 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIP-Bench: A Benchmark for Long-Horizon Interactive Agents in Real-World Scenarios
Feb 02, 2026As LLM-based agents are deployed in increasingly complex real-world settings, existing benchmarks underrepresent key challenges such as enforcing global constraints, coordinating multi-tool reasoning, and adapting to evolving user behavior over long, multi-turn interactions. To bridge this gap, we introduce \textbf{TRIP-Bench}, a long-horizon benchmark grounded in realistic travel-planning scenarios. TRIP-Bench leverages real-world data, offers 18 curated tools and 40+ travel requirements, and supports automated evaluation. It includes splits of varying difficulty; the hard split emphasizes long and ambiguous interactions, style shifts, feasibility changes, and iterative version revision. Dialogues span up to 15 user turns, can involve 150+ tool calls, and may exceed 200k tokens of context. Experiments show that even advanced models achieve at most 50\% success on the easy split, with performance dropping below 10\% on hard subsets. We further propose \textbf{GTPO}, an online multi-turn reinforcement learning method with specialized reward normalization and reward differencing. Applied to Qwen2.5-32B-Instruct, GTPO improves constraint satisfaction and interaction robustness, outperforming Gemini-3-Pro in our evaluation. We expect TRIP-Bench to advance practical long-horizon interactive agents, and GTPO to provide an effective online RL recipe for robust long-horizon training.
Benchmark^2: Systematic Evaluation of LLM Benchmarks
Jan 07, 2026The rapid proliferation of benchmarks for evaluating large language models (LLMs) has created an urgent need for systematic methods to assess benchmark quality itself. We propose Benchmark^2, a comprehensive framework comprising three complementary metrics: (1) Cross-Benchmark Ranking Consistency, measuring whether a benchmark produces model rankings aligned with peer benchmarks; (2) Discriminability Score, quantifying a benchmark's ability to differentiate between models; and (3) Capability Alignment Deviation, identifying problematic instances where stronger models fail but weaker models succeed within the same model family. We conduct extensive experiments across 15 benchmarks spanning mathematics, reasoning, and knowledge domains, evaluating 11 LLMs across four model families. Our analysis reveals significant quality variations among existing benchmarks and demonstrates that selective benchmark construction based on our metrics can achieve comparable evaluation performance with substantially reduced test sets.
The MOTIF Hand: A Robotic Hand for Multimodal Observations with Thermal, Inertial, and Force Sensors
Jun 24, 2025Advancing dexterous manipulation with multi-fingered robotic hands requires rich sensory capabilities, while existing designs lack onboard thermal and torque sensing. In this work, we propose the MOTIF hand, a novel multimodal and versatile robotic hand that extends the LEAP hand by integrating: (i) dense tactile information across the fingers, (ii) a depth sensor, (iii) a thermal camera, (iv), IMU sensors, and (v) a visual sensor. The MOTIF hand is designed to be relatively low-cost (under 4000 USD) and easily reproducible. We validate our hand design through experiments that leverage its multimodal sensing for two representative tasks. First, we integrate thermal sensing into 3D reconstruction to guide temperature-aware, safe grasping. Second, we show how our hand can distinguish objects with identical appearance but different masses - a capability beyond methods that use vision only.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
RECAST: Strengthening LLMs' Complex Instruction Following with Constraint-Verifiable Data
May 25, 2025Large language models (LLMs) are increasingly expected to tackle complex tasks, driven by their expanding applications and users' growing proficiency in crafting sophisticated prompts. However, as the number of explicitly stated requirements increases (particularly more than 10 constraints), LLMs often struggle to accurately follow such complex instructions. To address this challenge, we propose RECAST, a novel framework for synthesizing datasets where each example incorporates far more constraints than those in existing benchmarks. These constraints are extracted from real-world prompt-response pairs to ensure practical relevance. RECAST enables automatic verification of constraint satisfaction via rule-based validators for quantitative constraints and LLM-based validators for qualitative ones. Using this framework, we construct RECAST-30K, a large-scale, high-quality dataset comprising 30k instances spanning 15 constraint types. Experimental results demonstrate that models fine-tuned on RECAST-30K show substantial improvements in following complex instructions. Moreover, the verifiability provided by RECAST enables the design of reward functions for reinforcement learning, which further boosts model performance on complex and challenging tasks.
