 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoGRAMS: Autonomous Graphical Agent Modeling Software
Jul 14, 2024



We introduce the AutoGRAMS framework for programming multi-step interactions with language models. AutoGRAMS represents AI agents as a graph, where each node can execute either a language modeling instruction or traditional code. Likewise, transitions in the graph can be governed by either language modeling decisions or traditional branch logic. AutoGRAMS supports using variables as memory and allows nodes to call other AutoGRAMS graphs as functions. We show how AutoGRAMS can be used to design highly sophisticated agents, including self-referential agents that can modify their own graph. AutoGRAMS's graph-centric approach aids interpretability, controllability, and safety during the design, development, and deployment of AI agents. We provide our framework as open source at https://github.com/autograms/autograms .
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
Deep Extrapolation for Attribute-Enhanced Generation
Jul 07, 2021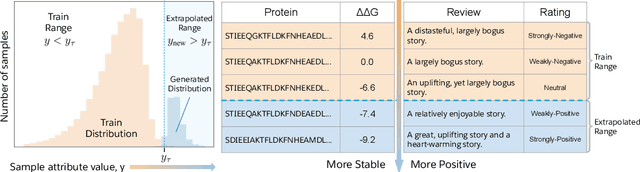
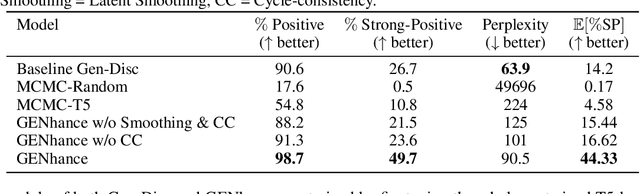
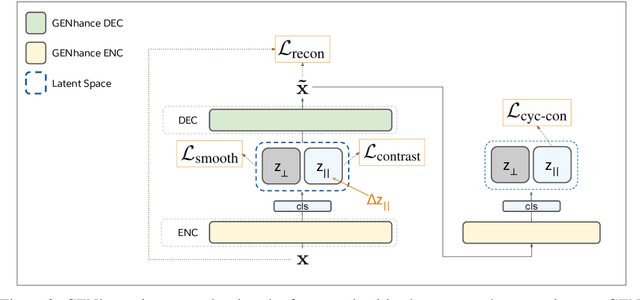
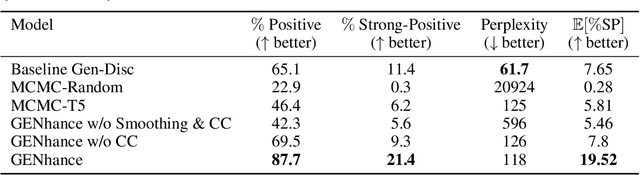
Attribute extrapolation in sample generation is challenging for deep neural networks operating beyond the training distribution. We formulate a new task for extrapolation in sequence generation, focusing on natural language and proteins, and propose GENhance, a generative framework that enhances attributes through a learned latent space. Trained on movie reviews and a computed protein stability dataset, GENhance can generate strongly-positive text reviews and highly stable protein sequences without being exposed to similar data during training. We release our benchmark tasks and models to contribute to the study of generative modeling extrapolation and data-driven design in biology and chemistry.
Explaining and Improving Model Behavior with k Nearest Neighbor Representations
Oct 18, 2020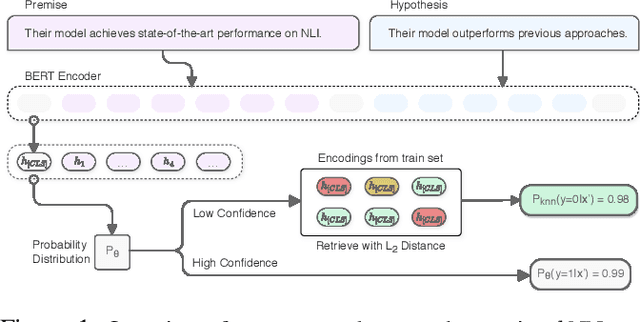



Interpretability techniques in NLP have mainly focused on understanding individual predictions using attention visualization or gradient-based saliency maps over tokens. We propose using k nearest neighbor (kNN) representations to identify training examples responsible for a model's predictions and obtain a corpus-level understanding of the model's behavior. Apart from interpretability, we show that kNN representations are effective at uncovering learned spurious associations, identifying mislabeled examples, and improving the fine-tuned model's performance. We focus on Natural Language Inference (NLI) as a case study and experiment with multiple datasets. Our method deploys backoff to kNN for BERT and RoBERTa on examples with low model confidence without any update to the model parameters. Our results indicate that the kNN approach makes the finetuned model more robust to adversarial inputs.
