 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoActor: Grounding Task Planning into Spatial-aware Egocentric Actions for Humanoid Robots via Visual-Language Models
Feb 04, 2026Deploying humanoid robots in real-world settings is fundamentally challenging, as it demands tight integration of perception, locomotion, and manipulation under partial-information observations and dynamically changing environments. As well as transitioning robustly between sub-tasks of different types. Towards addressing these challenges, we propose a novel task - EgoActing, which requires directly grounding high-level instructions into various, precise, spatially aware humanoid actions. We further instantiate this task by introducing EgoActor, a unified and scalable vision-language model (VLM) that can predict locomotion primitives (e.g., walk, turn, move sideways, change height), head movements, manipulation commands, and human-robot interactions to coordinate perception and execution in real-time. We leverage broad supervision over egocentric RGB-only data from real-world demonstrations, spatial reasoning question-answering, and simulated environment demonstrations, enabling EgoActor to make robust, context-aware decisions and perform fluent action inference (under 1s) with both 8B and 4B parameter models. Extensive evaluations in both simulated and real-world environments demonstrate that EgoActor effectively bridges abstract task planning and concrete motor execution, while generalizing across diverse tasks and unseen environments.
EntWorld: A Holistic Environment and Benchmark for Verifiable Enterprise GUI Agents
Jan 25, 2026Recent advances in Multimodal Large Language Models (MLLMs) have enabled agents to operate in open-ended web and operating system environments. However, existing benchmarks predominantly target consumer-oriented scenarios (e.g., e-commerce and travel booking), failing to capture the complexity and rigor of professional enterprise workflows. Enterprise systems pose distinct challenges, including high-density user interfaces, strict business logic constraints, and a strong reliance on precise, state-consistent information retrieval-settings in which current generalist agents often struggle. To address this gap, we introduce EntWorld, a large-scale benchmark consisting of 1,756 tasks across six representative enterprise domains, including customer relationship management (CRM), information technology infrastructure library (ITIL), and enterprise resource planning (ERP) systems. Unlike previous datasets that depend on fragile execution traces or extensive manual annotation, EntWorld adopts a schema-grounded task generation framework that directly reverse-engineers business logic from underlying database schemas, enabling the synthesis of realistic, long-horizon workflows. Moreover, we propose a SQL-based deterministic verification mechanism in building datasets that replaces ambiguous visual matching with rigorous state-transition validation. Experimental results demonstrate that state-of-the-art models (e.g., GPT-4.1) achieve 47.61% success rate on EntWorld, substantially lower than the human performance, highlighting a pronounced enterprise gap in current agentic capabilities and the necessity of developing domain-specific agents. We release EntWorld as a rigorous testbed to facilitate the development and evaluation of the next generation of enterprise-ready digital agents.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
