 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRIBench: Benchmarking Vision-Language Models for Real-Time Human Perception in Human-Robot Interaction
Jun 25, 2025Real-time human perception is crucial for effective human-robot interaction (HRI). Large vision-language models (VLMs) offer promising generalizable perceptual capabilities but often suffer from high latency, which negatively impacts user experience and limits VLM applicability in real-world scenarios. To systematically study VLM capabilities in human perception for HRI and performance-latency trade-offs, we introduce HRIBench, a visual question-answering (VQA) benchmark designed to evaluate VLMs across a diverse set of human perceptual tasks critical for HRI. HRIBench covers five key domains: (1) non-verbal cue understanding, (2) verbal instruction understanding, (3) human-robot object relationship understanding, (4) social navigation, and (5) person identification. To construct HRIBench, we collected data from real-world HRI environments to curate questions for non-verbal cue understanding, and leveraged publicly available datasets for the remaining four domains. We curated 200 VQA questions for each domain, resulting in a total of 1000 questions for HRIBench. We then conducted a comprehensive evaluation of both state-of-the-art closed-source and open-source VLMs (N=11) on HRIBench. Our results show that, despite their generalizability, current VLMs still struggle with core perceptual capabilities essential for HRI. Moreover, none of the models within our experiments demonstrated a satisfactory performance-latency trade-off suitable for real-time deployment, underscoring the need for future research on developing smaller, low-latency VLMs with improved human perception capabilities. HRIBench and our results can be found in this Github repository: https://github.com/interaction-lab/HRIBench.
The MOTIF Hand: A Robotic Hand for Multimodal Observations with Thermal, Inertial, and Force Sensors
Jun 24, 2025Advancing dexterous manipulation with multi-fingered robotic hands requires rich sensory capabilities, while existing designs lack onboard thermal and torque sensing. In this work, we propose the MOTIF hand, a novel multimodal and versatile robotic hand that extends the LEAP hand by integrating: (i) dense tactile information across the fingers, (ii) a depth sensor, (iii) a thermal camera, (iv), IMU sensors, and (v) a visual sensor. The MOTIF hand is designed to be relatively low-cost (under 4000 USD) and easily reproducible. We validate our hand design through experiments that leverage its multimodal sensing for two representative tasks. First, we integrate thermal sensing into 3D reconstruction to guide temperature-aware, safe grasping. Second, we show how our hand can distinguish objects with identical appearance but different masses - a capability beyond methods that use vision only.
