral models, and limited opportunities to experiment with policies and evaluate behavioral responses. Here we show that machine-learning-based economic simulation is a powerful policy and mechanism design framework to overcome these limitations. The AI Economist is a two-level, deep RL framework that trains both agents and a social planner who co-adapt, providing a tractable solution to the highly unstable and novel two-level RL challenge. From a simple specification of an economy, we learn rational agent behaviors that adapt to learned planner policies and vice versa. We demonstrate the efficacy of the AI Economist on the problem of optimal taxation. In simple one-step economies, the AI Economist recovers the optimal tax policy of economic theory. In complex, dynamic economies, the AI Economist substantially improves both utilitarian social welfare and the trade-off between equality and productivity over baselines. It does so despite emergent tax-gaming strategies, while accounting for agent interactions and behavioral change more accurately than economic theory. These results demonstrate for the first time that two-level, deep RL can be used for understanding and as a complement to theory for economic design, unlocking a new computational learning-based approach to understanding economic policy.
Evaluating State-of-the-Art Classification Models Against Bayes Optimality
Jun 07, 2021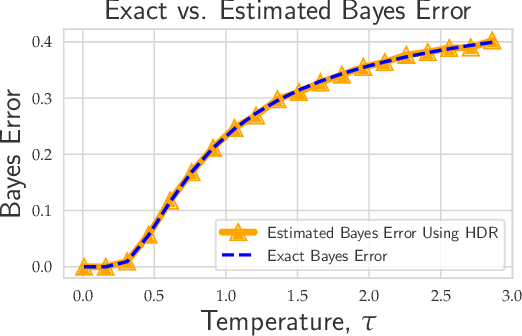
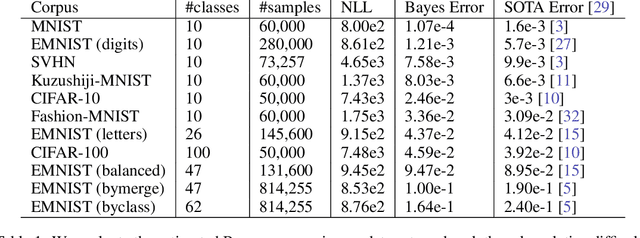

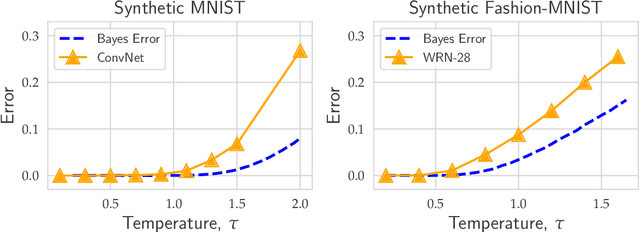
Evaluating the inherent difficulty of a given data-driven classification problem is important for establishing absolute benchmarks and evaluating progress in the field. To this end, a natural quantity to consider is the \emph{Bayes error}, which measures the optimal classification error theoretically achievable for a given data distribution. While generally an intractable quantity, we show that we can compute the exact Bayes error of generative models learned using normalizing flows. Our technique relies on a fundamental result, which states that the Bayes error is invariant under invertible transformation. Therefore, we can compute the exact Bayes error of the learned flow models by computing it for Gaussian base distributions, which can be done efficiently using Holmes-Diaconis-Ross integration. Moreover, we show that by varying the temperature of the learned flow models, we can generate synthetic datasets that closely resemble standard benchmark datasets, but with almost any desired Bayes error. We use our approach to conduct a thorough investigation of state-of-the-art classification models, and find that in some -- but not all -- cases, these models are capable of obtaining accuracy very near optimal. Finally, we use our method to evaluate the intrinsic "hardness" of standard benchmark datasets, and classes within those datasets.
Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
Dec 31, 2020
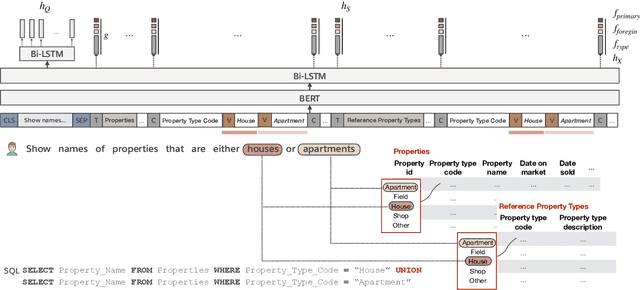
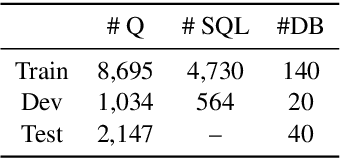
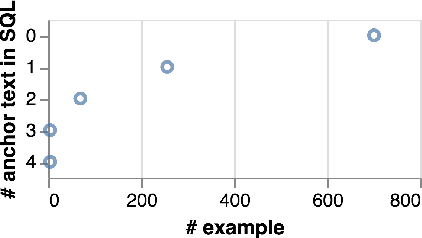
We present BRIDGE, a powerful sequential architecture for modeling dependencies between natural language questions and relational databases in cross-DB semantic parsing. BRIDGE represents the question and DB schema in a tagged sequence where a subset of the fields are augmented with cell values mentioned in the question. The hybrid sequence is encoded by BERT with minimal subsequent layers and the text-DB contextualization is realized via the fine-tuned deep attention in BERT. Combined with a pointer-generator decoder with schema-consistency driven search space pruning, BRIDGE attained state-of-the-art performance on popular cross-DB text-to-SQL benchmarks, Spider (71.1\% dev, 67.5\% test with ensemble model) and WikiSQL (92.6\% dev, 91.9\% test). Our analysis shows that BRIDGE effectively captures the desired cross-modal dependencies and has the potential to generalize to more text-DB related tasks. Our implementation is available at \url{https://github.com/salesforce/TabularSemanticParsing}.
Catastrophic Fisher Explosion: Early Phase Fisher Matrix Impacts Generalization
Dec 28, 2020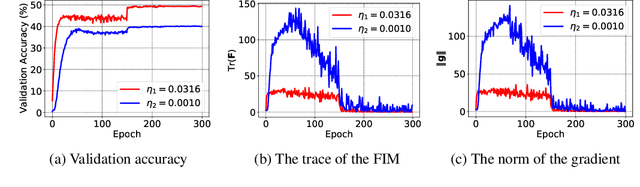



The early phase of training has been shown to be important in two ways for deep neural networks. First, the degree of regularization in this phase significantly impacts the final generalization. Second, it is accompanied by a rapid change in the local loss curvature influenced by regularization choices. Connecting these two findings, we show that stochastic gradient descent (SGD) implicitly penalizes the trace of the Fisher Information Matrix (FIM) from the beginning of training. We argue it is an implicit regularizer in SGD by showing that explicitly penalizing the trace of the FIM can significantly improve generalization. We further show that the early value of the trace of the FIM correlates strongly with the final generalization. We highlight that in the absence of implicit or explicit regularization, the trace of the FIM can increase to a large value early in training, to which we refer as catastrophic Fisher explosion. Finally, to gain insight into the regularization effect of penalizing the trace of the FIM, we show that 1) it limits memorization by reducing the learning speed of examples with noisy labels more than that of the clean examples, and 2) trajectories with a low initial trace of the FIM end in flat minima, which are commonly associated with good generalization.
