 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBPO: Empirical Bayes Shrinkage for Stabilizing Group-Relative Policy Optimization
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for enhancing the reasoning capabilities of Large Language Models (LLMs). However, dominant approaches like Group Relative Policy Optimization (GRPO) face critical stability challenges: they suffer from high estimator variance under computational constraints (small group sizes) and vanishing gradient signals in saturated failure regimes where all responses yield identical zero rewards. To address this, we propose Empirical Bayes Policy Optimization (EBPO), a novel framework that regularizes local group-based baselines by borrowing strength from the policy's accumulated global statistics. Instead of estimating baselines in isolation, EBPO employs a shrinkage estimator that dynamically balances local group statistics with a global prior updated via Welford's online algorithm. Theoretically, we demonstrate that EBPO guarantees strictly lower Mean Squared Error (MSE), bounded entropy decay, and non-vanishing penalty signals in failure scenarios compared to GRPO. Empirically, EBPO consistently outperforms GRPO and other established baselines across diverse benchmarks, including AIME and OlympiadBench. Notably, EBPO exhibits superior training stability, achieving high-performance gains even with small group sizes, and benefits significantly from difficulty-stratified curriculum learning.
Smooth Dynamic Cutoffs for Machine Learning Interatomic Potentials
Jan 29, 2026Machine learning interatomic potentials (MLIPs) have proven to be wildly useful for molecular dynamics simulations, powering countless drug and materials discovery applications. However, MLIPs face two primary bottlenecks preventing them from reaching realistic simulation scales: inference time and memory consumption. In this work, we address both issues by challenging the long-held belief that the cutoff radius for the MLIP must be held to a fixed, constant value. For the first time, we introduce a dynamic cutoff formulation that still leads to stable, long timescale molecular dynamics simulation. In introducing the dynamic cutoff, we are able to induce sparsity onto the underlying atom graph by targeting a specific number of neighbors per atom, significantly reducing both memory consumption and inference time. We show the effectiveness of a dynamic cutoff by implementing it onto 4 state of the art MLIPs: MACE, Nequip, Orbv3, and TensorNet, leading to 2.26x less memory consumption and 2.04x faster inference time, depending on the model and atomic system. We also perform an extensive error analysis and find that the dynamic cutoff models exhibit minimal accuracy dropoff compared to their fixed cutoff counterparts on both materials and molecular datasets. All model implementations and training code will be fully open sourced.
Segmenting Objectiveness and Task-awareness Unknown Region for Autonomous Driving
Apr 27, 2025



With the emergence of transformer-based architectures and large language models (LLMs), the accuracy of road scene perception has substantially advanced. Nonetheless, current road scene segmentation approaches are predominantly trained on closed-set data, resulting in insufficient detection capabilities for out-of-distribution (OOD) objects. To overcome this limitation, road anomaly detection methods have been proposed. However, existing methods primarily depend on image inpainting and OOD distribution detection techniques, facing two critical issues: (1) inadequate consideration of the objectiveness attributes of anomalous regions, causing incomplete segmentation when anomalous objects share similarities with known classes, and (2) insufficient attention to environmental constraints, leading to the detection of anomalies irrelevant to autonomous driving tasks. In this paper, we propose a novel framework termed Segmenting Objectiveness and Task-Awareness (SOTA) for autonomous driving scenes. Specifically, SOTA enhances the segmentation of objectiveness through a Semantic Fusion Block (SFB) and filters anomalies irrelevant to road navigation tasks using a Scene-understanding Guided Prompt-Context Adaptor (SG-PCA). Extensive empirical evaluations on multiple benchmark datasets, including Fishyscapes Lost and Found, Segment-Me-If-You-Can, and RoadAnomaly, demonstrate that the proposed SOTA consistently improves OOD detection performance across diverse detectors, achieving robust and accurate segmentation outcomes.
Pragmatic Metacognitive Prompting Improves LLM Performance on Sarcasm Detection
Dec 04, 2024Sarcasm detection is a significant challenge in sentiment analysis due to the nuanced and context-dependent nature of verbiage. We introduce Pragmatic Metacognitive Prompting (PMP) to improve the performance of Large Language Models (LLMs) in sarcasm detection, which leverages principles from pragmatics and reflection helping LLMs interpret implied meanings, consider contextual cues, and reflect on discrepancies to identify sarcasm. Using state-of-the-art LLMs such as LLaMA-3-8B, GPT-4o, and Claude 3.5 Sonnet, PMP achieves state-of-the-art performance on GPT-4o on MUStARD and SemEval2018. This study demonstrates that integrating pragmatic reasoning and metacognitive strategies into prompting significantly enhances LLMs' ability to detect sarcasm, offering a promising direction for future research in sentiment analysis.
