 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-based Differentiable Depth Sensor Simulation
Mar 30, 2021
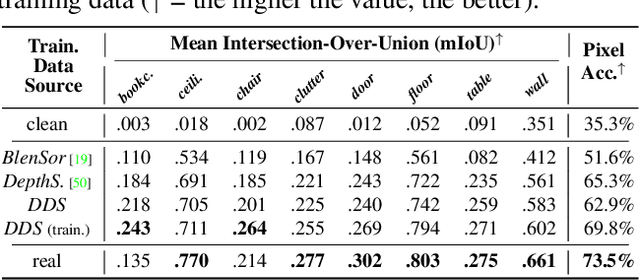
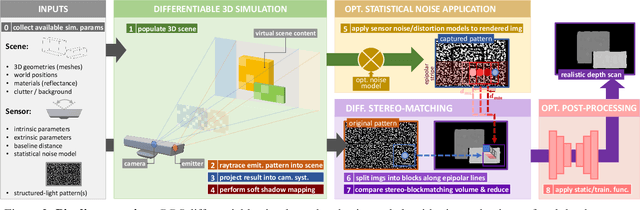
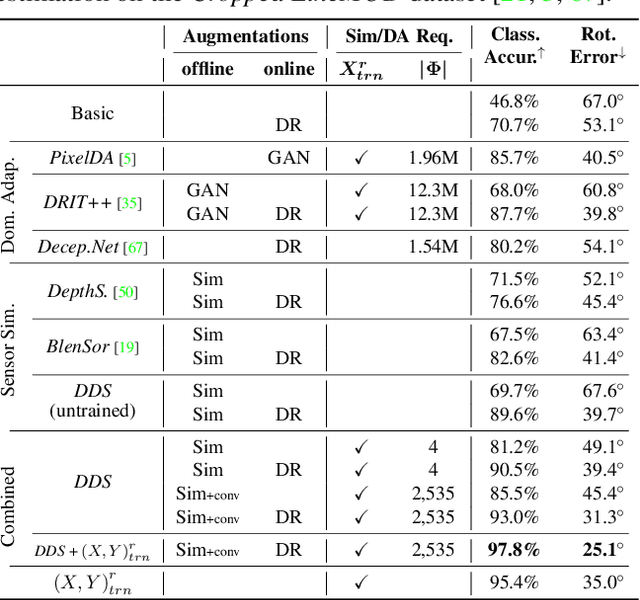
Gradient-based algorithms are crucial to modern computer-vision and graphics applications, enabling learning-based optimization and inverse problems. For example, photorealistic differentiable rendering pipelines for color images have been proven highly valuable to applications aiming to map 2D and 3D domains. However, to the best of our knowledge, no effort has been made so far towards extending these gradient-based methods to the generation of depth (2.5D) images, as simulating structured-light depth sensors implies solving complex light transport and stereo-matching problems. In this paper, we introduce a novel end-to-end differentiable simulation pipeline for the generation of realistic 2.5D scans, built on physics-based 3D rendering and custom block-matching algorithms. Each module can be differentiated w.r.t sensor and scene parameters; e.g., to automatically tune the simulation for new devices over some provided scans or to leverage the pipeline as a 3D-to-2.5D transformer within larger computer-vision applications. Applied to the training of deep-learning methods for various depth-based recognition tasks (classification, pose estimation, semantic segmentation), our simulation greatly improves the performance of the resulting models on real scans, thereby demonstrating the fidelity and value of its synthetic depth data compared to previous static simulations and learning-based domain adaptation schemes.
