 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPFusion: Joint 3D Volume and Pixel-Aligned Feature Fusion for Single and Multi-view 3D Reconstruction
Paper and Code
Mar 14, 2022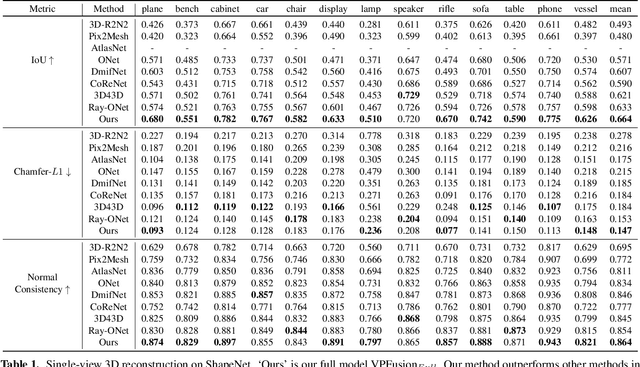
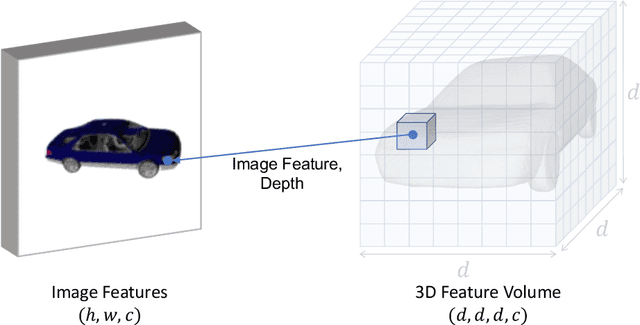
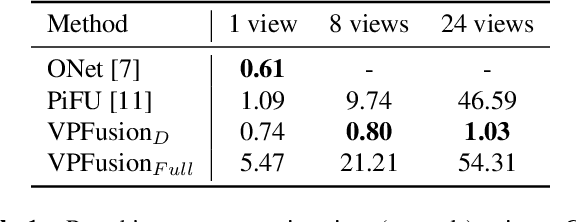

We introduce a unified single and multi-view neural implicit 3D reconstruction framework VPFusion. VPFusion~attains high-quality reconstruction using both - 3D feature volume to capture 3D-structure-aware context, and pixel-aligned image features to capture fine local detail. Existing approaches use RNN, feature pooling, or attention computed independently in each view for multi-view fusion. RNNs suffer from long-term memory loss and permutation variance, while feature pooling or independently computed attention leads to representation in each view being unaware of other views before the final pooling step. In contrast, we show improved multi-view feature fusion by establishing transformer-based pairwise view association. In particular, we propose a novel interleaved 3D reasoning and pairwise view association architecture for feature volume fusion across different views. Using this structure-aware and multi-view-aware feature volume, we show improved 3D reconstruction performance compared to existing methods. VPFusion improves the reconstruction quality further by also incorporating pixel-aligned local image features to capture fine detail. We verify the effectiveness of VPFusion~on the ShapeNet and ModelNet datasets, where we outperform or perform on-par the state-of-the-art single and multi-view 3D shape reconstruction methods.