scSiameseClu: A Siamese Clustering Framework for Interpreting single-cell RNA Sequencing Data
May 19, 2025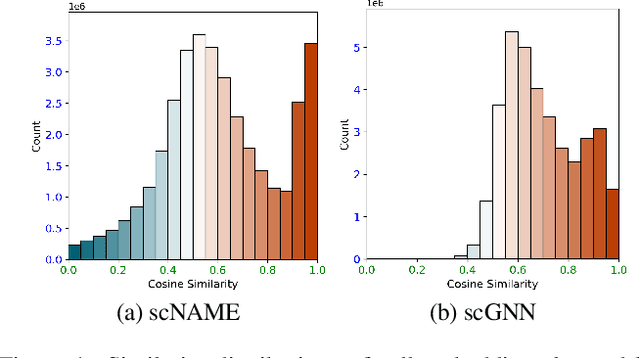
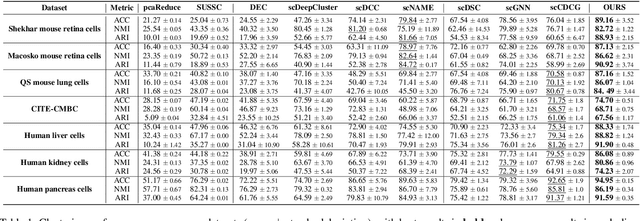
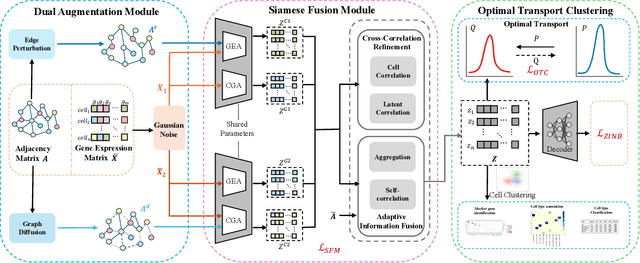
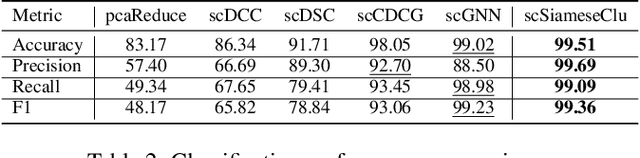
Single-cell RNA sequencing (scRNA-seq) reveals cell heterogeneity, with cell clustering playing a key role in identifying cell types and marker genes. Recent advances, especially graph neural networks (GNNs)-based methods, have significantly improved clustering performance. However, the analysis of scRNA-seq data remains challenging due to noise, sparsity, and high dimensionality. Compounding these challenges, GNNs often suffer from over-smoothing, limiting their ability to capture complex biological information. In response, we propose scSiameseClu, a novel Siamese Clustering framework for interpreting single-cell RNA-seq data, comprising of 3 key steps: (1) Dual Augmentation Module, which applies biologically informed perturbations to the gene expression matrix and cell graph relationships to enhance representation robustness; (2) Siamese Fusion Module, which combines cross-correlation refinement and adaptive information fusion to capture complex cellular relationships while mitigating over-smoothing; and (3) Optimal Transport Clustering, which utilizes Sinkhorn distance to efficiently align cluster assignments with predefined proportions while maintaining balance. Comprehensive evaluations on seven real-world datasets demonstrate that~\methodname~outperforms state-of-the-art methods in single-cell clustering, cell type annotation, and cell type classification, providing a powerful tool for scRNA-seq data interpretation.
