 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoGRAMS: Autonomous Graphical Agent Modeling Software
Jul 14, 2024



We introduce the AutoGRAMS framework for programming multi-step interactions with language models. AutoGRAMS represents AI agents as a graph, where each node can execute either a language modeling instruction or traditional code. Likewise, transitions in the graph can be governed by either language modeling decisions or traditional branch logic. AutoGRAMS supports using variables as memory and allows nodes to call other AutoGRAMS graphs as functions. We show how AutoGRAMS can be used to design highly sophisticated agents, including self-referential agents that can modify their own graph. AutoGRAMS's graph-centric approach aids interpretability, controllability, and safety during the design, development, and deployment of AI agents. We provide our framework as open source at https://github.com/autograms/autograms .
Lower Dimensional Kernels for Video Discriminators
Dec 18, 2019

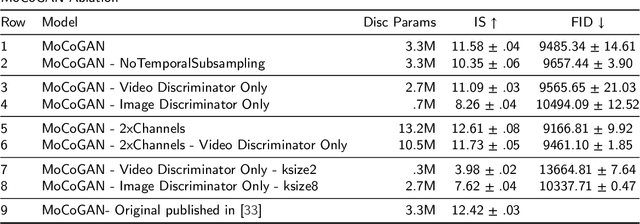
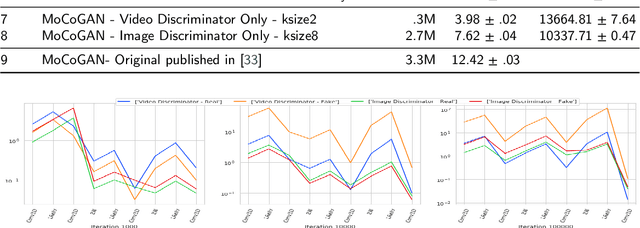
This work presents an analysis of the discriminators used in Generative Adversarial Networks (GANs) for Video. We show that unconstrained video discriminator architectures induce a loss surface with high curvature which make optimisation difficult. We also show that this curvature becomes more extreme as the maximal kernel dimension of video discriminators increases. With these observations in hand, we propose a family of efficient Lower-Dimensional Video Discriminators for GANs (LDVD GANs). The proposed family of discriminators improve the performance of video GAN models they are applied to and demonstrate good performance on complex and diverse datasets such as UCF-101. In particular, we show that they can double the performance of Temporal-GANs and provide for state-of-the-art performance on a single GPU.
Dynamic Evaluation of Transformer Language Models
Apr 17, 2019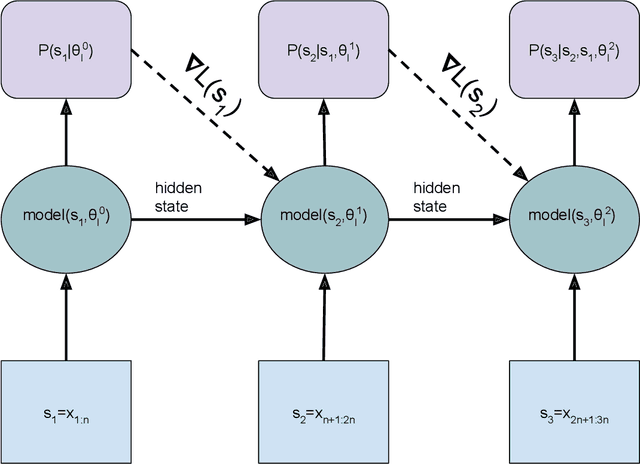
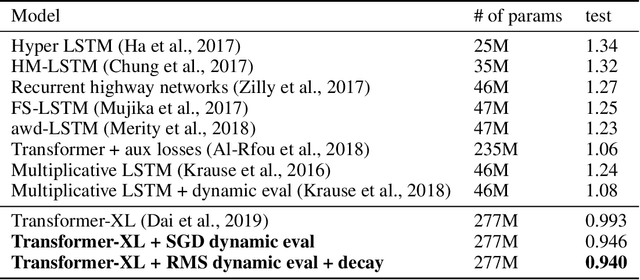