DMA: Online RAG Alignment with Human Feedback
Nov 06, 2025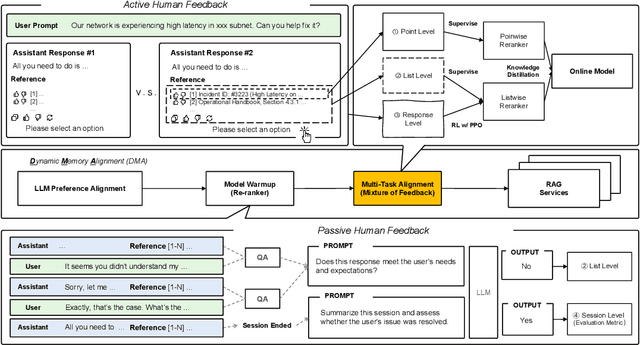

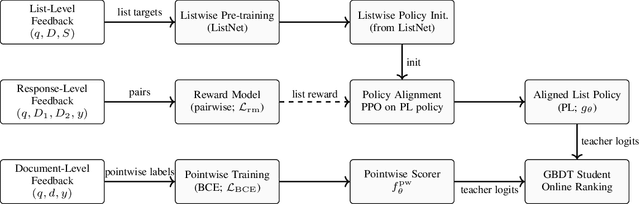
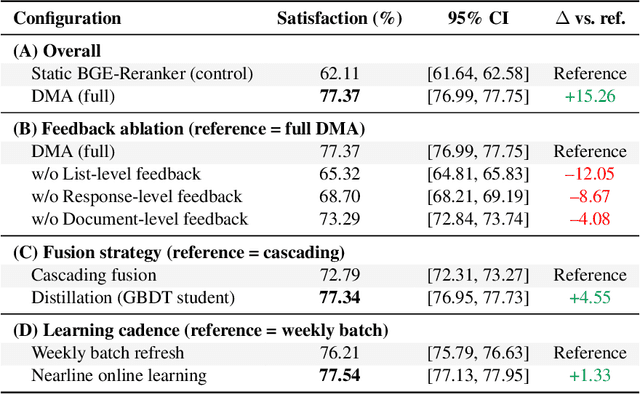
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
Joint Visible Light and Backscatter Communications for Proximity-Based Indoor Asset Tracking Enabled by Energy-Neutral Devices
Oct 31, 2025In next-generation wireless systems, providing location-based mobile computing services for energy-neutral devices has become a crucial objective for the provision of sustainable Internet of Things (IoT). Visible light positioning (VLP) has gained great research attention as a complementary method to radio frequency (RF) solutions since it can leverage ubiquitous lighting infrastructure. However, conventional VLP receivers often rely on photodetectors or cameras that are power-hungry, complex, and expensive. To address this challenge, we propose a hybrid indoor asset tracking system that integrates visible light communication (VLC) and backscatter communication (BC) within a simultaneous lightwave information and power transfer (SLIPT) framework. We design a low-complexity and energy-neutral IoT node, namely backscatter device (BD) which harvests energy from light-emitting diode (LED) access points, and then modulates and reflects ambient RF carriers to indicate its location within particular VLC cells. We present a multi-cell VLC deployment with frequency division multiplexing (FDM) method that mitigates interference among LED access points by assigning them distinct frequency pairs based on a four-color map scheduling principle. We develop a lightweight particle filter (PF) tracking algorithm at an edge RF reader, where the fusion of proximity reports and the received backscatter signal strength are employed to track the BD. Experimental results show that this approach achieves the positioning error of 0.318 m at 50th percentile and 0.634 m at 90th percentile, while avoiding the use of complex photodetectors and active RF synthesizing components at the energy-neutral IoT node. By demonstrating robust performance in multiple indoor trajectories, the proposed solution enables scalable, cost-effective, and energy-neutral indoor tracking for pervasive and edge-assisted IoT applications.
SAC-MIL: Spatial-Aware Correlated Multiple Instance Learning for Histopathology Whole Slide Image Classification
Sep 04, 2025



We propose Spatial-Aware Correlated Multiple Instance Learning (SAC-MIL) for performing WSI classification. SAC-MIL consists of a positional encoding module to encode position information and a SAC block to perform full instance correlations. The positional encoding module utilizes the instance coordinates within the slide to encode the spatial relationships instead of the instance index in the input WSI sequence. The positional encoding module can also handle the length extrapolation issue where the training and testing sequences have different lengths. The SAC block is an MLP-based method that performs full instance correlation in linear time complexity with respect to the sequence length. Due to the simple structure of MLP, it is easy to deploy since it does not require custom CUDA kernels, compared to Transformer-based methods for WSI classification. SAC-MIL has achieved state-of-the-art performance on the CAMELYON-16, TCGA-LUNG, and TCGA-BRAC datasets. The code will be released upon acceptance.
CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models
Jun 09, 2025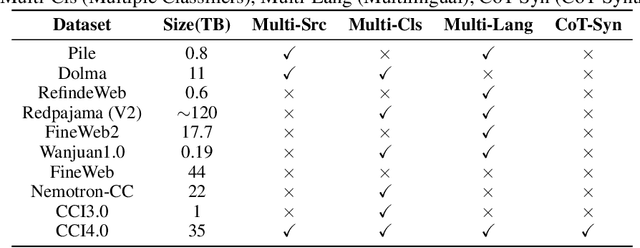
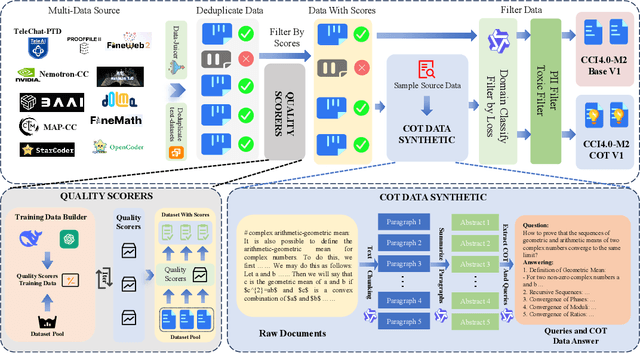
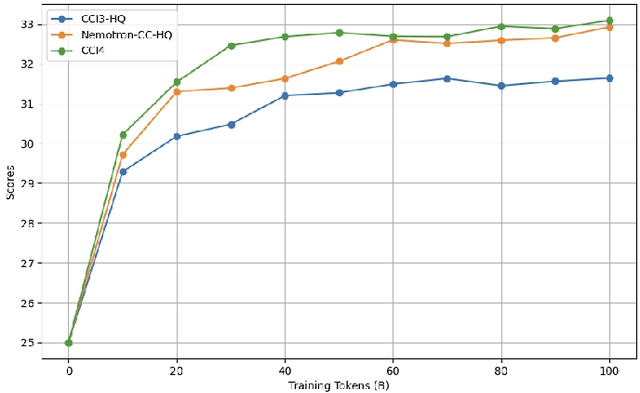
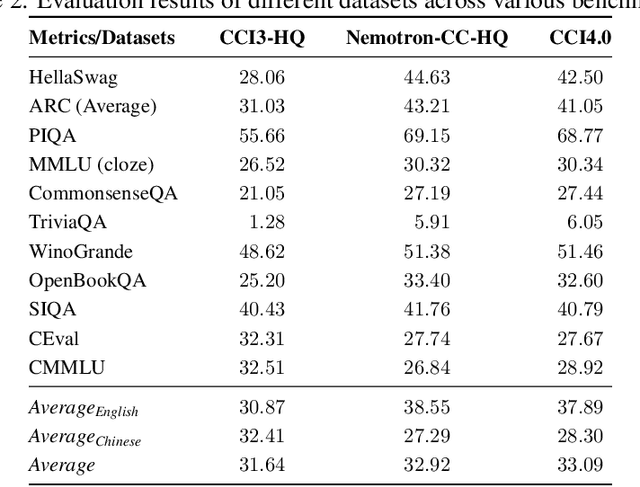
We introduce CCI4.0, a large-scale bilingual pre-training dataset engineered for superior data quality and diverse human-like reasoning trajectory. CCI4.0 occupies roughly $35$ TB of disk space and comprises two sub-datasets: CCI4.0-M2-Base and CCI4.0-M2-CoT. CCI4.0-M2-Base combines a $5.2$ TB carefully curated Chinese web corpus, a $22.5$ TB English subset from Nemotron-CC, and diverse sources from math, wiki, arxiv, and code. Although these data are mostly sourced from well-processed datasets, the quality standards of various domains are dynamic and require extensive expert experience and labor to process. So, we propose a novel pipeline justifying data quality mainly based on models through two-stage deduplication, multiclassifier quality scoring, and domain-aware fluency filtering. We extract $4.5$ billion pieces of CoT(Chain-of-Thought) templates, named CCI4.0-M2-CoT. Differing from the distillation of CoT from larger models, our proposed staged CoT extraction exemplifies diverse reasoning patterns and significantly decreases the possibility of hallucination. Empirical evaluations demonstrate that LLMs pre-trained in CCI4.0 benefit from cleaner, more reliable training signals, yielding consistent improvements in downstream tasks, especially in math and code reflection tasks. Our results underscore the critical role of rigorous data curation and human thinking templates in advancing LLM performance, shedding some light on automatically processing pretraining corpora.