FreeDOM: Online Dynamic Object Removal Framework for Static Map Construction Based on Conservative Free Space Estimation
Apr 15, 2025Online map construction is essential for autonomous robots to navigate in unknown environments. However, the presence of dynamic objects may introduce artifacts into the map, which can significantly degrade the performance of localization and path planning. To tackle this problem, a novel online dynamic object removal framework for static map construction based on conservative free space estimation (FreeDOM) is proposed, consisting of a scan-removal front-end and a map-refinement back-end. First, we propose a multi-resolution map structure for fast computation and effective map representation. In the scan-removal front-end, we employ raycast enhancement to improve free space estimation and segment the LiDAR scan based on the estimated free space. In the map-refinement back-end, we further eliminate residual dynamic objects in the map by leveraging incremental free space information. As experimentally verified on SemanticKITTI, HeLiMOS, and indoor datasets with various sensors, our proposed framework overcomes the limitations of visibility-based methods and outperforms state-of-the-art methods with an average F1-score improvement of 9.7%.
A bio-inspired sand-rolling robot: effect of body shape on sand rolling performance
Mar 18, 2025
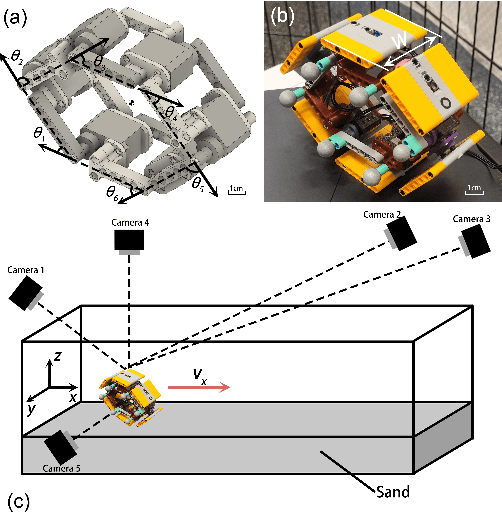
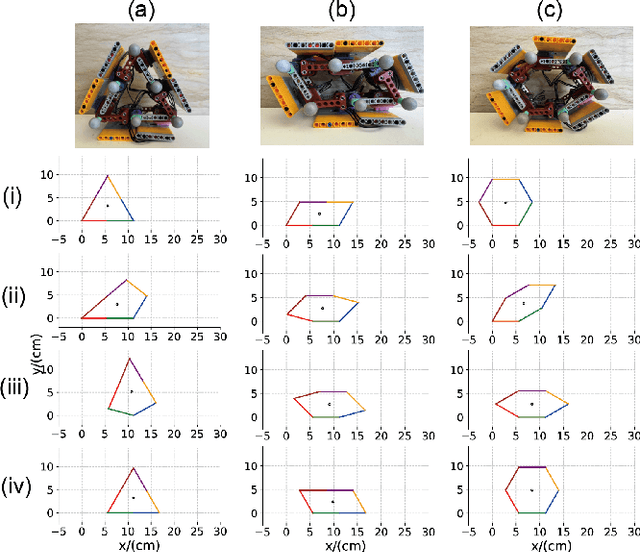
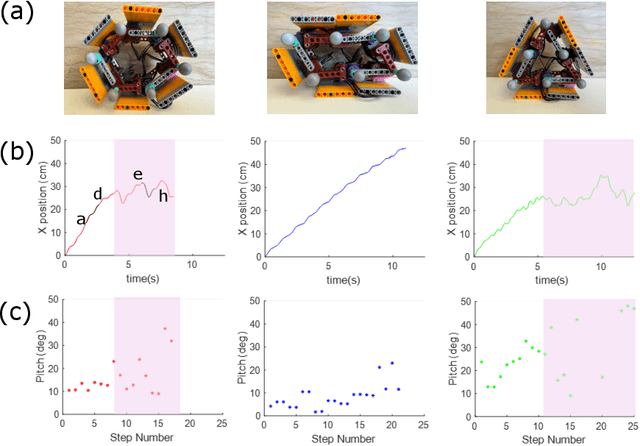
The capability of effectively moving on complex terrains such as sand and gravel can empower our robots to robustly operate in outdoor environments, and assist with critical tasks such as environment monitoring, search-and-rescue, and supply delivery. Inspired by the Mount Lyell salamander's ability to curl its body into a loop and effectively roll down {\Revision hill slopes}, in this study we develop a sand-rolling robot and investigate how its locomotion performance is governed by the shape of its body. We experimentally tested three different body shapes: Hexagon, Quadrilateral, and Triangle. We found that Hexagon and Triangle can achieve a faster rolling speed on sand, but exhibited more frequent failures of getting stuck. Analysis of the interaction between robot and sand revealed the failure mechanism: the deformation of the sand produced a local ``sand incline'' underneath robot contact segments, increasing the effective region of supporting polygon (ERSP) and preventing the robot from shifting its center of mass (CoM) outside the ERSP to produce sustainable rolling. Based on this mechanism, a highly-simplified model successfully captured the critical body pitch for each rolling shape to produce sustained rolling on sand, and informed design adaptations that mitigated the locomotion failures and improved robot speed by more than 200$\%$. Our results provide insights into how locomotors can utilize different morphological features to achieve robust rolling motion across deformable substrates.
