 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA training regime to learn unified representations from complementary breast imaging modalities
Aug 16, 2024



Full Field Digital Mammograms (FFDMs) and Digital Breast Tomosynthesis (DBT) are the two most widely used imaging modalities for breast cancer screening. Although DBT has increased cancer detection compared to FFDM, its widespread adoption in clinical practice has been slowed by increased interpretation times and a perceived decrease in the conspicuity of specific lesion types. Specifically, the non-inferiority of DBT for microcalcifications remains under debate. Due to concerns about the decrease in visual acuity, combined DBT-FFDM acquisitions remain popular, leading to overall increased exam times and radiation dosage. Enabling DBT to provide diagnostic information present in both FFDM and DBT would reduce reliance on FFDM, resulting in a reduction in both quantities. We propose a machine learning methodology that learns high-level representations leveraging the complementary diagnostic signal from both DBT and FFDM. Experiments on a large-scale data set validate our claims and show that our representations enable more accurate breast lesion detection than any DBT- or FFDM-based model.
Generative multitask learning mitigates target-causing confounding
Feb 08, 2022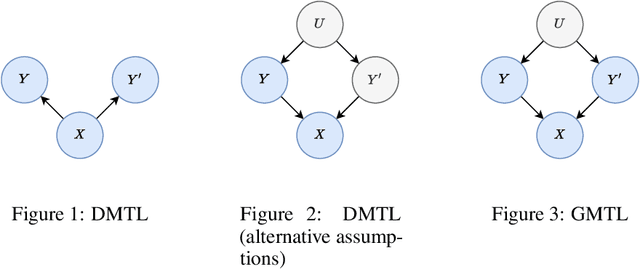


We propose a simple and scalable approach to causal representation learning for multitask learning. Our approach requires minimal modification to existing ML systems, and improves robustness to prior probability shift. The improvement comes from mitigating unobserved confounders that cause the targets, but not the input. We refer to them as target-causing confounders. These confounders induce spurious dependencies between the input and targets. This poses a problem for the conventional approach to multitask learning, due to its assumption that the targets are conditionally independent given the input. Our proposed approach takes into account the dependency between the targets in order to alleviate target-causing confounding. All that is required in addition to usual practice is to estimate the joint distribution of the targets to switch from discriminative to generative classification, and to predict all targets jointly. Our results on the Attributes of People and Taskonomy datasets reflect the conceptual improvement in robustness to prior probability shift.
Catastrophic Fisher Explosion: Early Phase Fisher Matrix Impacts Generalization
Dec 28, 2020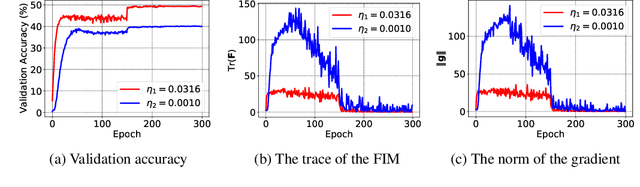



The early phase of training has been shown to be important in two ways for deep neural networks. First, the degree of regularization in this phase significantly impacts the final generalization. Second, it is accompanied by a rapid change in the local loss curvature influenced by regularization choices. Connecting these two findings, we show that stochastic gradient descent (SGD) implicitly penalizes the trace of the Fisher Information Matrix (FIM) from the beginning of training. We argue it is an implicit regularizer in SGD by showing that explicitly penalizing the trace of the FIM can significantly improve generalization. We further show that the early value of the trace of the FIM correlates strongly with the final generalization. We highlight that in the absence of implicit or explicit regularization, the trace of the FIM can increase to a large value early in training, to which we refer as catastrophic Fisher explosion. Finally, to gain insight into the regularization effect of penalizing the trace of the FIM, we show that 1) it limits memorization by reducing the learning speed of examples with noisy labels more than that of the clean examples, and 2) trajectories with a low initial trace of the FIM end in flat minima, which are commonly associated with good generalization.
The Break-Even Point on Optimization Trajectories of Deep Neural Networks
Feb 21, 2020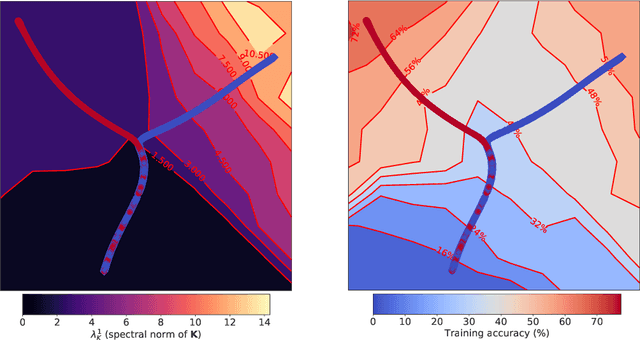
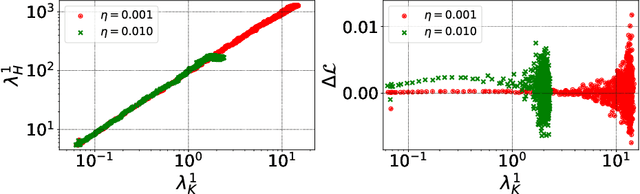

