 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-world Mapping of Gaze Fixations Using Instance Segmentation for Road Construction Safety Applications
Feb 01, 2019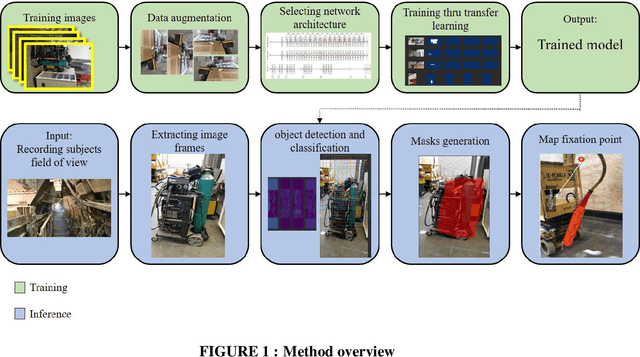
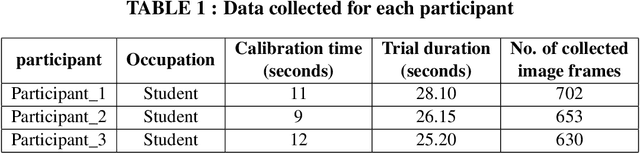

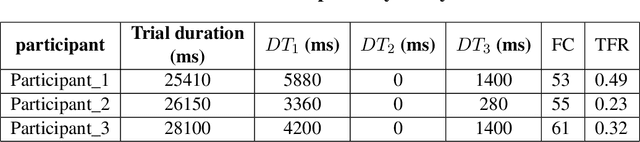
Research studies have shown that a large proportion of hazards remain unrecognized, which expose construction workers to unanticipated safety risks. Recent studies have also found that a strong correlation exists between viewing patterns of workers, captured using eye-tracking devices, and their hazard recognition performance. Therefore, it is important to analyze the viewing patterns of workers to gain a better understanding of their hazard recognition performance. This paper proposes a method that can automatically map the gaze fixations collected using a wearable eye-tracker to the predefined areas of interests. The proposed method detects these areas or objects (i.e., hazards) of interests through a computer vision-based segmentation technique and transfer learning. The mapped fixation data is then used to analyze the viewing behaviors of workers and compute their attention distribution. The proposed method is implemented on an under construction road as a case study to evaluate the performance of the proposed method.
Real-time Scene Segmentation Using a Light Deep Neural Network Architecture for Autonomous Robot Navigation on Construction Sites
Jan 24, 2019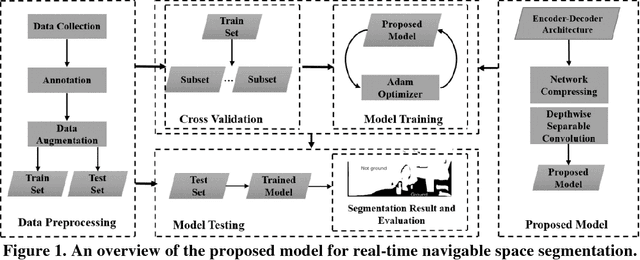
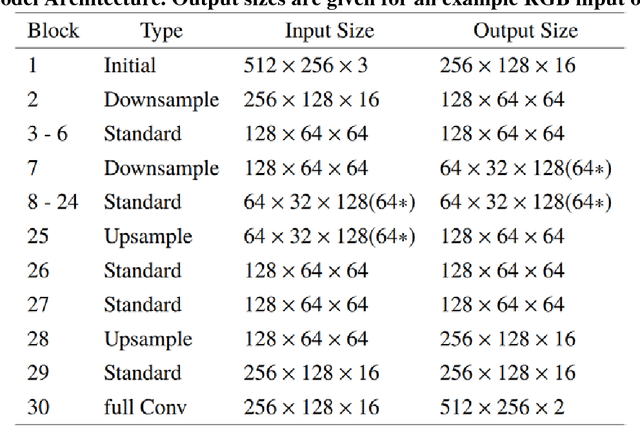
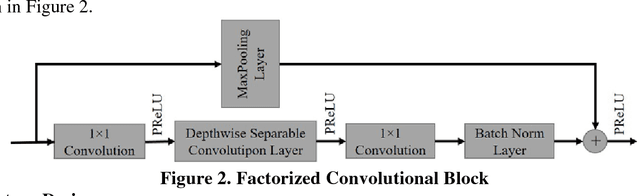
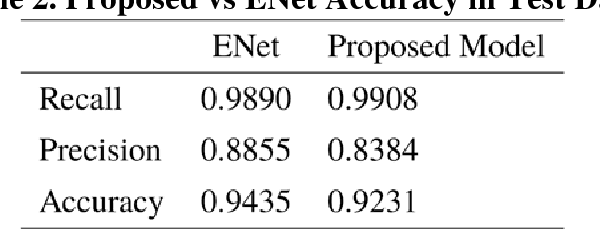
Camera-equipped unmanned vehicles (UVs) have received a lot of attention in data collection for construction monitoring applications. To develop an autonomous platform, the UV should be able to process multiple modules (e.g., context-awareness, control, localization, and mapping) on an embedded platform. Pixel-wise semantic segmentation provides a UV with the ability to be contextually aware of its surrounding environment. However, in the case of mobile robotic systems with limited computing resources, the large size of the segmentation model and high memory usage requires high computing resources, which a major challenge for mobile UVs (e.g., a small-scale vehicle with limited payload and space). To overcome this challenge, this paper presents a light and efficient deep neural network architecture to run on an embedded platform in real-time. The proposed model segments navigable space on an image sequence (i.e., a video stream), which is essential for an autonomous vehicle that is based on machine vision. The results demonstrate the performance efficiency of the proposed architecture compared to the existing models and suggest possible improvements that could make the model even more efficient, which is necessary for the future development of the autonomous robotics systems.
Vision-based Obstacle Removal System for Autonomous Ground Vehicles Using a Robotic Arm
Jan 24, 2019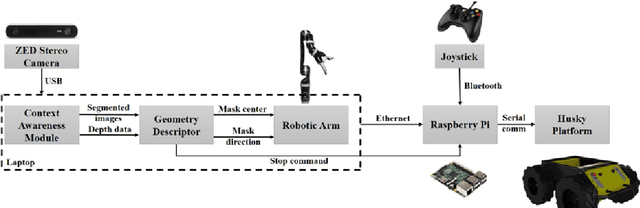

