 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHETFORMER: Heterogeneous Transformer with Sparse Attention for Long-Text Extractive Summarization
Oct 19, 2021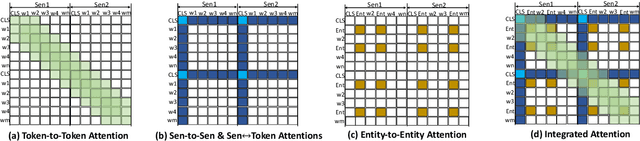
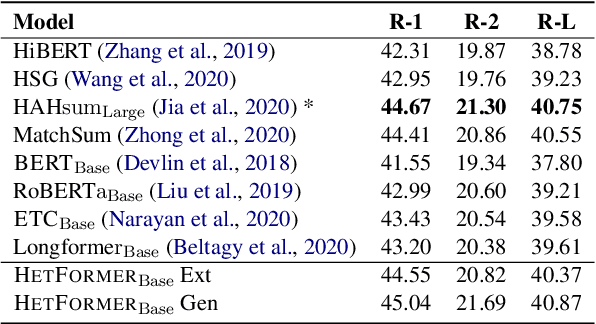
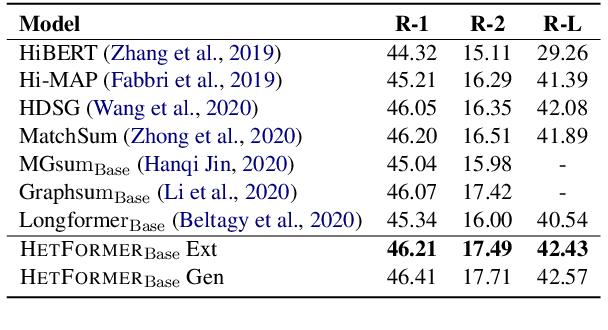

To capture the semantic graph structure from raw text, most existing summarization approaches are built on GNNs with a pre-trained model. However, these methods suffer from cumbersome procedures and inefficient computations for long-text documents. To mitigate these issues, this paper proposes HETFORMER, a Transformer-based pre-trained model with multi-granularity sparse attentions for long-text extractive summarization. Specifically, we model different types of semantic nodes in raw text as a potential heterogeneous graph and directly learn heterogeneous relationships (edges) among nodes by Transformer. Extensive experiments on both single- and multi-document summarization tasks show that HETFORMER achieves state-of-the-art performance in Rouge F1 while using less memory and fewer parameters.
Are Pretrained Transformers Robust in Intent Classification? A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection
Jun 08, 2021
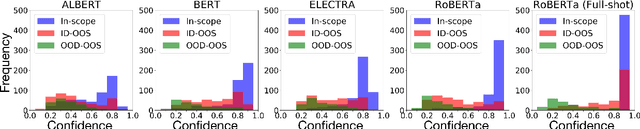
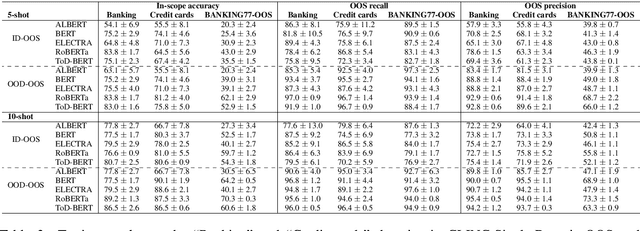
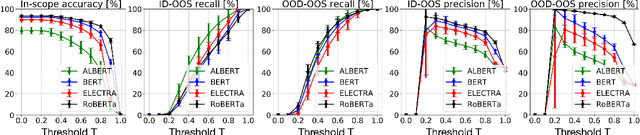
Pretrained Transformer-based models were reported to be robust in intent classification. In this work, we first point out the importance of in-domain out-of-scope detection in few-shot intent recognition tasks and then illustrate the vulnerability of pretrained Transformer-based models against samples that are in-domain but out-of-scope (ID-OOS). We empirically show that pretrained models do not perform well on both ID-OOS examples and general out-of-scope examples, especially on fine-grained few-shot intent detection tasks. To figure out how the models mistakenly classify ID-OOS intents as in-scope intents, we further conduct analysis on confidence scores and the overlapping keywords and provide several prospective directions for future work. We release the relevant resources to facilitate future research.
Enriching Non-Autoregressive Transformer with Syntactic and SemanticStructures for Neural Machine Translation
Jan 22, 2021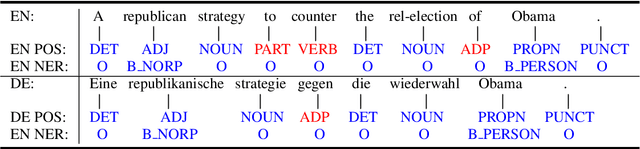
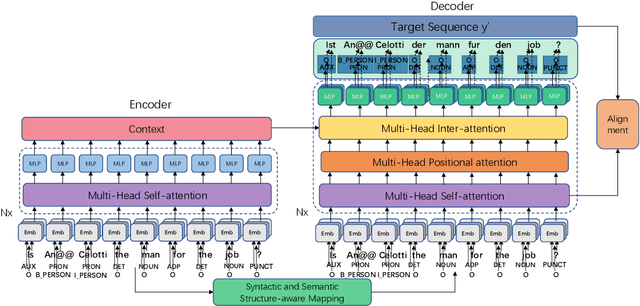
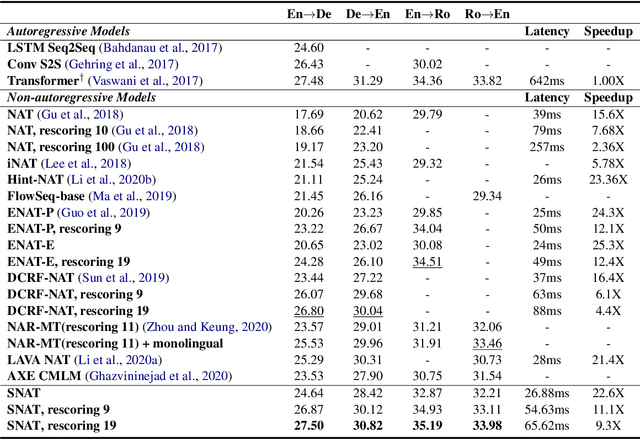