GeDi: Generative Discriminator Guided Sequence Generation
Sep 14, 2020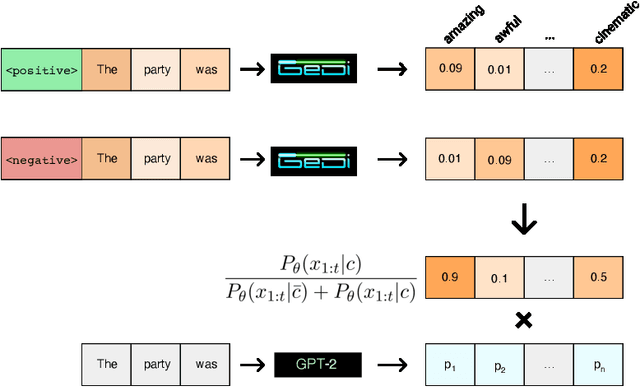
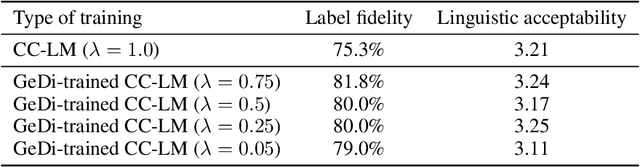
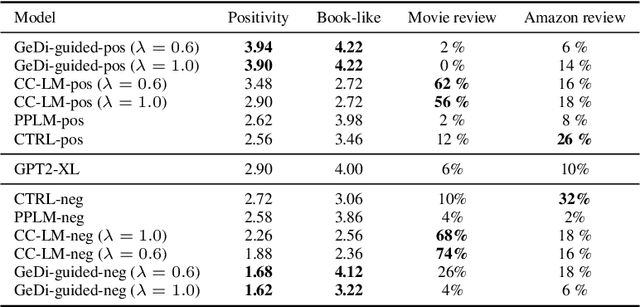
Class-conditional language models (CC-LMs) can be used to generate natural language with specific attributes, such as style or sentiment, by conditioning on an attribute label, or control code. However, we find that these models struggle to control generation when applied to out-of-domain prompts or unseen control codes. To overcome these limitations, we propose generative discriminator (GeDi) guided contrastive generation, which uses CC-LMs as generative discriminators (GeDis) to efficiently guide generation from a (potentially much larger) LM towards a desired attribute. In our human evaluation experiments, we show that GeDis trained for sentiment control on movie reviews are able to control the tone of book text. We also demonstrate that GeDis are able to detoxify generation and control topic while maintaining the same level of linguistic acceptability as direct generation from GPT-2 (1.5B parameters). Lastly, we show that a GeDi trained on only 4 topics can generalize to new control codes from word embeddings, allowing it to guide generation towards wide array of topics.