An Efficient Real-Time Object Detection Framework on Resource-Constricted Hardware Devices via Software and Hardware Co-design
Aug 20, 2024



The fast development of object detection techniques has attracted attention to developing efficient Deep Neural Networks (DNNs). However, the current state-of-the-art DNN models can not provide a balanced solution among accuracy, speed, and model size. This paper proposes an efficient real-time object detection framework on resource-constrained hardware devices through hardware and software co-design. The Tensor Train (TT) decomposition is proposed for compressing the YOLOv5 model. By unitizing the unique characteristics given by the TT decomposition, we develop an efficient hardware accelerator based on FPGA devices. Experimental results show that the proposed method can significantly reduce the model size and improve the execution time.
Pegasus-v1 Technical Report
Apr 23, 2024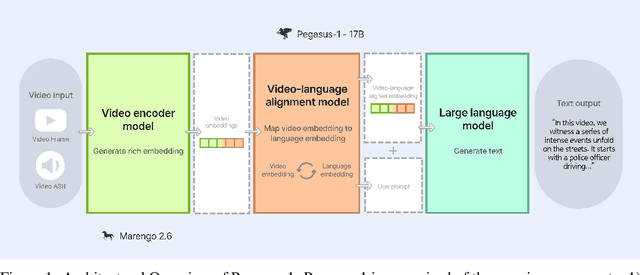
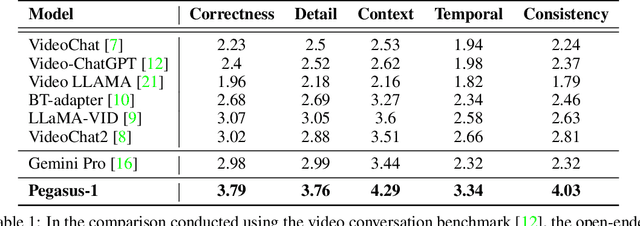


This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.
CHGNet: Pretrained universal neural network potential for charge-informed atomistic modeling
Feb 28, 2023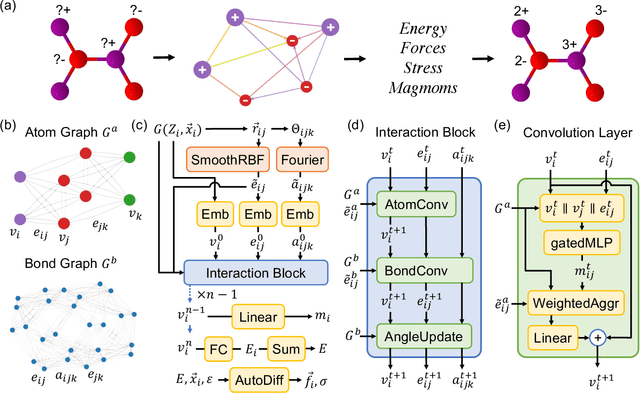
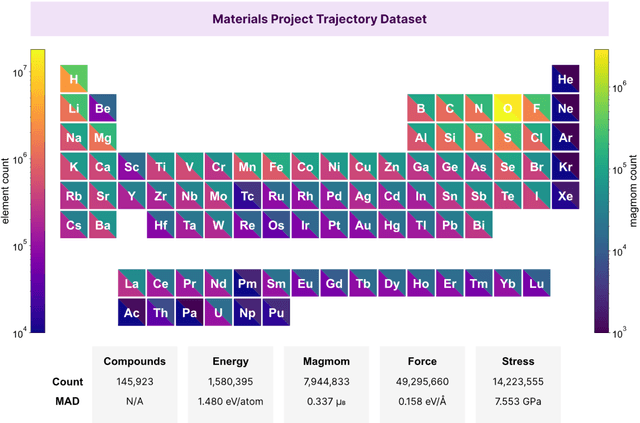
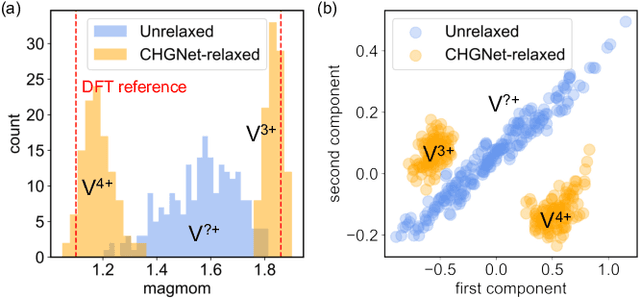
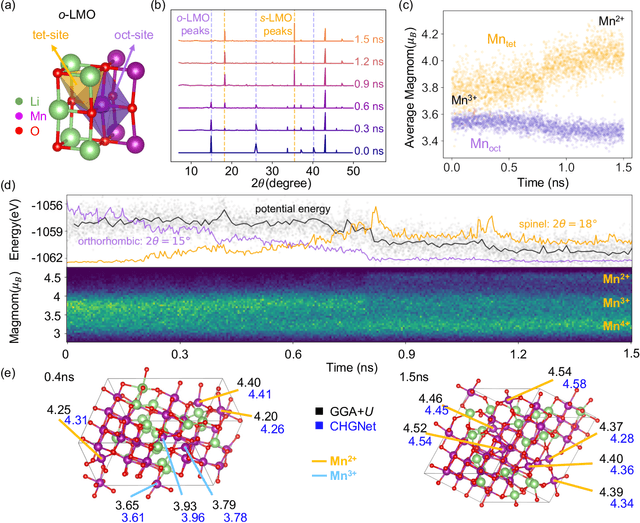
The simulation of large-scale systems with complex electron interactions remains one of the greatest challenges for the atomistic modeling of materials. Although classical force-fields often fail to describe the coupling between electronic states and ionic rearrangements, the more accurate \textit{ab-initio} molecular dynamics suffers from computational complexity that prevents long-time and large-scale simulations, which are essential to study many technologically relevant phenomena, such as reactions, ion migrations, phase transformations, and degradation. In this work, we present the Crystal Hamiltonian Graph neural Network (CHGNet) as a novel