EduBench: A Comprehensive Benchmarking Dataset for Evaluating Large Language Models in Diverse Educational Scenarios
May 22, 2025As large language models continue to advance, their application in educational contexts remains underexplored and under-optimized. In this paper, we address this gap by introducing the first diverse benchmark tailored for educational scenarios, incorporating synthetic data containing 9 major scenarios and over 4,000 distinct educational contexts. To enable comprehensive assessment, we propose a set of multi-dimensional evaluation metrics that cover 12 critical aspects relevant to both teachers and students. We further apply human annotation to ensure the effectiveness of the model-generated evaluation responses. Additionally, we succeed to train a relatively small-scale model on our constructed dataset and demonstrate that it can achieve performance comparable to state-of-the-art large models (e.g., Deepseek V3, Qwen Max) on the test set. Overall, this work provides a practical foundation for the development and evaluation of education-oriented language models. Code and data are released at https://github.com/ybai-nlp/EduBench.
SoLoPO: Unlocking Long-Context Capabilities in LLMs via Short-to-Long Preference Optimization
May 16, 2025Despite advances in pretraining with extended context lengths, large language models (LLMs) still face challenges in effectively utilizing real-world long-context information, primarily due to insufficient long-context alignment caused by data quality issues, training inefficiencies, and the lack of well-designed optimization objectives. To address these limitations, we propose a framework named $\textbf{S}$h$\textbf{o}$rt-to-$\textbf{Lo}$ng $\textbf{P}$reference $\textbf{O}$ptimization ($\textbf{SoLoPO}$), decoupling long-context preference optimization (PO) into two components: short-context PO and short-to-long reward alignment (SoLo-RA), supported by both theoretical and empirical evidence. Specifically, short-context PO leverages preference pairs sampled from short contexts to enhance the model's contextual knowledge utilization ability. Meanwhile, SoLo-RA explicitly encourages reward score consistency utilization for the responses when conditioned on both short and long contexts that contain identical task-relevant information. This facilitates transferring the model's ability to handle short contexts into long-context scenarios. SoLoPO is compatible with mainstream preference optimization algorithms, while substantially improving the efficiency of data construction and training processes. Experimental results show that SoLoPO enhances all these algorithms with respect to stronger length and domain generalization abilities across various long-context benchmarks, while achieving notable improvements in both computational and memory efficiency.
AdaMHF: Adaptive Multimodal Hierarchical Fusion for Survival Prediction
Mar 27, 2025The integration of pathologic images and genomic data for survival analysis has gained increasing attention with advances in multimodal learning. However, current methods often ignore biological characteristics, such as heterogeneity and sparsity, both within and across modalities, ultimately limiting their adaptability to clinical practice. To address these challenges, we propose AdaMHF: Adaptive Multimodal Hierarchical Fusion, a framework designed for efficient, comprehensive, and tailored feature extraction and fusion. AdaMHF is specifically adapted to the uniqueness of medical data, enabling accurate predictions with minimal resource consumption, even under challenging scenarios with missing modalities. Initially, AdaMHF employs an experts expansion and residual structure to activate specialized experts for extracting heterogeneous and sparse features. Extracted tokens undergo refinement via selection and aggregation, reducing the weight of non-dominant features while preserving comprehensive information. Subsequently, the encoded features are hierarchically fused, allowing multi-grained interactions across modalities to be captured. Furthermore, we introduce a survival prediction benchmark designed to resolve scenarios with missing modalities, mirroring real-world clinical conditions. Extensive experiments on TCGA datasets demonstrate that AdaMHF surpasses current state-of-the-art (SOTA) methods, showcasing exceptional performance in both complete and incomplete modality settings.