Taylorized Training: Towards Better Approximation of Neural Network Training at Finite Width
Feb 24, 2020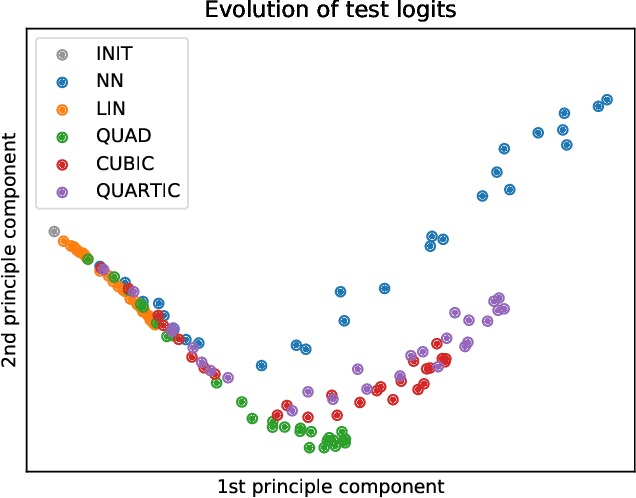


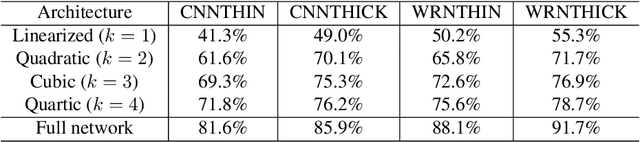
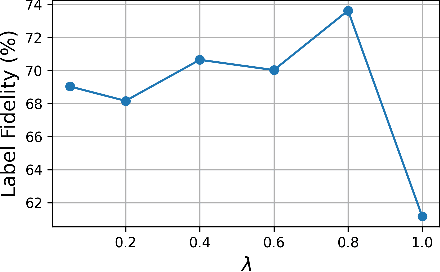
We propose \emph{Taylorized training} as an initiative towards better understanding neural network training at finite width. Taylorized training involves training the $k$-th order Taylor expansion of the neural network at initialization, and is a principled extension of linearized training---a recently proposed theory for understanding the success of deep learning. We experiment with Taylorized training on modern neural network architectures, and show that Taylorized training (1) agrees with full neural network training increasingly better as we increase $k$, and (2) can significantly close the performance gap between linearized and full training. Compared with linearized training, higher-order training works in more realistic settings such as standard parameterization and large (initial) learning rate. We complement our experiments with theoretical results showing that the approximation error of $k$-th order Taylorized models decay exponentially over $k$ in wide neural networks.
Dynamic Evaluation of Transformer Language Models
Apr 17, 2019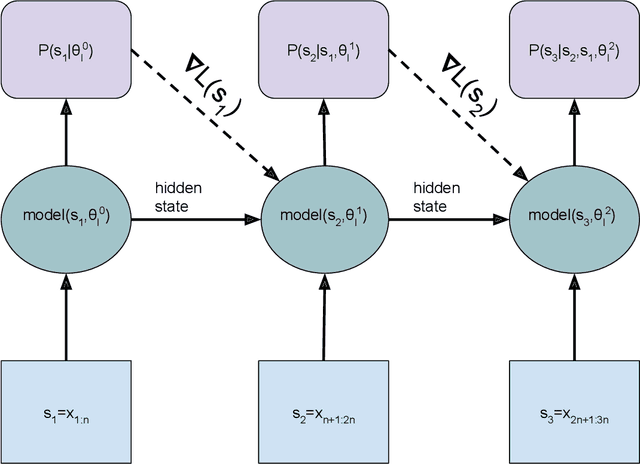
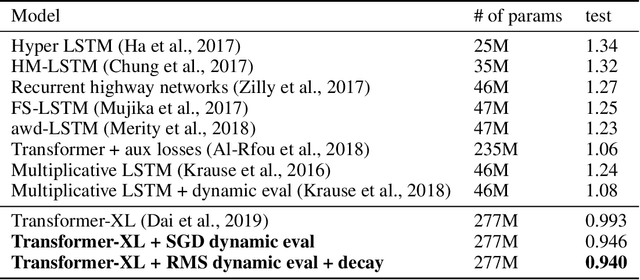


This research note combines two methods that have recently improved the state of the art in language modeling: Transformers and dynamic evaluation. Transformers use stacked layers of self-attention that allow them to capture long range dependencies in sequential data. Dynamic evaluation fits models to the recent sequence history, allowing them to assign higher probabilities to re-occurring sequential patterns. By applying dynamic evaluation to Transformer-XL models, we improve the state of the art on enwik8 from 0.99 to 0.94 bits/char, text8 from 1.08 to 1.04 bits/char, and WikiText-103 from 18.3 to 16.4 perplexity points.
