 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Design and Realization of Multi-agent Obstacle Avoidance based on Reinforcement Learning
Paper and Code
Oct 24, 2022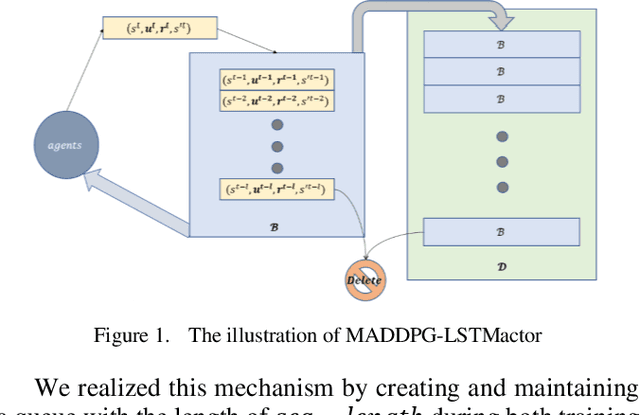
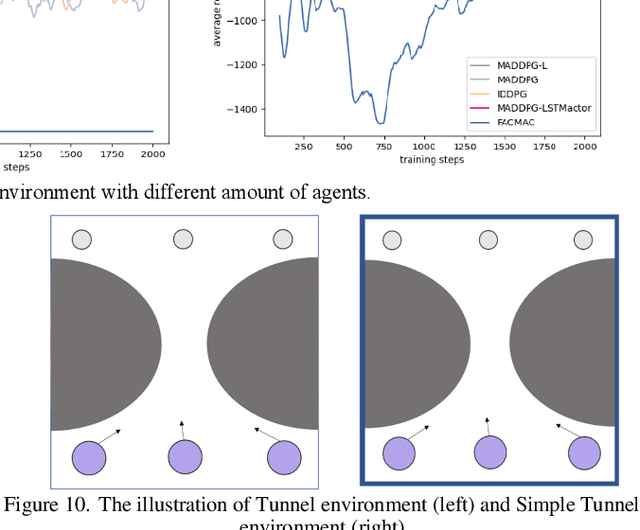
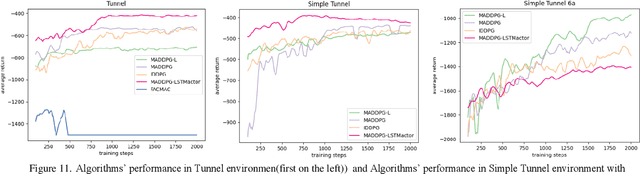
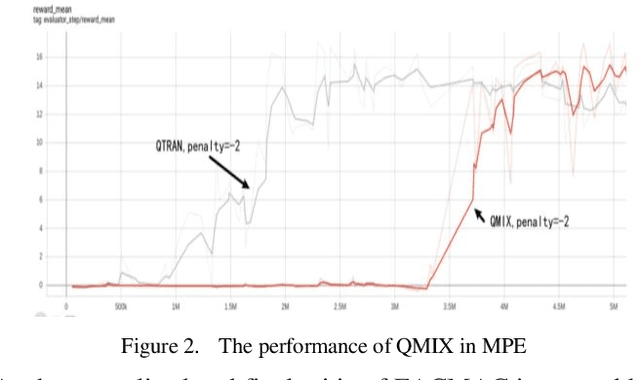
Intelligence agents and multi-agent systems play important roles in scenes like the control system of grouped drones, and multi-agent navigation and obstacle avoidance which is the foundational function of advanced application has great importance. In multi-agent navigation and obstacle avoidance tasks, the decision-making interactions and dynamic changes of agents are difficult for traditional route planning algorithms or reinforcement learning algorithms with the increased complexity of the environment. The classical multi-agent reinforcement learning algorithm, Multi-agent deep deterministic policy gradient(MADDPG), solved precedent algorithms' problems of having unstationary training process and unable to deal with environment randomness. However, MADDPG ignored the temporal message hidden beneath agents' interaction with the environment. Besides, due to its CTDE technique which let each agent's critic network to calculate over all agents' action and the whole environment information, it lacks ability to scale to larger amount of agents. To deal with MADDPG's ignorance of the temporal information of the data, this article proposes a new algorithm called MADDPG-LSTMactor, which combines MADDPG with Long short term memory (LSTM). By using agent's observations of continuous timesteps as the input of its policy network, it allows the LSTM layer to process the hidden temporal message. Experimental result demonstrated that this algorithm had better performance in scenarios where the amount of agents is small. Besides, to solve MADDPG's drawback of not being efficient in scenarios where agents are too many, this article puts forward a light-weight MADDPG (MADDPG-L) algorithm, which simplifies the input of critic network. The result of experiments showed that this algorithm had better performance than MADDPG when the amount of agents was large.