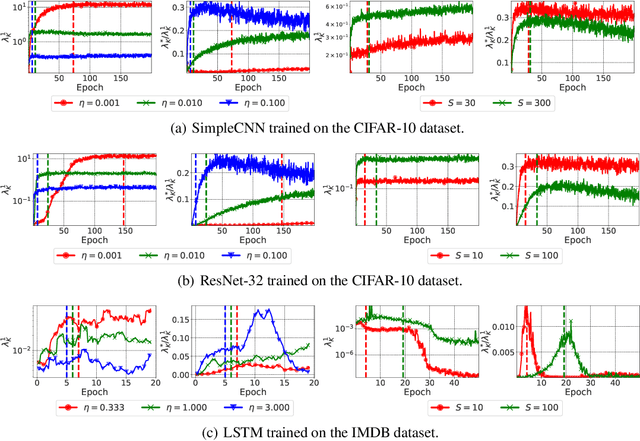
The early phase of training of deep neural networks is critical for their final performance. In this work, we study how the hyperparameters of stochastic gradient descent (SGD) used in the early phase of training affect the rest of the optimization trajectory. We argue for the existence of the "break-even" point on this trajectory, beyond which the curvature of the loss surface and noise in the gradient are implicitly regularized by SGD. In particular, we demonstrate on multiple classification tasks that using a large learning rate in the initial phase of training reduces the variance of the gradient, and improves the conditioning of the covariance of gradients. These effects are beneficial from the optimization perspective and become visible after the break-even point. Complementing prior work, we also show that using a low learning rate results in bad conditioning of the loss surface even for a neural network with batch normalization layers. In short, our work shows that key properties of the loss surface are strongly influenced by SGD in the early phase of training. We argue that studying the impact of the identified effects on generalization is a promising future direction.
Isoelastic Agents and Wealth Updates in Machine Learning Markets
Sep 04, 2012

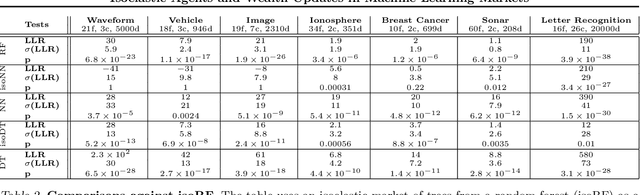
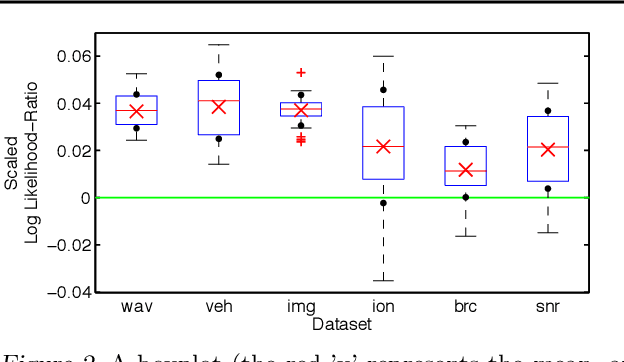
Recently, prediction markets have shown considerable promise for developing flexible mechanisms for machine learning. In this paper, agents with isoelastic utilities are considered. It is shown that the costs associated with homogeneous markets of agents with isoelastic utilities produce equilibrium prices corresponding to alpha-mixtures, with a particular form of mixing component relating to each agent's wealth. We also demonstrate that wealth accumulation for logarithmic and other isoelastic agents (through payoffs on prediction of training targets) can implement both Bayesian model updates and mixture weight updates by imposing different market payoff structures. An iterative algorithm is given for market equilibrium computation. We demonstrate that inhomogeneous markets of agents with isoelastic utilities outperform state of the art aggregate classifiers such as random forests, as well as single classifiers (neural networks, decision trees) on a number of machine learning benchmarks, and show that isoelastic combination methods are generally better than their logarithmic counterparts.