machine-learning interatomic potential (MLIP), using a graph-neural-network-based force-field to model a universal potential energy surface. CHGNet is pretrained on the energies, forces, stresses, and magnetic moments from the Materials Project Trajectory Dataset, which consists of over 10 years of density functional theory static and relaxation trajectories of $\sim 1.5$ million inorganic structures. The explicit inclusion of magnetic moments enables CHGNet to learn and accurately represent the orbital occupancy of electrons, enhancing its capability to describe both atomic and electronic degrees of freedom. We demonstrate several applications of CHGNet in solid-state materials, including charge-informed molecular dynamics in Li$_x$MnO$_2$, the finite temperature phase diagram for Li$_x$FePO$_4$ and Li diffusion in garnet conductors. We critically analyze the significance of including charge information for capturing appropriate chemistry, and we provide new insights into ionic systems with additional electronic degrees of freedom that can not be observed by previous MLIPs.
Toward Automated Virtual Assembly for Prefabricated Construction: Construction Sequencing through Simulated BIM
Mar 14, 2020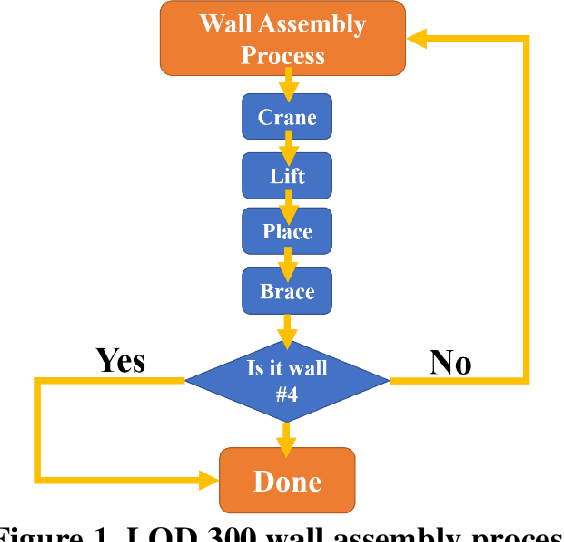
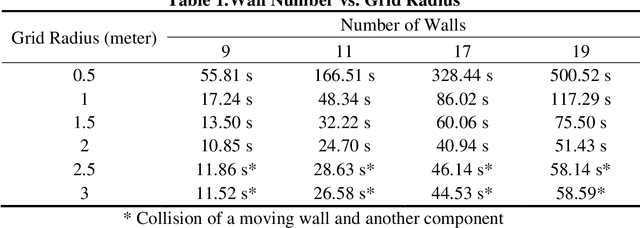
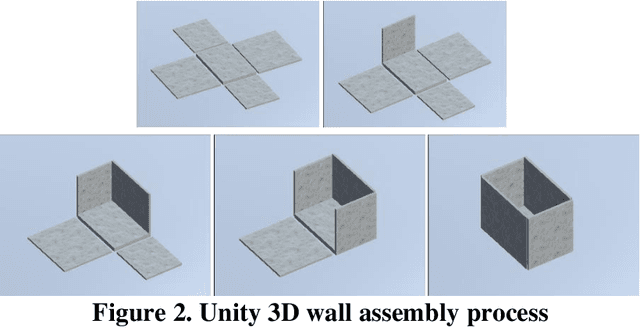
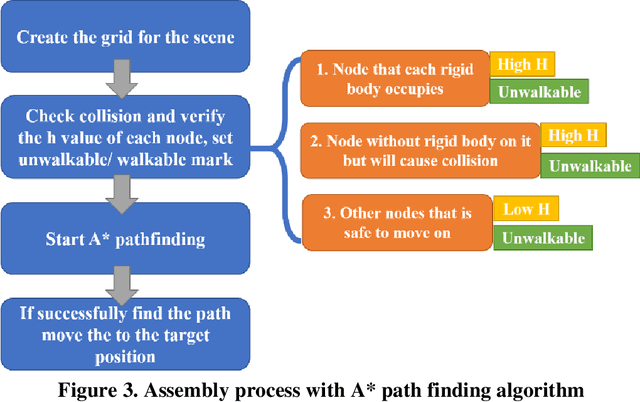
To adhere to the stringent time and budget requirements of construction projects, contractors are utilizing prefabricated construction methods to expedite the construction process. Prefabricated construction methods require an adequate schedule and understanding by the contractors and constructors to be successful. The specificity of prefabricated construction often leads to inefficient scheduling and costly rework time. The designer, contractor, and constructors must have a strong understanding of the assembly process to experience the full benefits of the method. At the root of understanding the assembly process is