 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A 3D Probabilistic Neural Representation for Interpretable Shape Modeling
Feb 12, 2026Understanding how anatomical shapes evolve in response to developmental covariates and quantifying their spatially varying uncertainties is critical in healthcare research. Existing approaches typically rely on global time-warping formulations that ignore spatially heterogeneous dynamics. We introduce PRISM, a novel framework that bridges implicit neural representations with uncertainty-aware statistical shape analysis. PRISM models the conditional distribution of shapes given covariates, providing spatially continuous estimates of both the population mean and covariate-dependent uncertainty at arbitrary locations. A key theoretical contribution is a closed-form Fisher Information metric that enables efficient, analytically tractable local temporal uncertainty quantification via automatic differentiation. Experiments on three synthetic datasets and one clinical dataset demonstrate PRISM's strong performance across diverse tasks within a unified framework, while providing interpretable and clinically meaningful uncertainty estimates.
$\texttt{LucidAtlas}$: Learning Uncertainty-Aware, Covariate-Disentangled, Individualized Atlas Representations
Feb 12, 2025The goal of this work is to develop principled techniques to extract information from high dimensional data sets with complex dependencies in areas such as medicine that can provide insight into individual as well as population level variation. We develop $\texttt{LucidAtlas}$, an approach that can represent spatially varying information, and can capture the influence of covariates as well as population uncertainty. As a versatile atlas representation, $\texttt{LucidAtlas}$ offers robust capabilities for covariate interpretation, individualized prediction, population trend analysis, and uncertainty estimation, with the flexibility to incorporate prior knowledge. Additionally, we discuss the trustworthiness and potential risks of neural additive models for analyzing dependent covariates and then introduce a marginalization approach to explain the dependence of an individual predictor on the models' response (the atlas). To validate our method, we demonstrate its generalizability on two medical datasets. Our findings underscore the critical role of by-construction interpretable models in advancing scientific discovery. Our code will be publicly available upon acceptance.
NAISR: A 3D Neural Additive Model for Interpretable Shape Representation
Mar 28, 2023
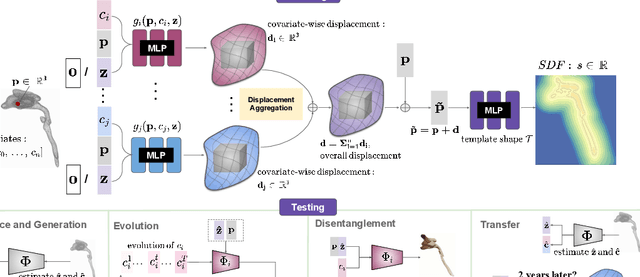

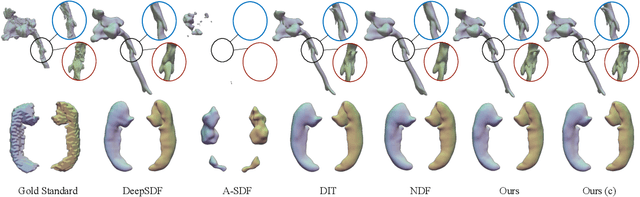
Deep implicit functions (DIFs) have emerged as a powerful paradigm for many computer vision tasks such as 3D shape reconstruction, generation, registration, completion, editing, and understanding. However, given a set of 3D shapes with associated covariates there is at present no shape representation method which allows to precisely represent the shapes while capturing the individual dependencies on each covariate. Such a method would be of high utility to researchers to discover knowledge hidden in a population of shapes. We propose a 3D Neural Additive Model for Interpretable Shape Representation (NAISR) which describes individual shapes by deforming a shape atlas in accordance to the effect of disentangled covariates. Our approach captures shape population trends and allows for patient-specific predictions through shape transfer. NAISR is the first approach to combine the benefits of deep implicit shape representations with an atlas deforming according to specified covariates. Although our driving problem is the construction of an airway atlas, NAISR is a general approach for modeling, representing, and investigating shape populations. We evaluate NAISR with respect to shape reconstruction, shape disentanglement, shape evolution, and shape transfer for the pediatric upper airway. Our experiments demonstrate that NAISR achieves competitive shape reconstruction performance while retaining interpretability.