This research note combines two methods that have recently improved the state of the art in language modeling: Transformers and dynamic evaluation. Transformers use stacked layers of self-attention that allow them to capture long range dependencies in sequential data. Dynamic evaluation fits models to the recent sequence history, allowing them to assign higher probabilities to re-occurring sequential patterns. By applying dynamic evaluation to Transformer-XL models, we improve the state of the art on enwik8 from 0.99 to 0.94 bits/char, text8 from 1.08 to 1.04 bits/char, and WikiText-103 from 18.3 to 16.4 perplexity points.
Talking to myself: self-dialogues as data for conversational agents
Sep 19, 2018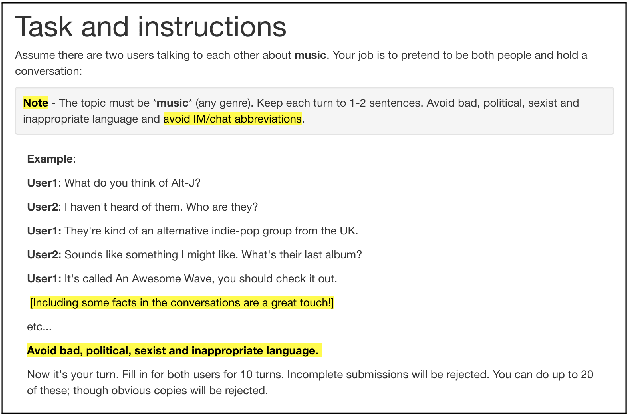
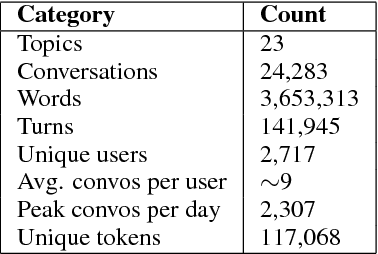
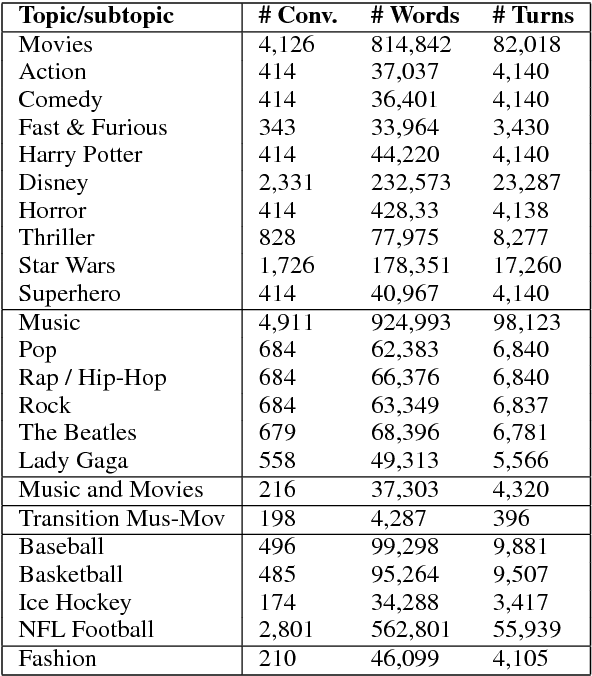
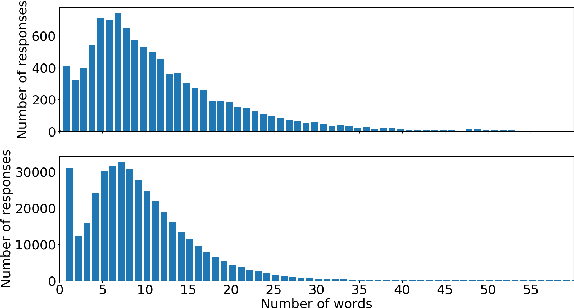
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
Dynamic Evaluation of Neural Sequence Models
Oct 25, 2017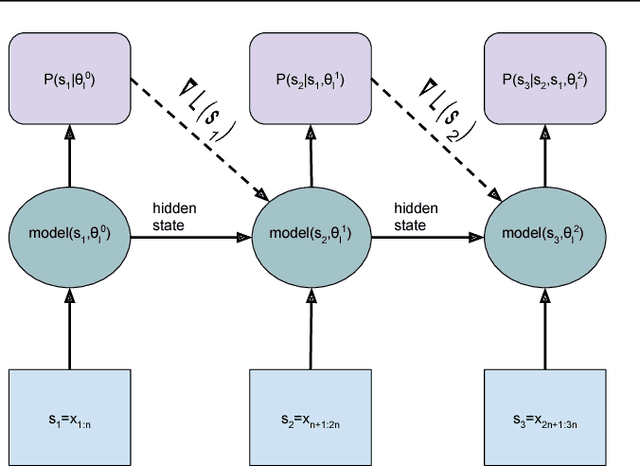