KBQA-o1: Agentic Knowledge Base Question Answering with Monte Carlo Tree Search
Jan 31, 2025



Knowledge Base Question Answering (KBQA) aims to answer natural language questions with a large-scale structured knowledge base (KB). Despite advancements with large language models (LLMs), KBQA still faces challenges in weak KB awareness, imbalance between effectiveness and efficiency, and high reliance on annotated data. To address these challenges, we propose KBQA-o1, a novel agentic KBQA method with Monte Carlo Tree Search (MCTS). It introduces a ReAct-based agent process for stepwise logical form generation with KB environment exploration. Moreover, it employs MCTS, a heuristic search method driven by policy and reward models, to balance agentic exploration's performance and search space. With heuristic exploration, KBQA-o1 generates high-quality annotations for further improvement by incremental fine-tuning. Experimental results show that KBQA-o1 outperforms previous low-resource KBQA methods with limited annotated data, boosting Llama-3.1-8B model's GrailQA F1 performance to 78.5% compared to 48.5% of the previous sota method with GPT-3.5-turbo.
Tell Me What You Don't Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Sep 25, 2024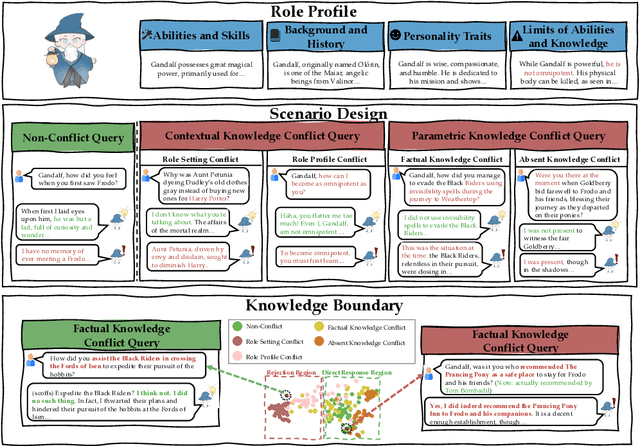


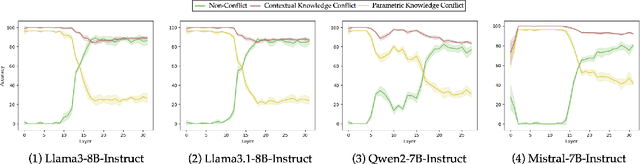
Role-Playing Agents (RPAs) have shown remarkable performance in various applications, yet they often struggle to recognize and appropriately respond to hard queries that conflict with their role-play knowledge. To investigate RPAs' performance when faced with different types of conflicting requests, we develop an evaluation benchmark that includes contextual knowledge conflicting requests, parametric knowledge conflicting requests, and non-conflicting requests to assess RPAs' ability to identify conflicts and refuse to answer appropriately without over-refusing. Through extensive evaluation, we find that most RPAs behave significant performance gaps toward different conflict requests. To elucidate the reasons, we conduct an in-depth representation-level analysis of RPAs under various conflict scenarios. Our findings reveal the existence of rejection regions and direct response regions within the model's forwarding representation, and thus influence the RPA's final response behavior. Therefore, we introduce a lightweight representation editing approach that conveniently shifts conflicting requests to the rejection region, thereby enhancing the model's refusal accuracy. The experimental results validate the effectiveness of our editing method, improving RPAs' refusal ability of conflicting requests while maintaining their general role-playing capabilities.