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
GPT-Fabric: Folding and Smoothing Fabric by Leveraging Pre-Trained Foundation Models
Jun 14, 2024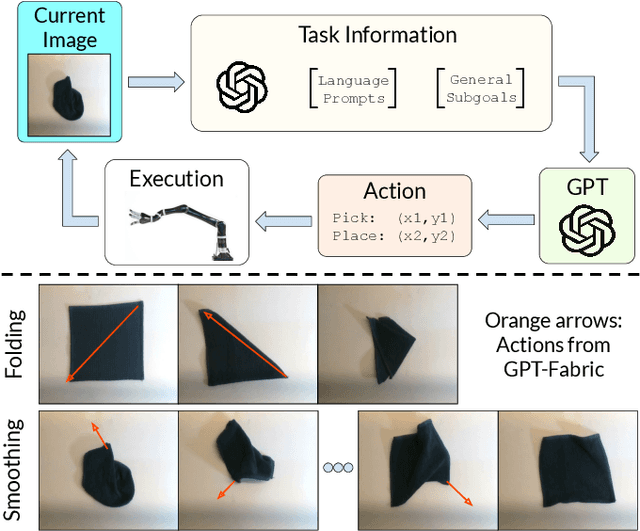
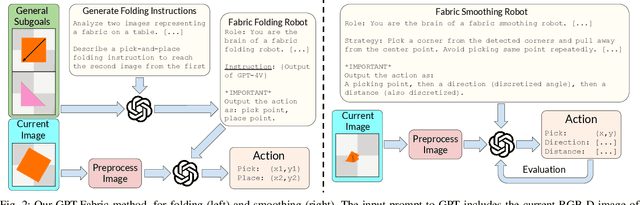
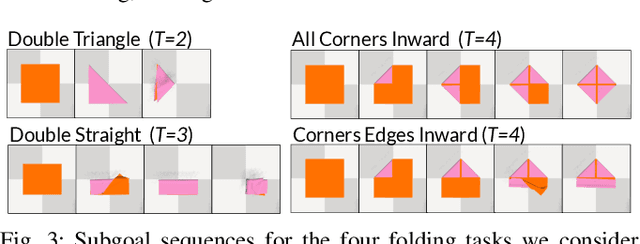
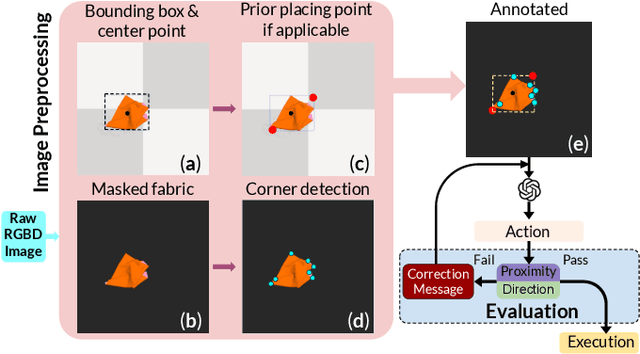
Fabric manipulation has applications in folding blankets, handling patient clothing, and protecting items with covers. It is challenging for robots to perform fabric manipulation since fabrics have infinite-dimensional configuration spaces, complex dynamics, and may be in folded or crumpled configurations with severe self-occlusions. Prior work on robotic fabric manipulation relies either on heavily engineered setups or learning-based approaches that create and train on robot-fabric interaction data. In this paper, we propose GPT-Fabric for the canonical tasks of fabric folding and smoothing, where GPT directly outputs an action informing a robot where to grasp and pull a fabric. We perform extensive experiments in simulation to test GPT-Fabric against prior state of the art methods for folding and smoothing. We obtain comparable or better performance to most methods even without explicitly training on a fabric-specific dataset (i.e., zero-shot manipulation). Furthermore, we apply GPT-Fabric in physical experiments over 12 folding and 10 smoothing rollouts. Our results suggest that GPT-Fabric is a promising approach for high-precision fabric manipulation tasks.
Instant Photorealistic Style Transfer: A Lightweight and Adaptive Approach
Sep 18, 2023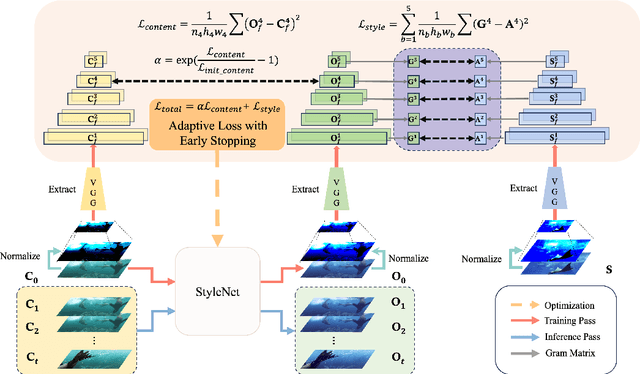

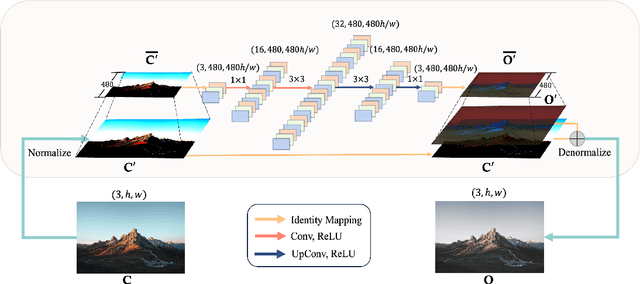

In this paper, we propose an Instant Photorealistic Style Transfer (IPST) approach, designed to achieve instant photorealistic style transfer on super-resolution inputs without the need for pre-training on pair-wise datasets or imposing extra constraints. Our method utilizes a lightweight StyleNet to enable style transfer from a style image to a content image while preserving non-color information. To further enhance the style transfer process, we introduce an instance-adaptive optimization to prioritize the photorealism of outputs and accelerate the convergence of the style network, leading to a rapid training completion within seconds. Moreover, IPST is well-suited for multi-frame style transfer tasks, as it retains temporal and multi-view consistency of the multi-frame inputs such as video and Neural Radiance Field (NeRF). Experimental results demonstrate that IPST requires less GPU memory usage, offers faster multi-frame transfer speed, and generates photorealistic outputs, making it a promising solution for various photorealistic transfer applications.