The non-autoregressive models have boosted the efficiency of neural machine translation through parallelized decoding at the cost of effectiveness when comparing with the autoregressive counterparts. In this paper, we claim that the syntactic and semantic structures among natural language are critical for non-autoregressive machine translation and can further improve the performance. However, these structures are rarely considered in the existing non-autoregressive models. Inspired by this intuition, we propose to incorporate the explicit syntactic and semantic structures of languages into a non-autoregressive Transformer, for the task of neural machine translation. Moreover, we also consider the intermediate latent alignment within target sentences to better learn the long-term token dependencies. Experimental results on two real-world datasets (i.e., WMT14 En-De and WMT16 En-Ro) show that our model achieves a significantly faster speed, as well as keeps the translation quality when compared with several state-of-the-art non-autoregressive models.
Discriminative Nearest Neighbor Few-Shot Intent Detection by Transferring Natural Language Inference
Oct 25, 2020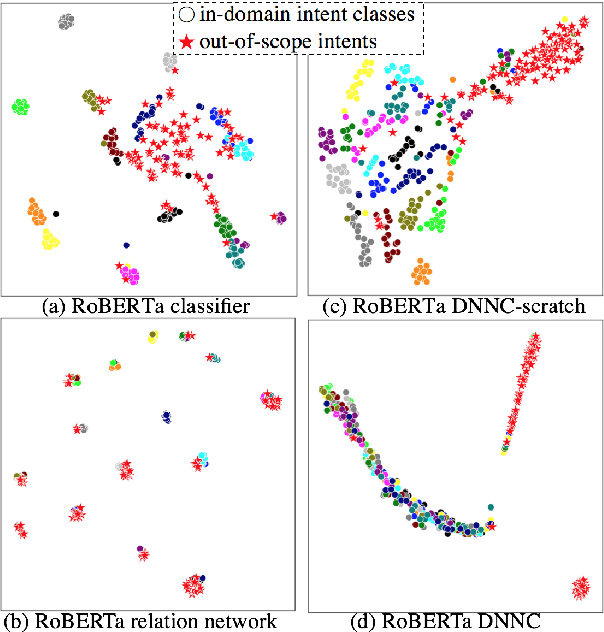

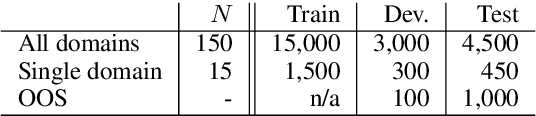
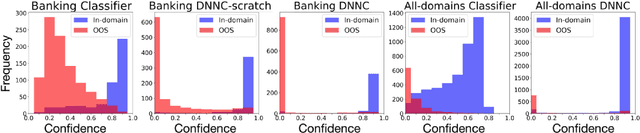
Intent detection is one of the core components of goal-oriented dialog systems, and detecting out-of-scope (OOS) intents is also a practically important skill. Few-shot learning is attracting much attention to mitigate data scarcity, but OOS detection becomes even more challenging. In this paper, we present a simple yet effective approach, discriminative nearest neighbor classification with deep self-attention. Unlike softmax classifiers, we leverage BERT-style pairwise encoding to train a binary classifier that estimates the best matched training example for a user input. We propose to boost the discriminative ability by transferring a natural language inference (NLI) model. Our extensive experiments on a large-scale multi-domain intent detection task show that our method achieves more stable and accurate in-domain and OOS detection accuracy than RoBERTa-based classifiers and embedding-based nearest neighbor approaches. More notably, the NLI transfer enables our 10-shot model to perform competitively with 50-shot or even full-shot classifiers, while we can keep the inference time constant by leveraging a faster embedding retrieval model.
Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking
Oct 10, 2019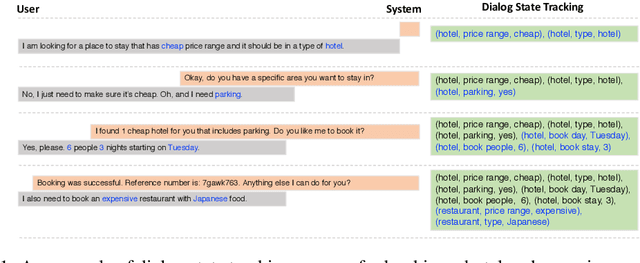