ViewSynth: Learning Local Features from Depth using View Synthesis
Nov 22, 2019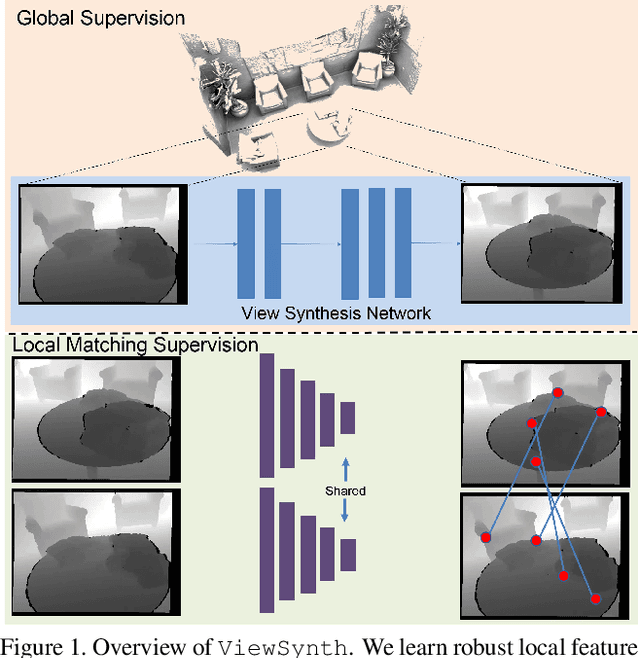

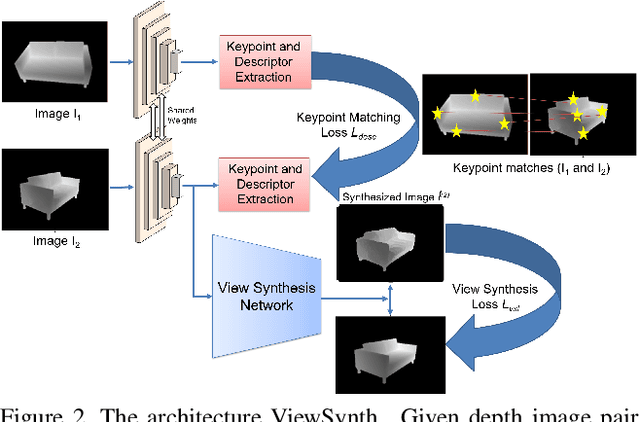
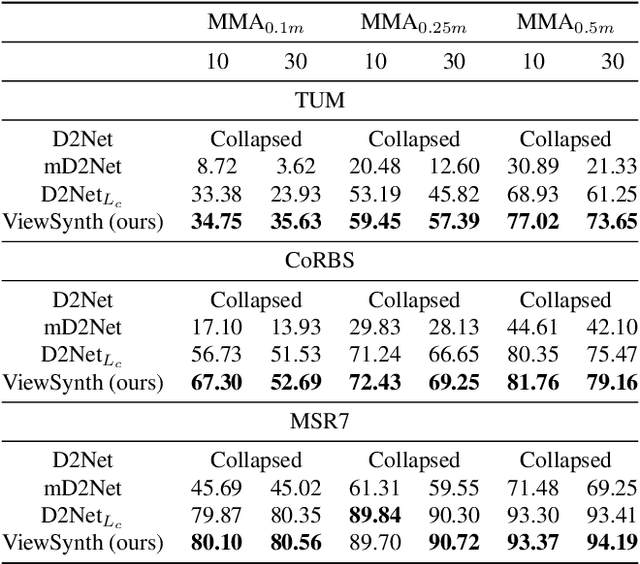
We address the problem of jointly detecting keypoints and learning descriptors in depth data with challenging viewpoint changes. Despite great improvements in recent RGB based local feature learning methods, we show that these methods cannot be directly transferred to the depth image modality. These methods also do not utilize the 2.5D information present in depth images. We propose a framework ViewSynth, designed to jointly learn 3D structure aware depth image representation, and local features from that representation. ViewSynth consists of `View Synthesis Network' (VSN), trained to synthesize depth image views given a depth image representation and query viewpoints. ViewSynth framework includes joint learning of keypoints and feature descriptor, paired with our view synthesis loss, which guides the model to propose keypoints robust to viewpoint changes. We demonstrate the effectiveness of our formulation on several depth image datasets, where learned local features using our proposed ViewSynth framework outperforms the state-of-the-art methods in keypoint matching and camera localization tasks.