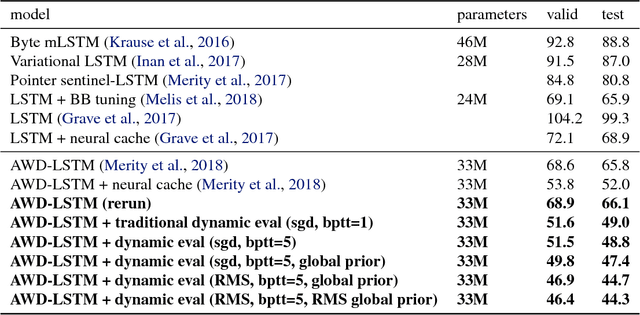
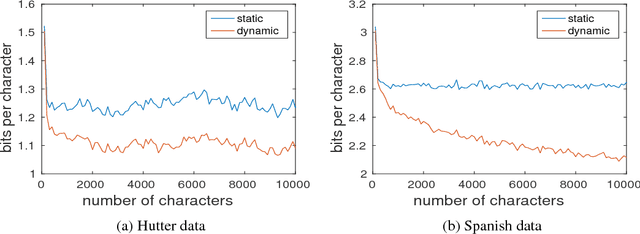
We present methodology for using dynamic evaluation to improve neural sequence models. Models are adapted to recent history via a gradient descent based mechanism, causing them to assign higher probabilities to re-occurring sequential patterns. Dynamic evaluation outperforms existing adaptation approaches in our comparisons. Dynamic evaluation improves the state-of-the-art word-level perplexities on the Penn Treebank and WikiText-2 datasets to 51.1 and 44.3 respectively, and the state-of-the-art character-level cross-entropies on the text8 and Hutter Prize datasets to 1.19 bits/char and 1.08 bits/char respectively.
Edina: Building an Open Domain Socialbot with Self-dialogues
Sep 28, 2017
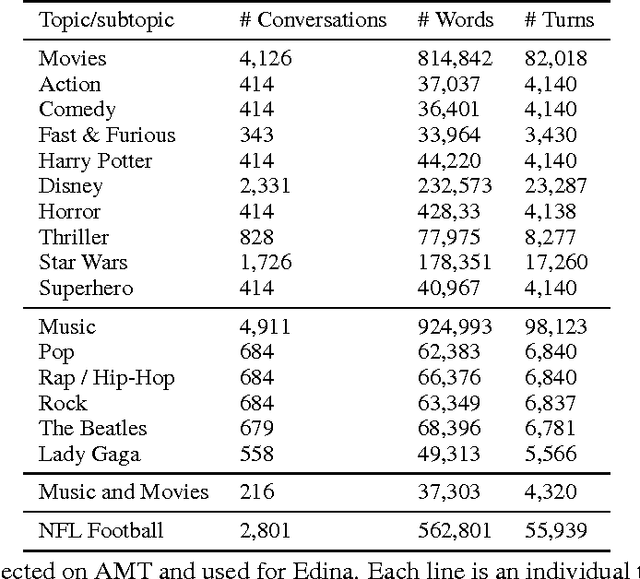
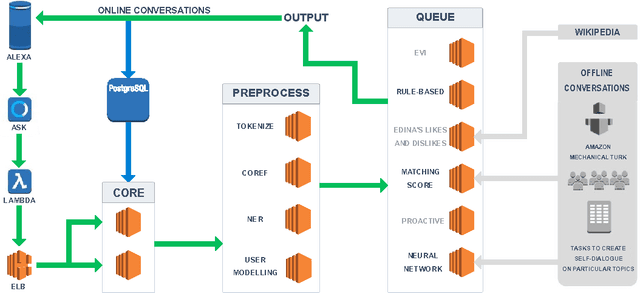

We present Edina, the University of Edinburgh's social bot for the Amazon Alexa Prize competition. Edina is a conversational agent whose responses utilize data harvested from Amazon Mechanical Turk (AMT) through an innovative new technique we call self-dialogues. These are conversations in which a single AMT Worker plays both participants in a dialogue. Such dialogues are surprisingly natural, efficient to collect and reflective of relevant and/or trending topics. These self-dialogues provide training data for a generative neural network as well as a basis for soft rules used by a matching score component. Each match of a soft rule against a user utterance is associated with a confidence score which we show is strongly indicative of reply quality, allowing this component to self-censor and be effectively integrated with other components. Edina's full architecture features a rule-based system backing off to a matching score, backing off to a generative neural network. Our hybrid data-driven methodology thus addresses both coverage limitations of a strictly rule-based approach and the lack of guarantees of a strictly machine-learning approach.