 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTF: One-stop Transformer Library for State-of-the-art Code LLM
May 31, 2023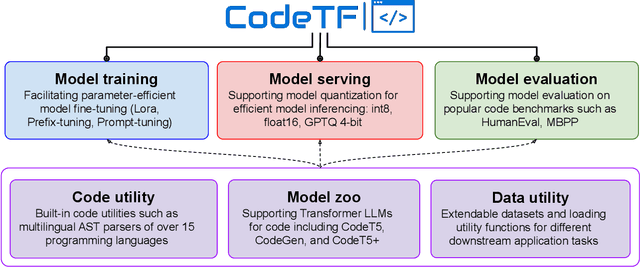

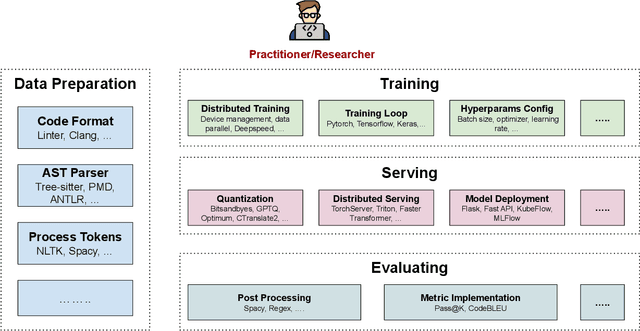
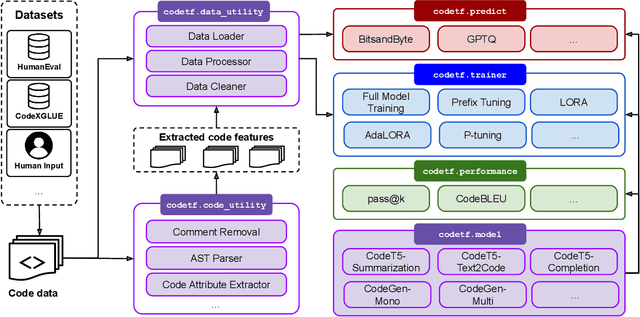
Code intelligence plays a key role in transforming modern software engineering. Recently, deep learning-based models, especially Transformer-based large language models (LLMs), have demonstrated remarkable potential in tackling these tasks by leveraging massive open-source code data and programming language features. However, the development and deployment of such models often require expertise in both machine learning and software engineering, creating a barrier for the model adoption. In this paper, we present CodeTF, an open-source Transformer-based library for state-of-the-art Code LLMs and code intelligence. Following the principles of modular design and extensible framework, we design CodeTF with a unified interface to enable rapid access and development across different types of models, datasets and tasks. Our library supports a collection of pretrained Code LLM models and popular code benchmarks, including a standardized interface to train and serve code LLMs efficiently, and data features such as language-specific parsers and utility functions for extracting code attributes. In this paper, we describe the design principles, the architecture, key modules and components, and compare with other related library tools. Finally, we hope CodeTF is able to bridge the gap between machine learning/generative AI and software engineering, providing a comprehensive open-source solution for developers, researchers, and practitioners.
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
May 20, 2023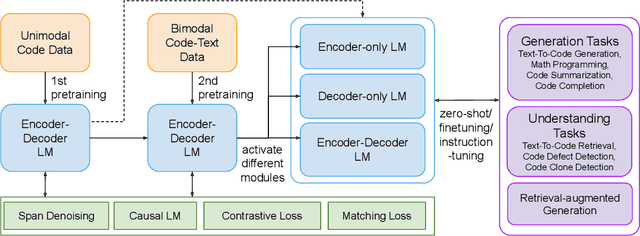
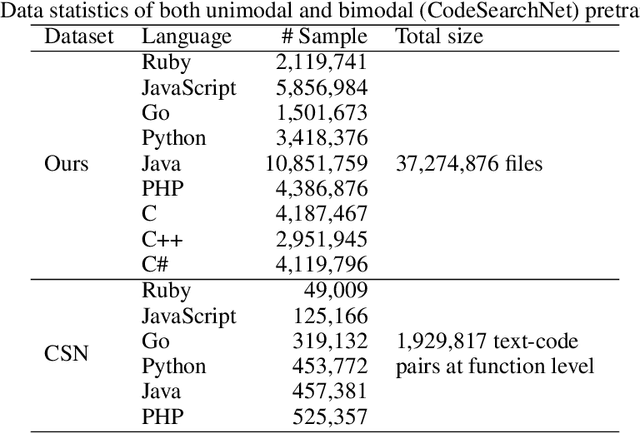
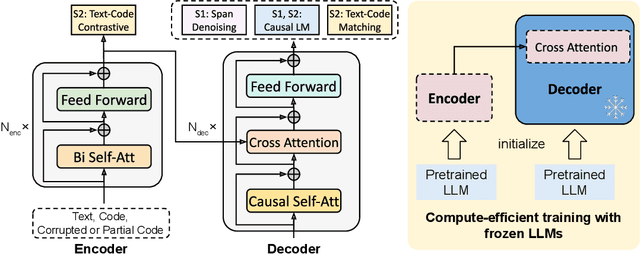
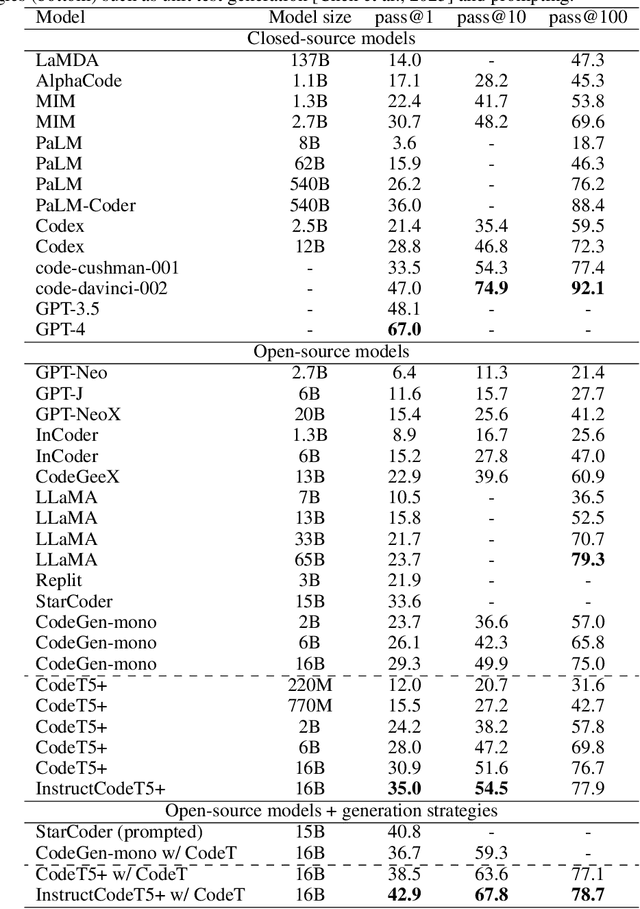