Discriminative Nearest Neighbor Few-Shot Intent Detection by Transferring Natural Language Inference
Oct 25, 2020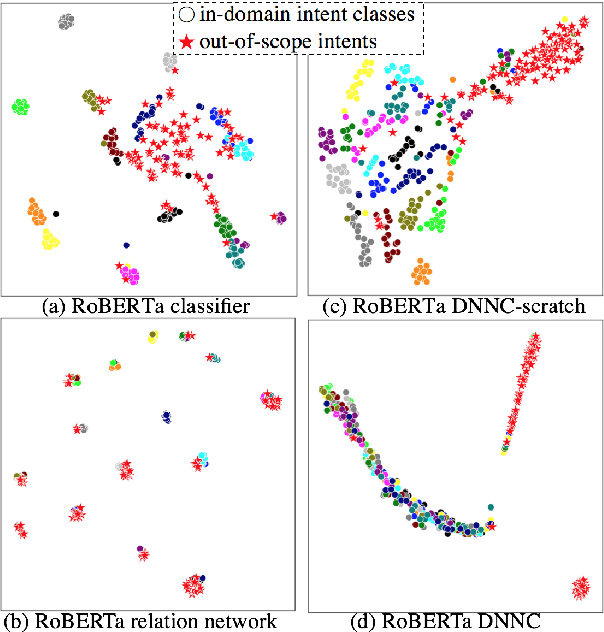

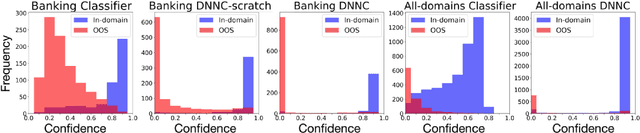
Intent detection is one of the core components of goal-oriented dialog systems, and detecting out-of-scope (OOS) intents is also a practically important skill. Few-shot learning is attracting much attention to mitigate data scarcity, but OOS detection becomes even more challenging. In this paper, we present a simple yet effective approach, discriminative nearest neighbor classification with deep self-attention. Unlike softmax classifiers, we leverage BERT-style pairwise encoding to train a binary classifier that estimates the best matched training example for a user input. We propose to boost the discriminative ability by transferring a natural language inference (NLI) model. Our extensive experiments on a large-scale multi-domain intent detection task show that our method achieves more stable and accurate in-domain and OOS detection accuracy than RoBERTa-based classifiers and embedding-based nearest neighbor approaches. More notably, the NLI transfer enables our 10-shot model to perform competitively with 50-shot or even full-shot classifiers, while we can keep the inference time constant by leveraging a faster embedding retrieval model.
Online Structured Meta-learning
Oct 22, 2020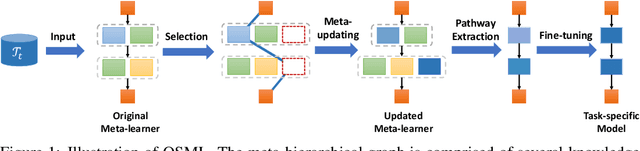
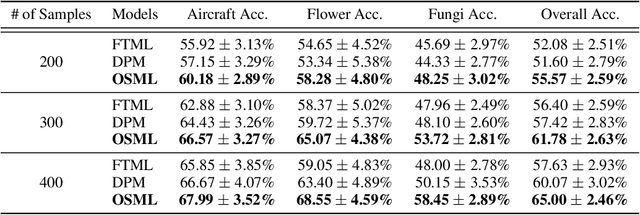
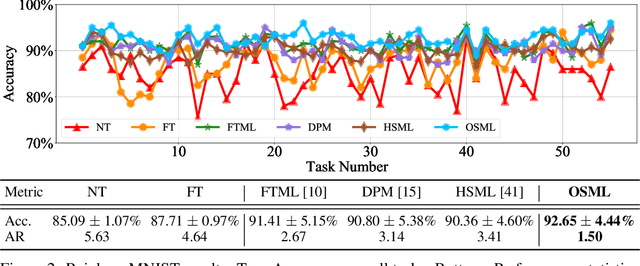
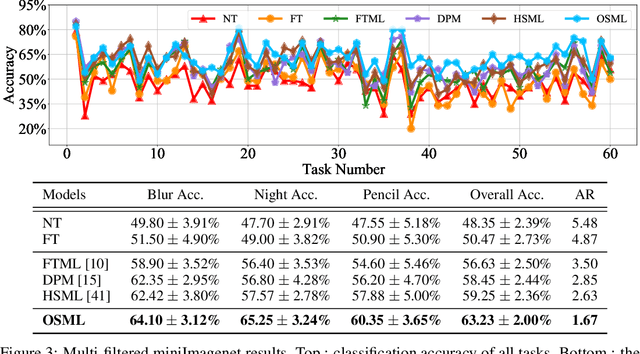
Learning quickly is of great importance for machine intelligence deployed in online platforms. With the capability of transferring knowledge from learned tasks, meta-learning has shown its effectiveness in online scenarios by continuously updating the model with the learned prior. However, current online meta-learning algorithms are limited to learn a globally-shared meta-learner, which may lead to sub-optimal results when the tasks contain heterogeneous information that are distinct by nature and difficult to share. We overcome this limitation by proposing an online structured meta-learning (OSML) framework. Inspired by the knowledge organization of human and hierarchical feature representation, OSML explicitly disentangles the meta-learner as a meta-hierarchical graph with different knowledge blocks. When a new task is encountered, it constructs a meta-knowledge pathway by either utilizing the most relevant knowledge blocks or exploring new blocks. Through the meta-knowledge pathway, the model is able to quickly adapt to the new task. In addition, new knowledge is further incorporated into the selected blocks. Experiments on three datasets demonstrate the effectiveness and interpretability of our proposed framework in the context of both homogeneous and heterogeneous tasks.