Attention Guided Anomaly Detection and Localization in Images
Nov 19, 2019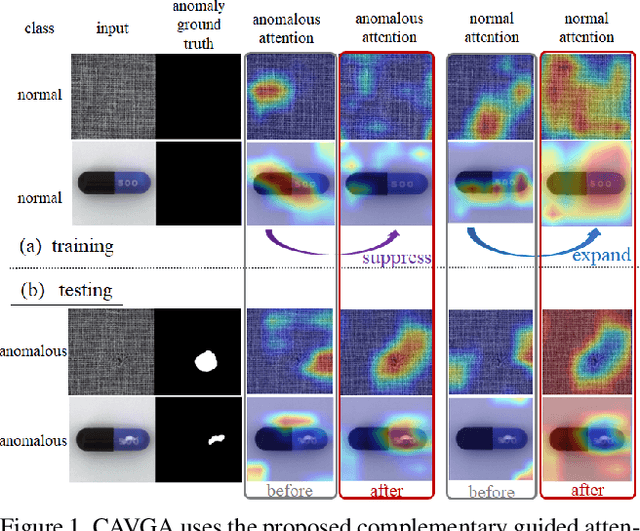

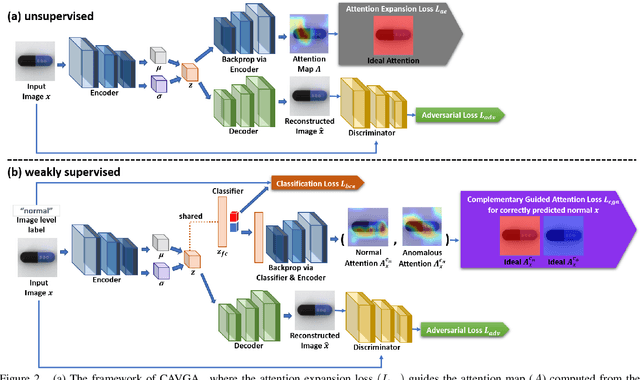
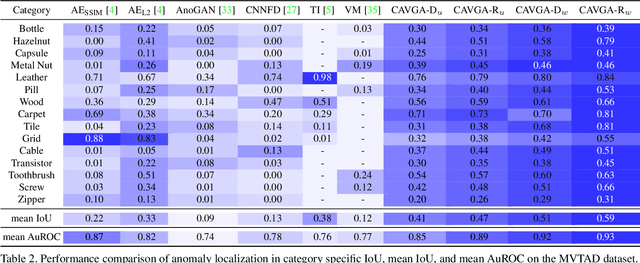
Anomaly detection and localization is a popular computer vision problem involving detecting anomalous images and localizing anomalies within them. However, this task is challenging due to the small sample size and pixel coverage of the anomaly in real-world scenarios. Prior works need to use anomalous training images to compute a threshold to detect and localize anomalies. To remove this need, we propose Convolutional Adversarial Variational autoencoder with Guided Attention (CAVGA), which localizes the anomaly with a convolutional latent variable to preserve the spatial information. In the unsupervised setting, we propose an attention expansion loss, where we encourage CAVGA to focus on all normal regions in the image without using any anomalous training image. Furthermore, using only 2% anomalous images in the weakly supervised setting we propose a complementary guided attention loss, where we encourage the normal attention to focus on all normal regions while minimizing the regions covered by the anomalous attention in the normal image. CAVGA outperforms the state-of-the-art (SOTA) anomaly detection methods on the MNIST, CIFAR-10, Fashion-MNIST, MVTec Anomaly Detection (MVTAD), and modified ShanghaiTech Campus (mSTC) datasets. CAVGA also outperforms the SOTA anomaly localization methods on the MVTAD and mSTC datasets.
Learning without Memorizing
Nov 20, 2018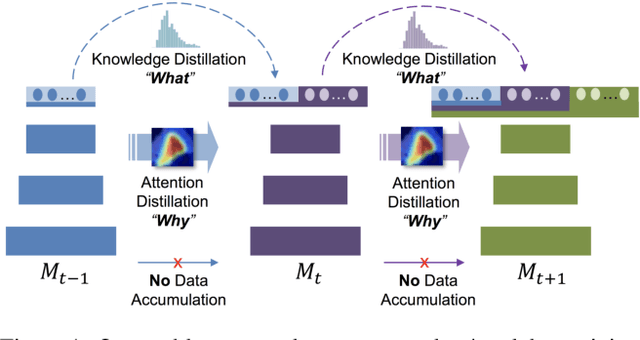


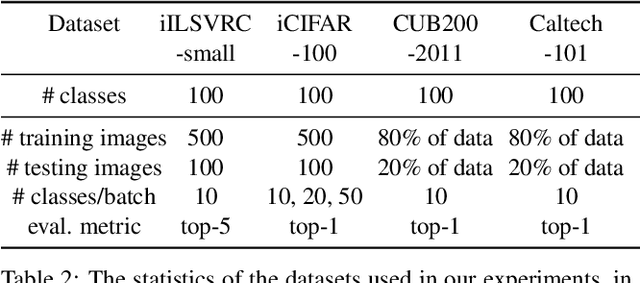
Incremental learning (IL) is an important task aimed to increase the capability of a trained model, in terms of the number of classes recognizable by the model. The key problem in this task is the requirement of storing data (e.g. images) associated with existing classes, while training the classifier to learn new classes. However, this is impractical as it increases the memory requirement at every incremental step, which makes it impossible to implement IL algorithms on the edge devices with limited memory. Hence, we propose a novel approach, called "Learning without Memorizing (LwM)", to preserve the information with respect to existing (base) classes, without storing any of their data, while making the classifier progressively learn the new classes. In LwM, we present an information preserving penalty: Attention Distillation Loss, and demonstrate that penalizing the changes in classifiers' attention maps helps to retain information of the base classes, as new classes are added. We show that adding Attention Distillation Loss to the distillation loss which is an existing information preserving loss consistently outperforms the state-of-the-art performance in the iILSVRC-small and iCIFAR-100 datasets in terms of the overall accuracy of base and incrementally learned classes.