VPFusion: Joint 3D Volume and Pixel-Aligned Feature Fusion for Single and Multi-view 3D Reconstruction
Mar 14, 2022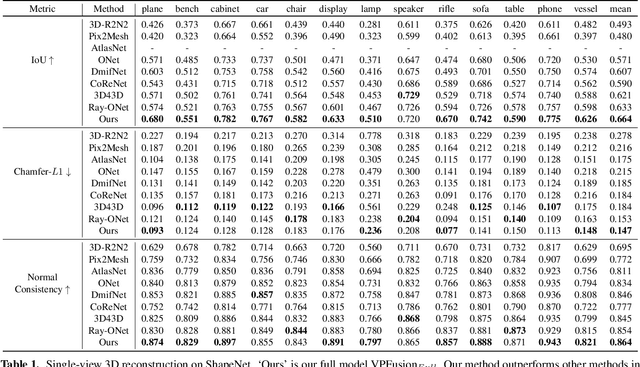
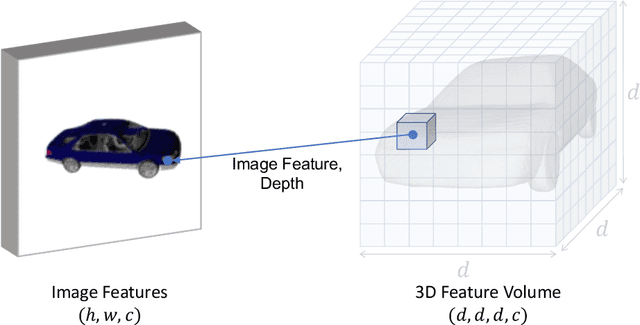
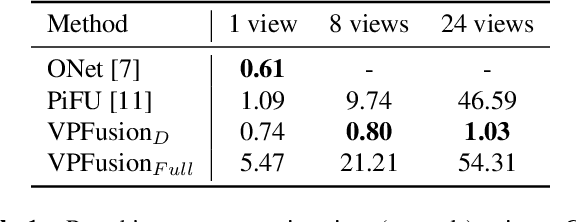

We introduce a unified single and multi-view neural implicit 3D reconstruction framework VPFusion. VPFusion~attains high-quality reconstruction using both - 3D feature volume to capture 3D-structure-aware context, and pixel-aligned image features to capture fine local detail. Existing approaches use RNN, feature pooling, or attention computed independently in each view for multi-view fusion. RNNs suffer from long-term memory loss and permutation variance, while feature pooling or independently computed attention leads to representation in each view being unaware of other views before the final pooling step. In contrast, we show improved multi-view feature fusion by establishing transformer-based pairwise view association. In particular, we propose a novel interleaved 3D reasoning and pairwise view association architecture for feature volume fusion across different views. Using this structure-aware and multi-view-aware feature volume, we show improved 3D reconstruction performance compared to existing methods. VPFusion improves the reconstruction quality further by also incorporating pixel-aligned local image features to capture fine detail. We verify the effectiveness of VPFusion~on the ShapeNet and ModelNet datasets, where we outperform or perform on-par the state-of-the-art single and multi-view 3D shape reconstruction methods.