Explaining and Improving Model Behavior with k Nearest Neighbor Representations
Oct 18, 2020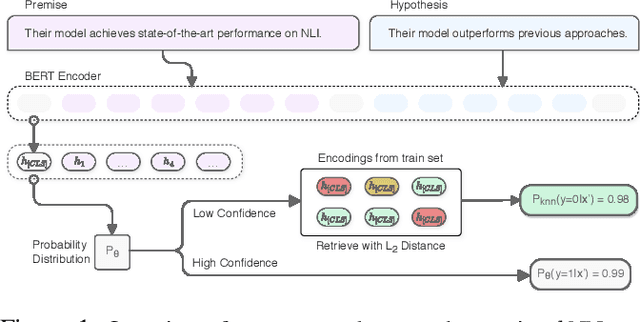



Interpretability techniques in NLP have mainly focused on understanding individual predictions using attention visualization or gradient-based saliency maps over tokens. We propose using k nearest neighbor (kNN) representations to identify training examples responsible for a model's predictions and obtain a corpus-level understanding of the model's behavior. Apart from interpretability, we show that kNN representations are effective at uncovering learned spurious associations, identifying mislabeled examples, and improving the fine-tuned model's performance. We focus on Natural Language Inference (NLI) as a case study and experiment with multiple datasets. Our method deploys backoff to kNN for BERT and RoBERTa on examples with low model confidence without any update to the model parameters. Our results indicate that the kNN approach makes the finetuned model more robust to adversarial inputs.
Explaining Creative Artifacts
Oct 14, 2020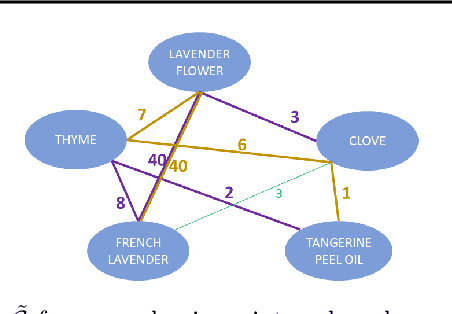
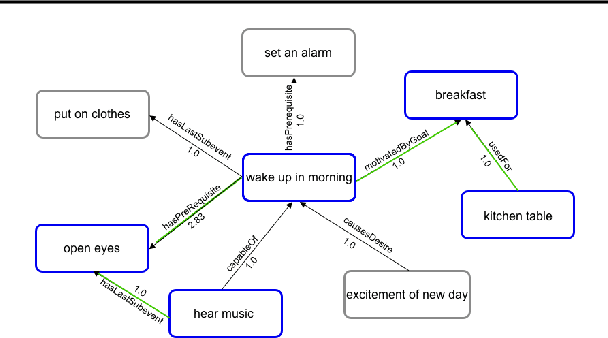
Human creativity is often described as the mental process of combining associative elements into a new form, but emerging computational creativity algorithms may not operate in this manner. Here we develop an inverse problem formulation to deconstruct the products of combinatorial and compositional creativity into associative chains as a form of post-hoc interpretation that matches the human creative process. In particular, our formulation is structured as solving a traveling salesman problem through a knowledge graph of associative elements. We demonstrate our approach using an example in explaining culinary computational creativity where there is an explicit semantic structure, and two examples in language generation where we either extract explicit concepts that map to a knowledge graph or we consider distances in a word embedding space. We close by casting the length of an optimal traveling salesman path as a measure of novelty in creativity.