Large language models (LLMs) pretrained on vast source code have achieved prominent progress in code intelligence. However, existing code LLMs have two main limitations in terms of architecture and pretraining tasks. First, they often adopt a specific architecture (encoder-only or decoder-only) or rely on a unified encoder-decoder network for different downstream tasks. The former paradigm is limited by inflexibility in applications while in the latter, the model is treated as a single system for all tasks, leading to suboptimal performance on a subset of tasks. Secondly, they often employ a limited set of pretraining objectives which might not be relevant to some downstream tasks and hence result in substantial performance degrade. To address these limitations, we propose ``CodeT5+'', a family of encoder-decoder LLMs for code in which component modules can be flexibly combined to suit a wide range of downstream code tasks. Such flexibility is enabled by our proposed mixture of pretraining objectives to mitigate the pretrain-finetune discrepancy. These objectives cover span denoising, contrastive learning, text-code matching, and causal LM pretraining tasks, on both unimodal and bimodal multilingual code corpora. Furthermore, we propose to initialize CodeT5+ with frozen off-the-shelf LLMs without training from scratch to efficiently scale up our models, and explore instruction-tuning to align with natural language instructions. We extensively evaluate CodeT5+ on over 20 code-related benchmarks in different settings, including zero-shot, finetuning, and instruction-tuning. We observe state-of-the-art (SoTA) model performance on various code-related tasks, such as code generation and completion, math programming, and text-to-code retrieval tasks. Particularly, our instruction-tuned CodeT5+ 16B achieves new SoTA results on HumanEval code generation task against other open code LLMs.
CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning
Jul 05, 2022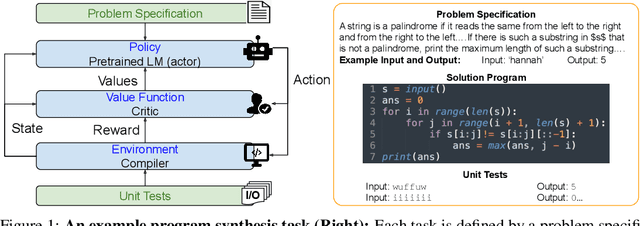
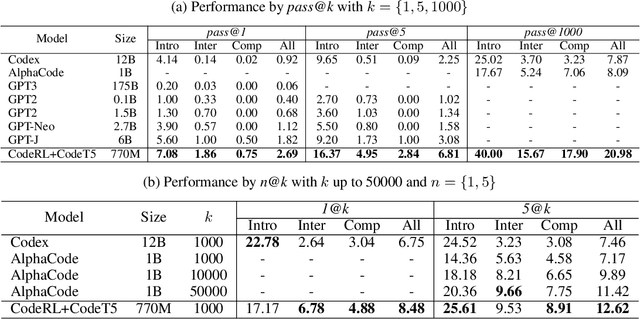
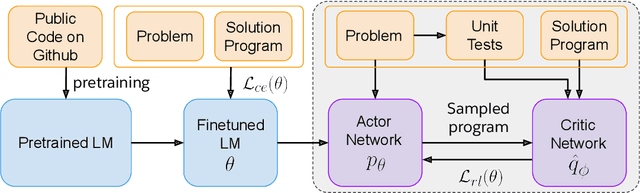
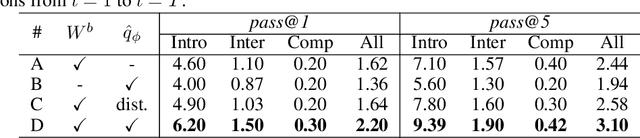
Program synthesis or code generation aims to generate a program that satisfies a problem specification. Recent approaches using large-scale pretrained language models (LMs) have shown promising results, yet they have some critical limitations. In particular, they often follow a standard supervised fine-tuning procedure to train a code generation model only from the pairs of natural-language problem descriptions and ground-truth programs. Such paradigm largely ignores some important but potentially useful signals in the problem specification such as unit tests, which thus often results in poor performance when solving complex unseen coding tasks. To address the limitations, we propose "CodeRL", a new framework for program synthesis tasks through pretrained LMs and deep reinforcement learning (RL). Specifically, during training, we treat the code-generating LM as an actor network, and introduce a critic network that is trained to predict the functional correctness of generated programs and provide dense feedback signals to the actor. During inference, we introduce a new generation procedure with a critical sampling strategy that allows a model to automatically regenerate programs based on feedback from example unit tests and critic scores. For the model backbones, we extended the encoder-decoder architecture of CodeT5 with enhanced learning objectives, larger model sizes, and better pretraining data. Our method not only achieves new SOTA results on the challenging APPS benchmark, but also shows strong zero-shot transfer capability with new SOTA results on the simpler MBPP benchmark.
Cascaded Fast and Slow Models for Efficient Semantic Code Search
Oct 15, 2021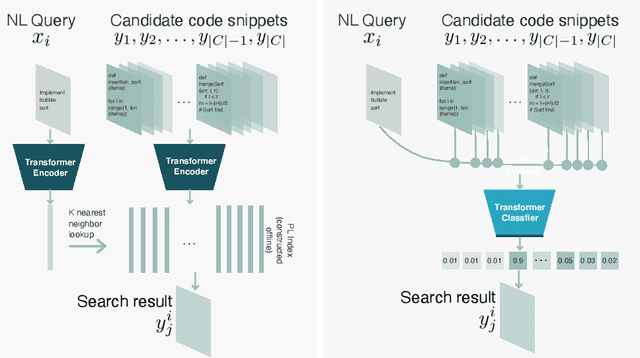

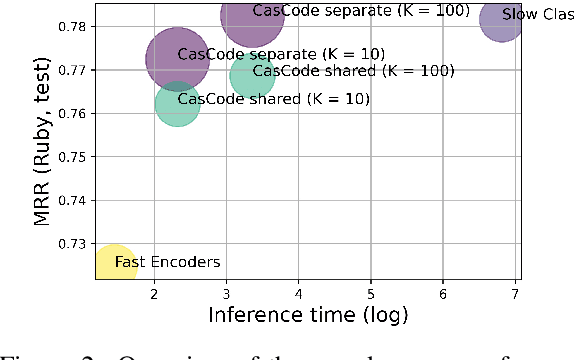

The goal of natural language semantic code search is to retrieve a semantically relevant code snippet from a fixed set of candidates using a natural language query. Existing approaches are neither effective nor efficient enough towards a practical semantic code search system. In this paper, we propose an efficient and accurate semantic code search framework with cascaded fast and slow models, in which a fast transformer encoder model is learned to optimize a scalable index for fast retrieval followed by learning a slow classification-based re-ranking model to improve the performance of the top K results from the fast retrieval. To further reduce the high memory cost of deploying two separate models in practice, we propose to jointly train the fast and slow model based on a single transformer encoder with shared parameters. The proposed cascaded approach is not only efficient and scalable, but also achieves state-of-the-art results with an average mean reciprocal ranking (MRR) score of 0.7795 (across 6 programming languages) as opposed to the previous state-of-the-art result of 0.713 MRR on the CodeSearchNet benchmark.