ViewSynth: Learning Local Features from Depth using View Synthesis
Nov 22, 2019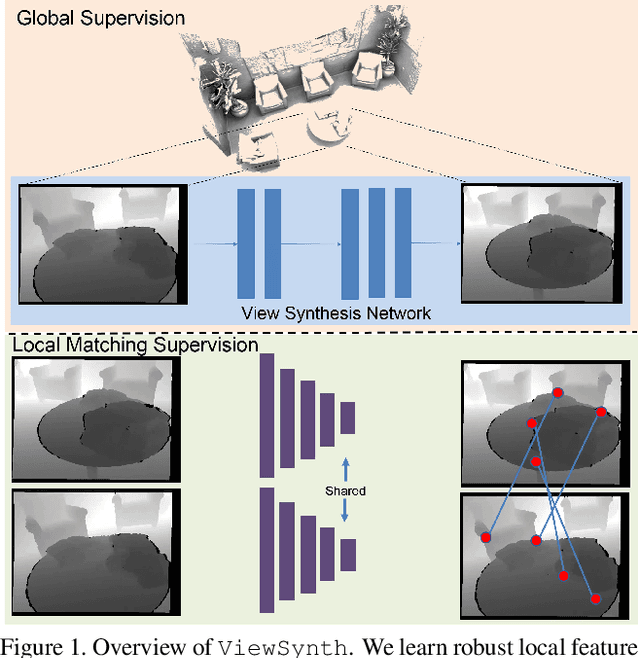

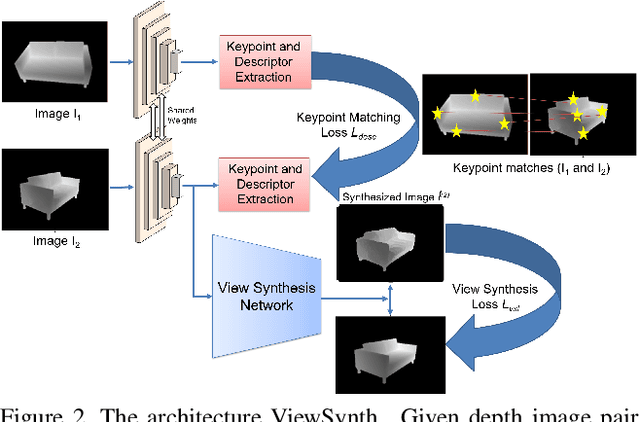
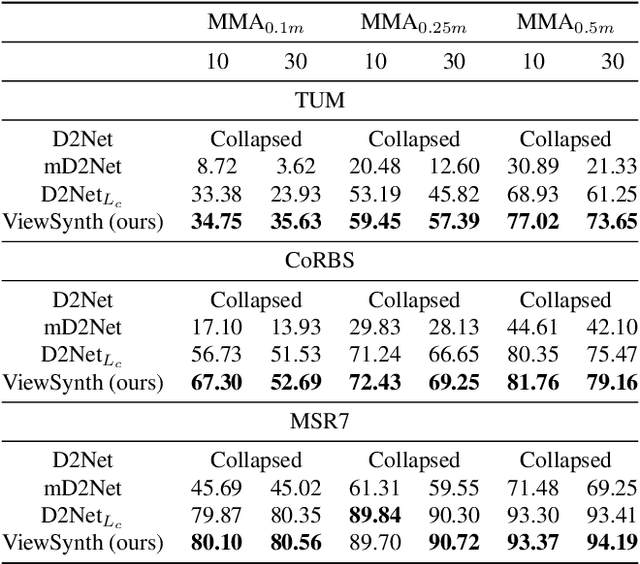
We address the problem of jointly detecting keypoints and learning descriptors in depth data with challenging viewpoint changes. Despite great improvements in recent RGB based local feature learning methods, we show that these methods cannot be directly transferred to the depth image modality. These methods also do not utilize the 2.5D information present in depth images. We propose a framework ViewSynth, designed to jointly learn 3D structure aware depth image representation, and local features from that representation. ViewSynth consists of `View Synthesis Network' (VSN), trained to synthesize depth image views given a depth image representation and query viewpoints. ViewSynth framework includes joint learning of keypoints and feature descriptor, paired with our view synthesis loss, which guides the model to propose keypoints robust to viewpoint changes. We demonstrate the effectiveness of our formulation on several depth image datasets, where learned local features using our proposed ViewSynth framework outperforms the state-of-the-art methods in keypoint matching and camera localization tasks.