visualizing how the process is intended to be performed. Currently, a virtual construction model is used to explain and better visualize the construction process. However, creating a virtual construction model is currently time consuming and requires experienced personnel. The proposed simulation of the virtual assembly will increase the automation of virtual construction modeling by implementing the data available in a building information modeling (BIM) model. This paper presents various factors (i.e., formalization of construction sequence based on the level of development (LOD)) that needs to be addressed for the development of automated virtual assembly. Two case studies are presented to demonstrate these factors.
Real-world Mapping of Gaze Fixations Using Instance Segmentation for Road Construction Safety Applications
Feb 01, 2019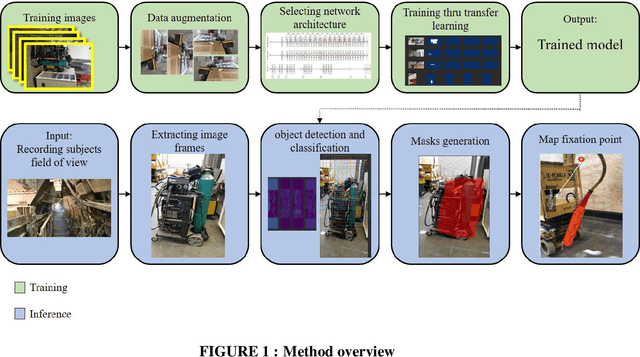
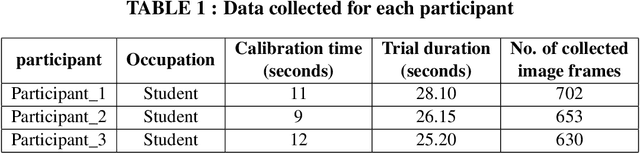

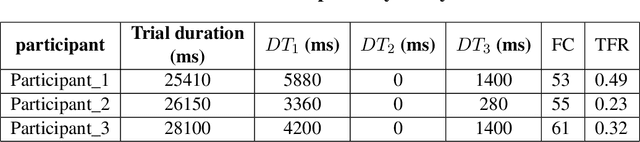
Research studies have shown that a large proportion of hazards remain unrecognized, which expose construction workers to unanticipated safety risks. Recent studies have also found that a strong correlation exists between viewing patterns of workers, captured using eye-tracking devices, and their hazard recognition performance. Therefore, it is important to analyze the viewing patterns of workers to gain a better understanding of their hazard recognition performance. This paper proposes a method that can automatically map the gaze fixations collected using a wearable eye-tracker to the predefined areas of interests. The proposed method detects these areas or objects (i.e., hazards) of interests through a computer vision-based segmentation technique and transfer learning. The mapped fixation data is then used to analyze the viewing behaviors of workers and compute their attention distribution. The proposed method is implemented on an under construction road as a case study to evaluate the performance of the proposed method.