Reducing Visual Confusion with Discriminative Attention
Nov 19, 2018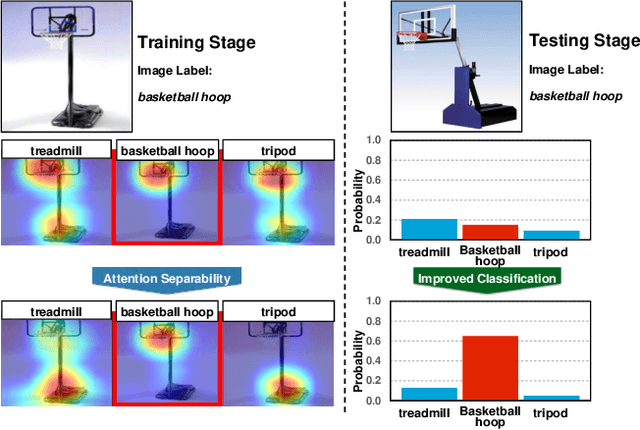
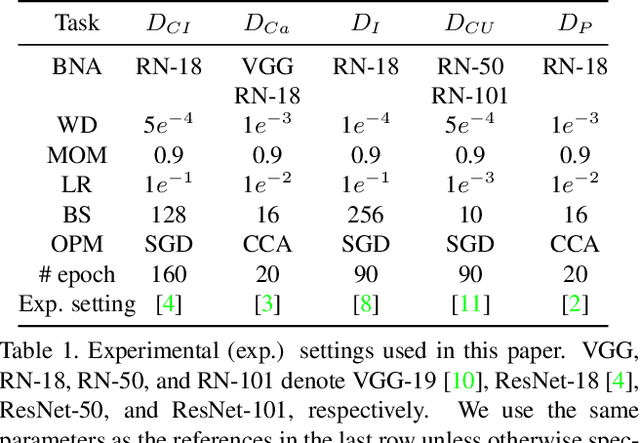
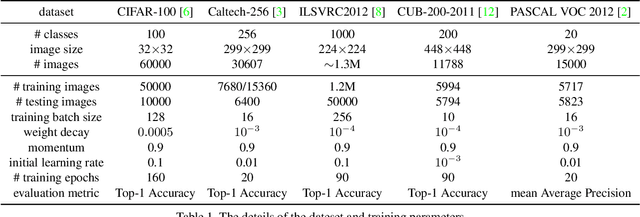
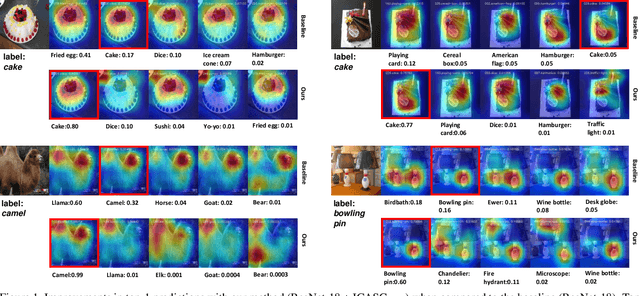
Recent developments in gradient-based attention modeling have led to improved model interpretability by means of class-specific attention maps. A key limitation, however, of these approaches is that the resulting attention maps, while being well localized, are not class discriminative. In this paper, we address this limitation with a new learning framework that makes class-discriminative attention and cross-layer attention consistency a principled and explicit part of the learning process. Furthermore, our framework provides attention guidance to the model in an end-to-end fashion, resulting in better discriminability and reduced visual confusion. We conduct extensive experiments on various image classification benchmarks with our proposed framework and demonstrate its efficacy by means of improved classification accuracy including CIFAR-100 (+3.46%), Caltech-256 (+1.64%), ImageNet (+0.92%), CUB-200-2011 (+4.8%) and PASCAL VOC2012 (+5.78%).