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Jul 16, 2021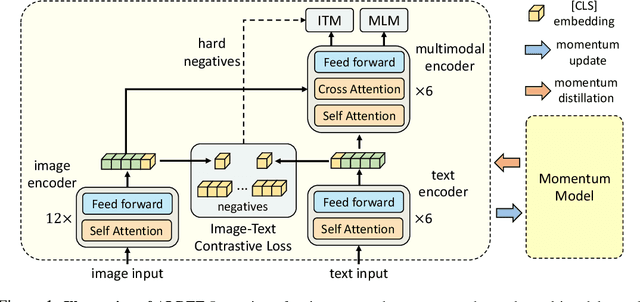



Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and word tokens. Because the visual tokens and word tokens are unaligned, it is challenging for the multimodal encoder to learn image-text interactions. In this paper, we introduce a contrastive loss to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning. Unlike most existing methods, our method does not require bounding box annotations nor high-resolution images. In order to improve learning from noisy web data, we propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model. We provide a theoretical analysis of ALBEF from a mutual information maximization perspective, showing that different training tasks can be interpreted as different ways to generate views for an image-text pair. ALBEF achieves state-of-the-art performance on multiple downstream vision-language tasks. On image-text retrieval, ALBEF outperforms methods that are pre-trained on orders of magnitude larger datasets. On VQA and NLVR$^2$, ALBEF achieves absolute improvements of 2.37% and 3.84% compared to the state-of-the-art, while enjoying faster inference speed. Code and pre-trained models are available at https://github.com/salesforce/ALBEF/.
GeDi: Generative Discriminator Guided Sequence Generation
Sep 14, 2020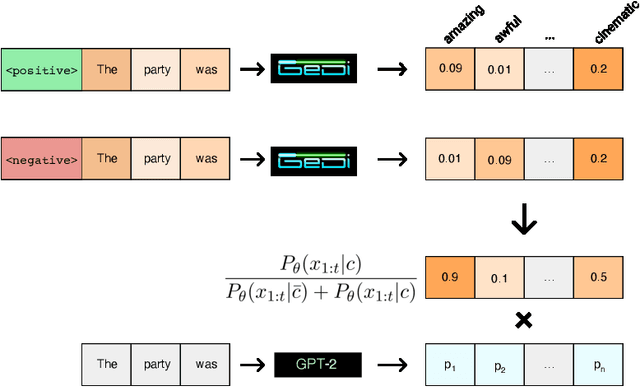
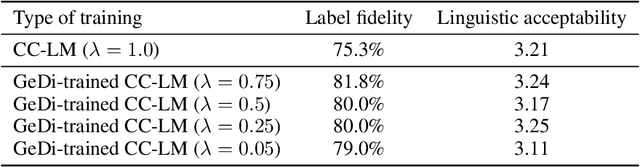
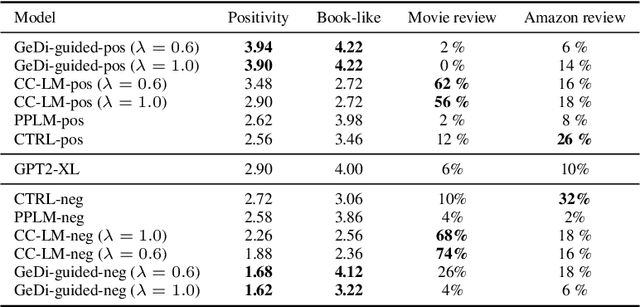
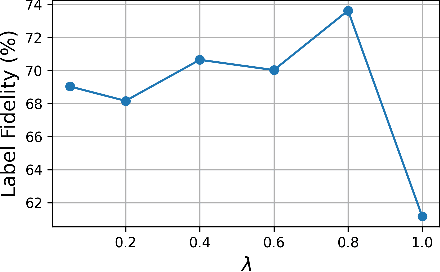
Class-conditional language models (CC-LMs) can be used to generate natural language with specific attributes, such as style or sentiment, by conditioning on an attribute label, or control code. However, we find that these models struggle to control generation when applied to out-of-domain prompts or unseen control codes. To overcome these limitations, we propose generative discriminator (GeDi) guided contrastive generation, which uses CC-LMs as generative discriminators (GeDis) to efficiently guide generation from a (potentially much larger) LM towards a desired attribute. In our human evaluation experiments, we show that GeDis trained for sentiment control on movie reviews are able to control the tone of book text. We also demonstrate that GeDis are able to detoxify generation and control topic while maintaining the same level of linguistic acceptability as direct generation from GPT-2 (1.5B parameters). Lastly, we show that a GeDi trained on only 4 topics can generalize to new control codes from word embeddings, allowing it to guide generation towards wide array of topics.