Talking to myself: self-dialogues as data for conversational agents
Sep 19, 2018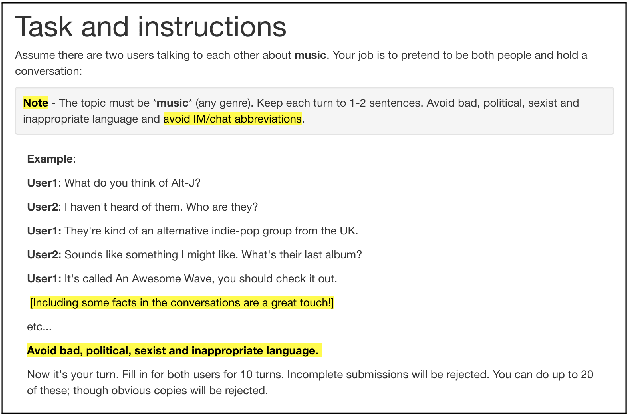
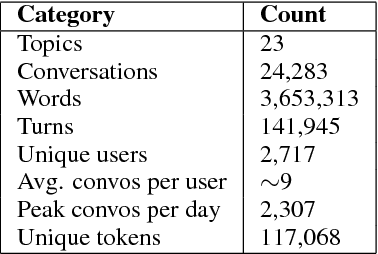
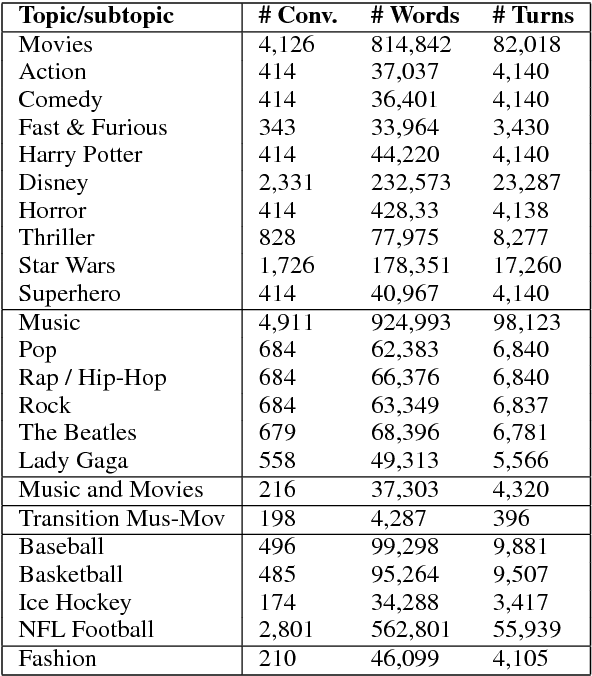
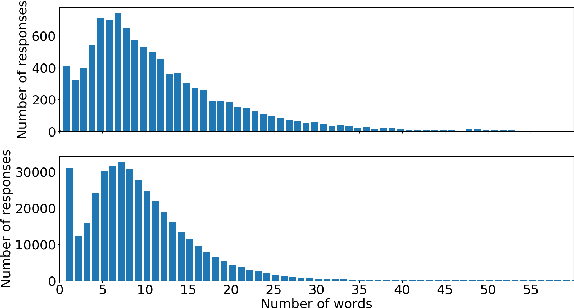
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
Dynamic Evaluation of Neural Sequence Models
Oct 25, 2017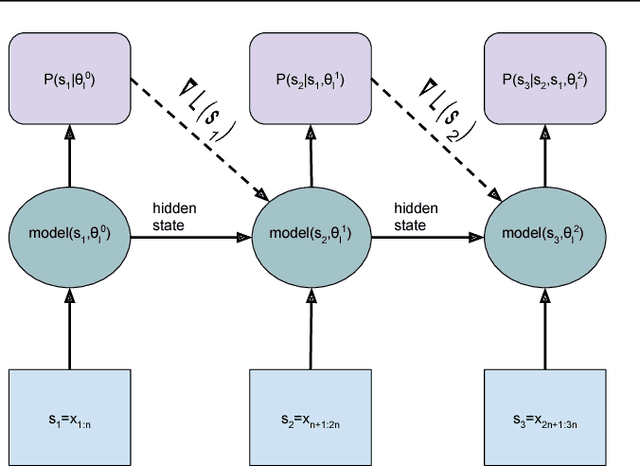

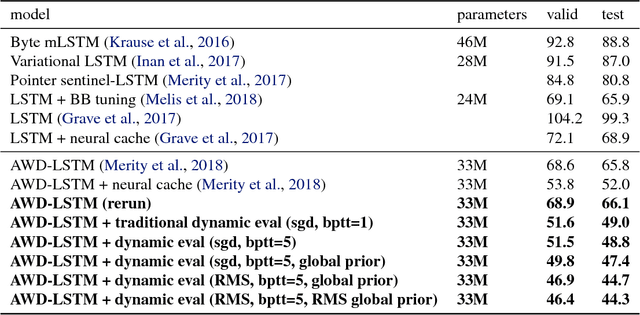
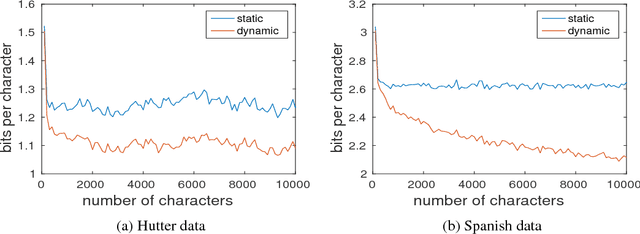
We present methodology for using dynamic evaluation to improve neural sequence models. Models are adapted to recent history via a gradient descent based mechanism, causing them to assign higher probabilities to re-occurring sequential patterns. Dynamic evaluation outperforms existing adaptation approaches in our comparisons. Dynamic evaluation improves the state-of-the-art word-level perplexities on the Penn Treebank and WikiText-2 datasets to 51.1 and 44.3 respectively, and the state-of-the-art character-level cross-entropies on the text8 and Hutter Prize datasets to 1.19 bits/char and 1.08 bits/char respectively.
