 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewSynth: Learning Local Features from Depth using View Synthesis
Nov 22, 2019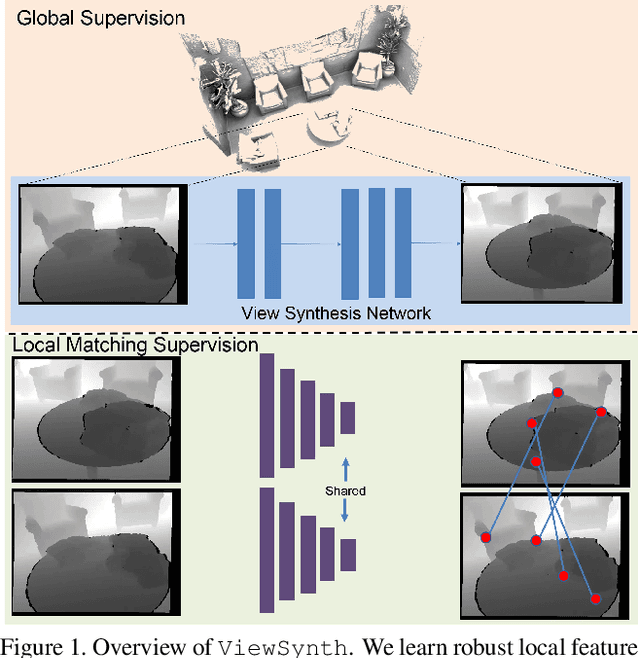

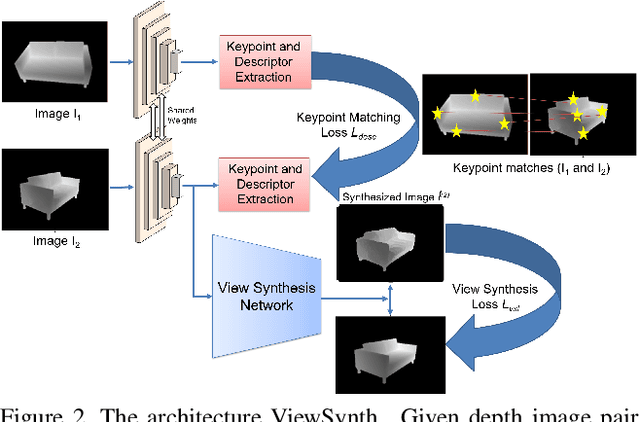
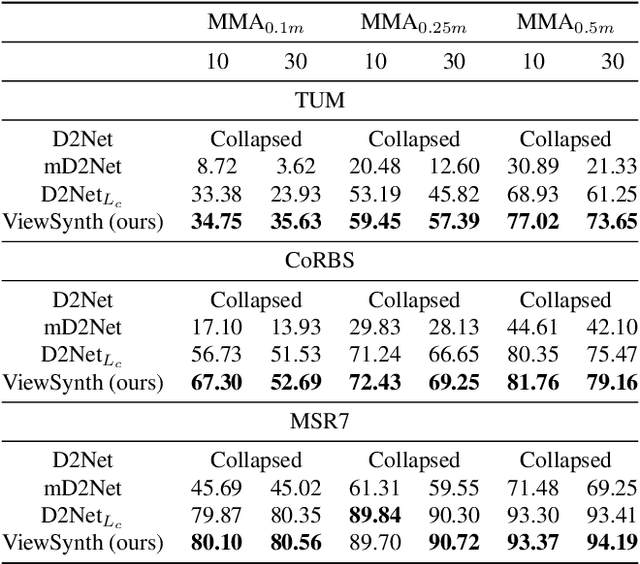
We address the problem of jointly detecting keypoints and learning descriptors in depth data with challenging viewpoint changes. Despite great improvements in recent RGB based local feature learning methods, we show that these methods cannot be directly transferred to the depth image modality. These methods also do not utilize the 2.5D information present in depth images. We propose a framework ViewSynth, designed to jointly learn 3D structure aware depth image representation, and local features from that representation. ViewSynth consists of `View Synthesis Network' (VSN), trained to synthesize depth image views given a depth image representation and query viewpoints. ViewSynth framework includes joint learning of keypoints and feature descriptor, paired with our view synthesis loss, which guides the model to propose keypoints robust to viewpoint changes. We demonstrate the effectiveness of our formulation on several depth image datasets, where learned local features using our proposed ViewSynth framework outperforms the state-of-the-art methods in keypoint matching and camera localization tasks.
Building an Integrated Mobile Robotic System for Real-Time Applications in Construction
Apr 18, 2018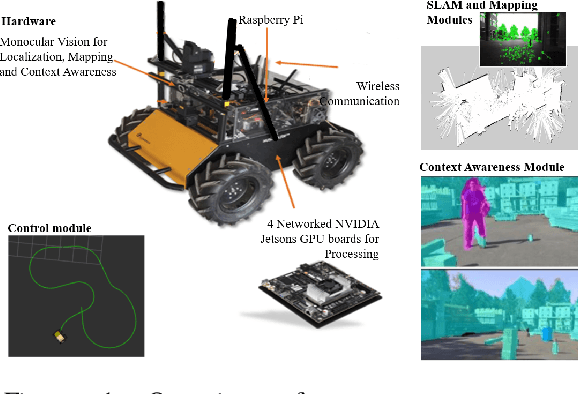
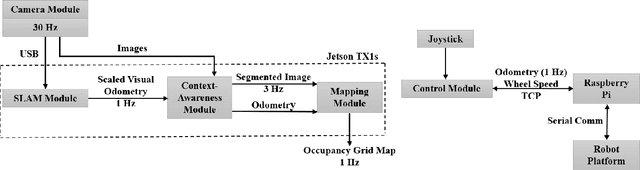

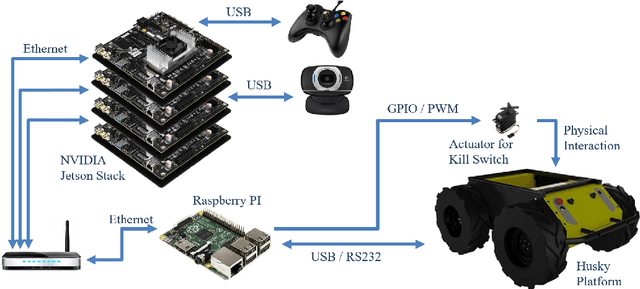
One of the major challenges of a real-time autonomous robotic system for construction monitoring is to simultaneously localize, map, and navigate over the lifetime of the robot, with little or no human intervention. Past research on Simultaneous Localization and Mapping (SLAM) and context-awareness are two active research areas in the computer vision and robotics communities. The studies that integrate both in real-time into a single modular framework for construction monitoring still need further investigation. A monocular vision system and real-time scene understanding are computationally heavy and the major state-of-the-art algorithms are tested on high-end desktops and/or servers with a high CPU- and/or GPU- computing capabilities, which affect their mobility and deployment for real-world applications. To address these challenges and achieve automation, this paper proposes an integrated robotic computer vision system, which generates a real-world spatial map of the obstacles and traversable space present in the environment in near real-time. This is done by integrating contextual Awareness and visual SLAM into a ground robotics agent. This paper presents the hardware utilization and performance of the aforementioned system for three different outdoor environments, which represent the applicability of this pipeline to diverse outdoor scenes in near real-time. The entire system is also self-contained and does not require user input, which demonstrates the potential of this computer vision system for autonomous navigation.