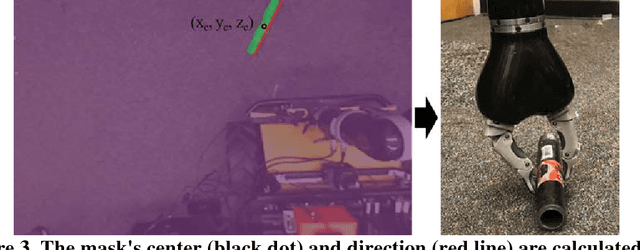

Over the past few years, the use of camera-equipped robotic platforms for data collection and visually monitoring applications has exponentially grown. Cluttered construction sites with many objects (e.g., bricks, pipes, etc.) on the ground are challenging environments for a mobile unmanned ground vehicle (UGV) to navigate. To address this issue, this study presents a mobile UGV equipped with a stereo camera and a robotic arm that can remove obstacles along the UGV's path. To achieve this objective, the surrounding environment is captured by the stereo camera and obstacles are detected. The obstacle's relative location to the UGV is sent to the robotic arm module through Robot Operating System (ROS). Then, the robotic arm picks up and removes the obstacle. The proposed method will greatly enhance the degree of automation and the frequency of data collection for construction monitoring. The proposed system is validated through two case studies. The results successfully demonstrate the detection and removal of obstacles, serving as one of the enabling factors for developing an autonomous UGV with various construction operating applications.
Building an Integrated Mobile Robotic System for Real-Time Applications in Construction
Apr 18, 2018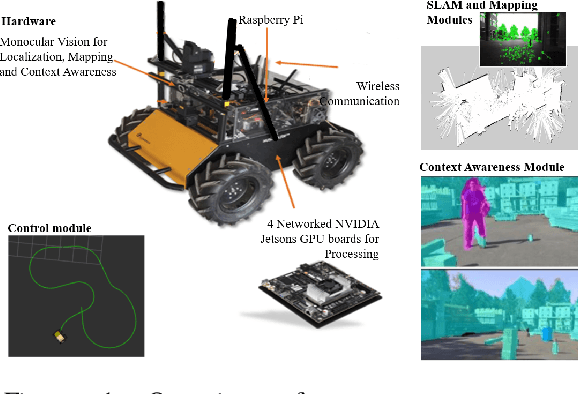
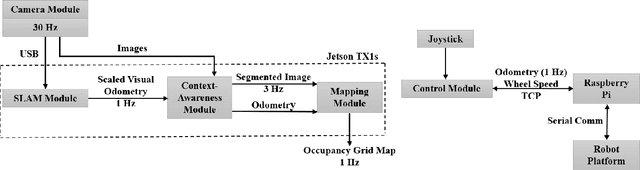

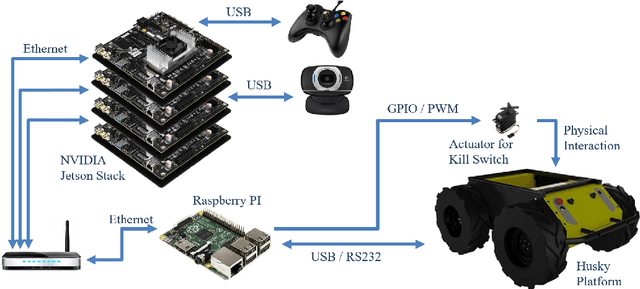
One of the major challenges of a real-time autonomous robotic system for construction monitoring is to simultaneously localize, map, and navigate over the lifetime of the robot, with little or no human intervention. Past research on Simultaneous Localization and Mapping (SLAM) and context-awareness are two active research areas in the computer vision and robotics communities. The studies that integrate both in real-time into a single modular framework for construction monitoring still need further investigation. A monocular vision system and real-time scene understanding are computationally heavy and the major state-of-the-art algorithms are tested on high-end desktops and/or servers with a high CPU- and/or GPU- computing capabilities, which affect their mobility and deployment for real-world applications. To address these challenges and achieve automation, this paper proposes an integrated robotic computer vision system, which generates a real-world spatial map of the obstacles and traversable space present in the environment in near real-time. This is done by integrating contextual Awareness and visual SLAM into a ground robotics agent. This paper presents the hardware utilization and performance of the aforementioned system for three different outdoor environments, which represent the applicability of this pipeline to diverse outdoor scenes in near real-time. The entire system is also self-contained and does not require user input, which demonstrates the potential of this computer vision system for autonomous navigation.