Dialog State Tracking (DST) is a core component in task-oriented dialog systems. Existing approaches for DST usually fall into two categories, i.e, the picklist-based and span-based. From one hand, the picklist-based methods perform classifications for each slot over a candidate-value list, under the condition that a pre-defined ontology is accessible. However, it is impractical in industry since it is hard to get full access to the ontology. On the other hand, the span-based methods track values for each slot through finding text spans in the dialog context. However, due to the diversity of value descriptions, it is hard to find a particular string in the dialog context. To mitigate these issues, this paper proposes a Dual Strategy for DST (DS-DST) to borrow advantages from both the picklist-based and span-based methods, by classifying over a picklist or finding values from a slot span. Empirical results show that DS-DST achieves the state-of-the-art scores in terms of joint accuracy, i.e., 51.2% on the MultiWOZ 2.1 dataset, and 53.3% when the full ontology is accessible.
Multi-Modal Generative Adversarial Network for Short Product Title Generation in Mobile E-Commerce
Apr 03, 2019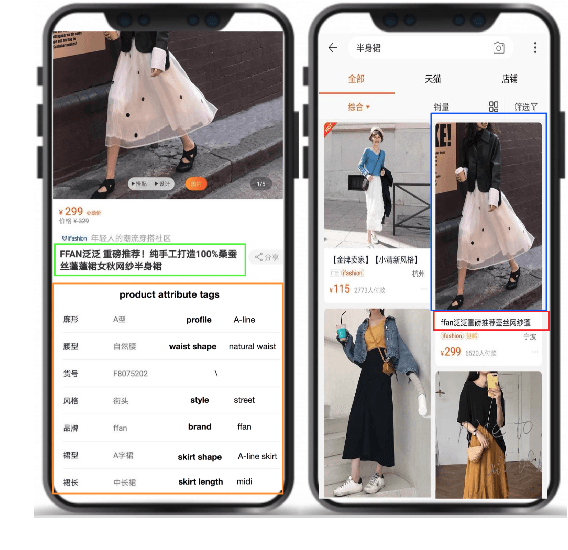
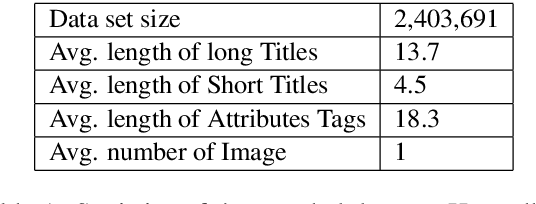
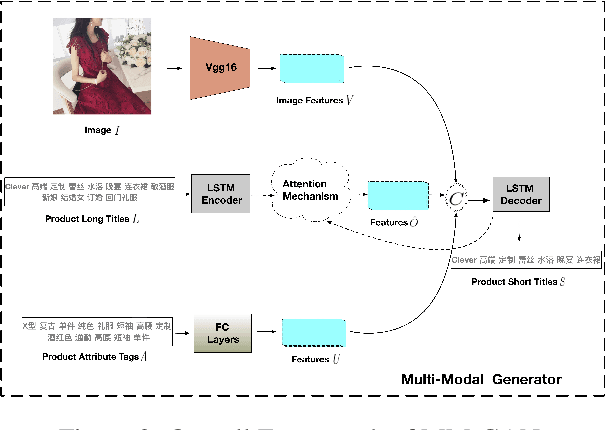

Nowadays, more and more customers browse and purchase products in favor of using mobile E-Commerce Apps such as Taobao and Amazon. Since merchants are usually inclined to describe redundant and over-informative product titles to attract attentions from customers, it is important to concisely display short product titles on limited screen of mobile phones. To address this discrepancy, previous studies mainly consider textual information of long product titles and lacks of human-like view during training and evaluation process. In this paper, we propose a Multi-Modal Generative Adversarial Network (MM-GAN) for short product title generation in E-Commerce, which innovatively incorporates image information and attribute tags from product, as well as textual information from original long titles. MM-GAN poses short title generation as a reinforcement learning process, where the generated titles are evaluated by the discriminator in a human-like view. Extensive experiments on a large-scale E-Commerce dataset demonstrate that our algorithm outperforms other state-of-the-art methods. Moreover, we deploy our model into a real-world online E-Commerce environment and effectively boost the performance of click through rate and click conversion rate by 1.66% and 1.87%, respectively.