Multiplicative LSTM for sequence modelling
Oct 12, 2017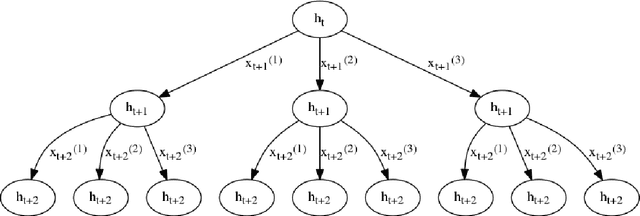
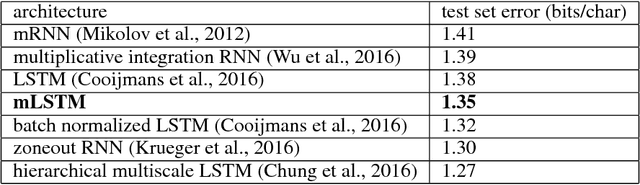
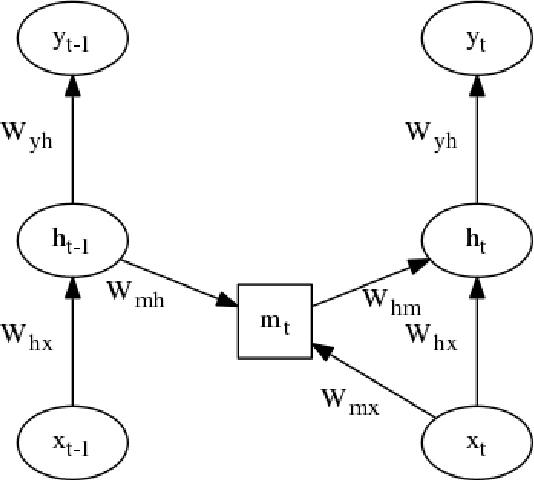

We introduce multiplicative LSTM (mLSTM), a recurrent neural network architecture for sequence modelling that combines the long short-term memory (LSTM) and multiplicative recurrent neural network architectures. mLSTM is characterised by its ability to have different recurrent transition functions for each possible input, which we argue makes it more expressive for autoregressive density estimation. We demonstrate empirically that mLSTM outperforms standard LSTM and its deep variants for a range of character level language modelling tasks. In this version of the paper, we regularise mLSTM to achieve 1.27 bits/char on text8 and 1.24 bits/char on Hutter Prize. We also apply a purely byte-level mLSTM on the WikiText-2 dataset to achieve a character level entropy of 1.26 bits/char, corresponding to a word level perplexity of 88.8, which is comparable to word level LSTMs regularised in similar ways on the same task.