The Design and Realization of Multi-agent Obstacle Avoidance based on Reinforcement Learning
Oct 24, 2022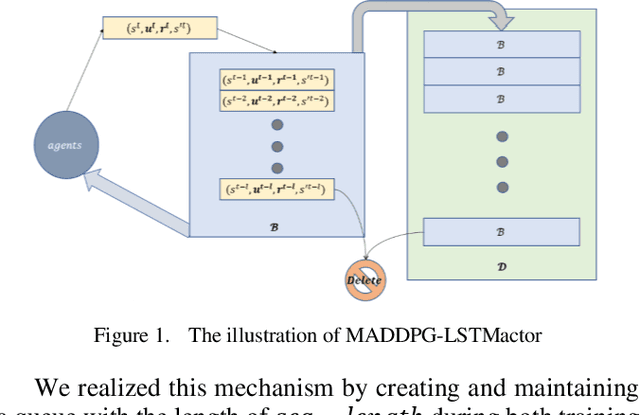
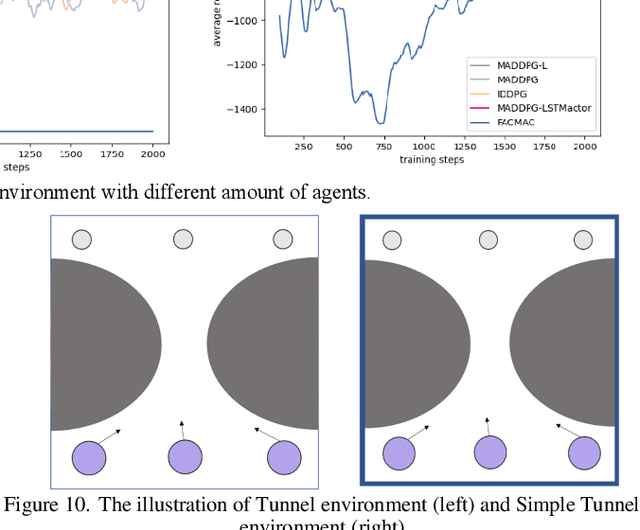
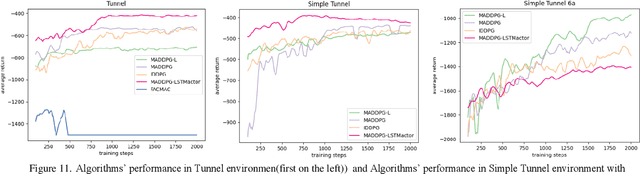
Intelligence agents and multi-agent systems play important roles in scenes like the control system of grouped drones, and multi-agent navigation and obstacle avoidance which is the foundational function of advanced application has great importance. In multi-agent navigation and obstacle avoidance tasks, the decision-making interactions and dynamic changes of agents are difficult for traditional route planning algorithms or reinforcement learning algorithms with the increased complexity of the environment. The classical multi-agent reinforcement learning algorithm, Multi-agent deep deterministic policy gradient(MADDPG), solved precedent algorithms' problems of having unstationary training process and unable to deal with environment randomness. However, MADDPG ignored the temporal message hidden beneath agents' interaction with the environment. Besides, due to its CTDE technique which let each agent's critic network to calculate over all agents' action and the whole environment information, it lacks ability to scale to larger amount of agents. To deal with MADDPG's ignorance of the temporal information of the data, this article proposes a new algorithm called MADDPG-LSTMactor, which combines MADDPG with Long short term memory (LSTM). By using agent's observations of continuous timesteps as the input of its policy network, it allows the LSTM layer to process the hidden temporal message. Experimental result demonstrated that this algorithm had better performance in scenarios where the amount of agents is small. Besides, to solve MADDPG's drawback of not being efficient in scenarios where agents are too many, this article puts forward a light-weight MADDPG (MADDPG-L) algorithm, which simplifies the input of critic network. The result of experiments showed that this algorithm had better performance than MADDPG when the amount of agents was large.