Real-time Scene Segmentation Using a Light Deep Neural Network Architecture for Autonomous Robot Navigation on Construction Sites
Jan 24, 2019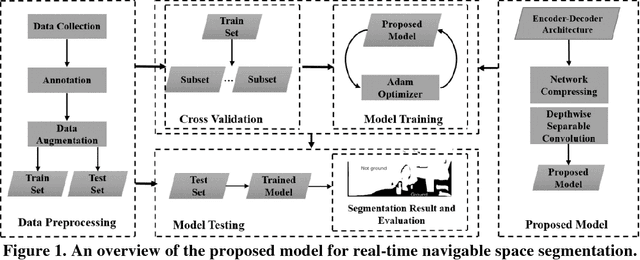
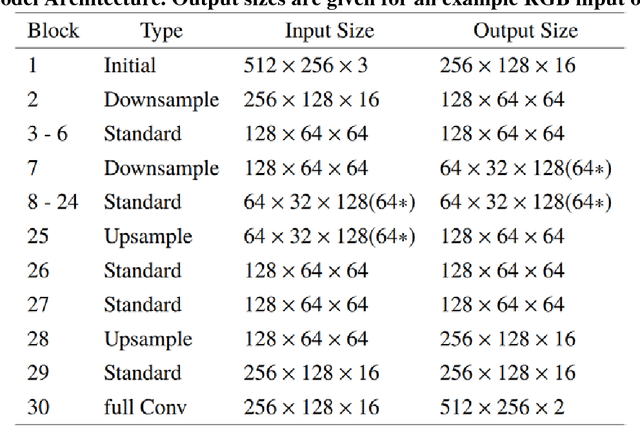
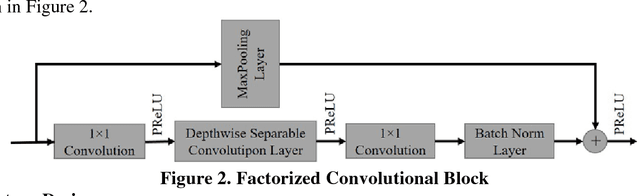
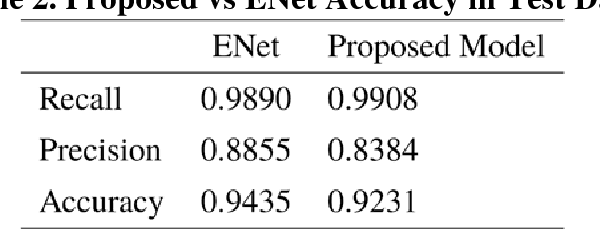
Camera-equipped unmanned vehicles (UVs) have received a lot of attention in data collection for construction monitoring applications. To develop an autonomous platform, the UV should be able to process multiple modules (e.g., context-awareness, control, localization, and mapping) on an embedded platform. Pixel-wise semantic segmentation provides a UV with the ability to be contextually aware of its surrounding environment. However, in the case of mobile robotic systems with limited computing resources, the large size of the segmentation model and high memory usage requires high computing resources, which a major challenge for mobile UVs (e.g., a small-scale vehicle with limited payload and space). To overcome this challenge, this paper presents a light and efficient deep neural network architecture to run on an embedded platform in real-time. The proposed model segments navigable space on an image sequence (i.e., a video stream), which is essential for an autonomous vehicle that is based on machine vision. The results demonstrate the performance efficiency of the proposed architecture compared to the existing models and suggest possible improvements that could make the model even more efficient, which is necessary for the future development of the autonomous robotics systems.