 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 2D Representation Learning with a 3D Prior
Jun 04, 2024



Learning robust and effective representations of visual data is a fundamental task in computer vision. Traditionally, this is achieved by training models with labeled data which can be expensive to obtain. Self-supervised learning attempts to circumvent the requirement for labeled data by learning representations from raw unlabeled visual data alone. However, unlike humans who obtain rich 3D information from their binocular vision and through motion, the majority of current self-supervised methods are tasked with learning from monocular 2D image collections. This is noteworthy as it has been demonstrated that shape-centric visual processing is more robust compared to texture-biased automated methods. Inspired by this, we propose a new approach for strengthening existing self-supervised methods by explicitly enforcing a strong 3D structural prior directly into the model during training. Through experiments, across a range of datasets, we demonstrate that our 3D aware representations are more robust compared to conventional self-supervised baselines.
EyePAD++: A Distillation-based approach for joint Eye Authentication and Presentation Attack Detection using Periocular Images
Dec 29, 2021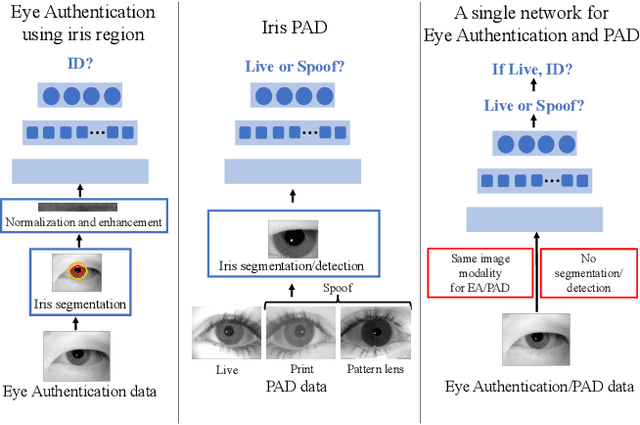

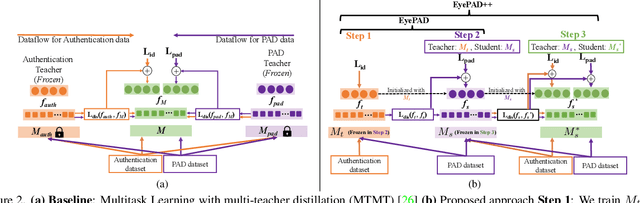
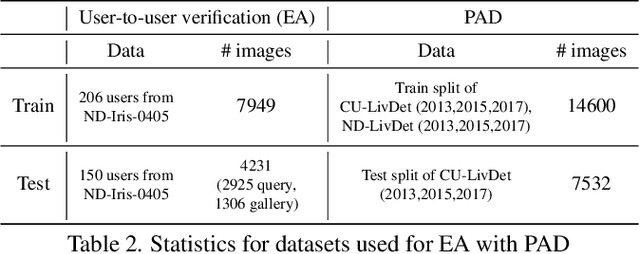
A practical eye authentication (EA) system targeted for edge devices needs to perform authentication and be robust to presentation attacks, all while remaining compute and latency efficient. However, existing eye-based frameworks a) perform authentication and Presentation Attack Detection (PAD) independently and b) involve significant pre-processing steps to extract the iris region. Here, we introduce a joint framework for EA and PAD using periocular images. While a deep Multitask Learning (MTL) network can perform both the tasks, MTL suffers from the forgetting effect since the training datasets for EA and PAD are disjoint. To overcome this, we propose Eye Authentication with PAD (EyePAD), a distillation-based method that trains a single network for EA and PAD while reducing the effect of forgetting. To further improve the EA performance, we introduce a novel approach called EyePAD++ that includes training an MTL network on both EA and PAD data, while distilling the `versatility' of the EyePAD network through an additional distillation step. Our proposed methods outperform the SOTA in PAD and obtain near-SOTA performance in eye-to-eye verification, without any pre-processing. We also demonstrate the efficacy of EyePAD and EyePAD++ in user-to-user verification with PAD across network backbones and image quality.
Distill and De-bias: Mitigating Bias in Face Recognition using Knowledge Distillation
Dec 17, 2021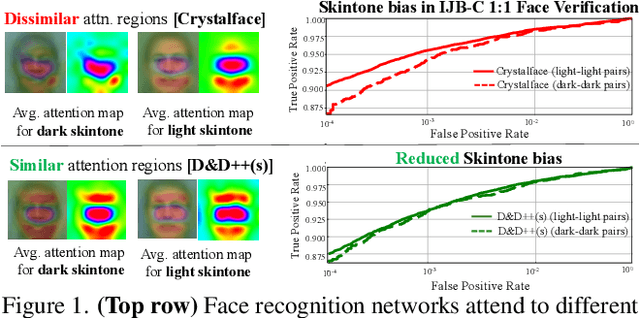
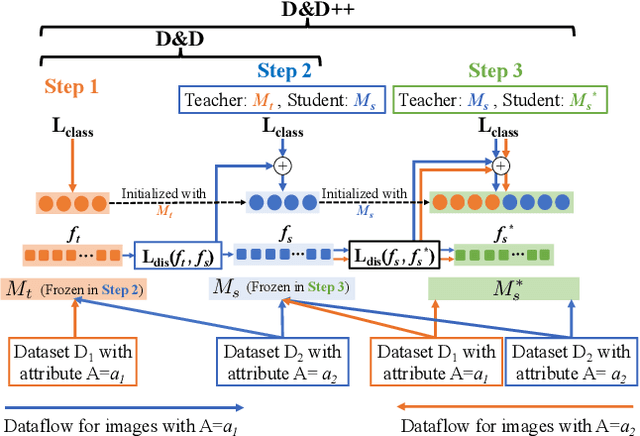
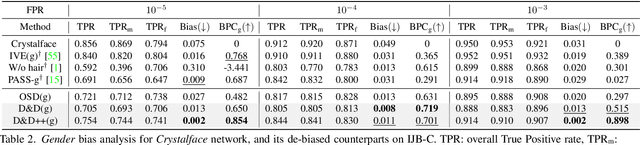
Face recognition networks generally demonstrate bias with respect to sensitive attributes like gender, skintone etc. For gender and skintone, we observe that the regions of the face that a network attends to vary by the category of an attribute. This might contribute to bias. Building on this intuition, we propose a novel distillation-based approach called Distill and De-bias (D&D) to enforce a network to attend to similar face regions, irrespective of the attribute category. In D&D, we train a teacher network on images from one category of an attribute; e.g. light skintone. Then distilling information from the teacher, we train a student network on images of the remaining category; e.g., dark skintone. A feature-level distillation loss constrains the student network to generate teacher-like representations. This allows the student network to attend to similar face regions for all attribute categories and enables it to reduce bias. We also propose a second distillation step on top of D&D, called D&D++. For the D&D++ network, we distill the `un-biasedness' of the D&D network into a new student network, the D&D++ network. We train the new network on all attribute categories; e.g., both light and dark skintones. This helps us train a network that is less biased for an attribute, while obtaining higher face verification performance than D&D. We show that D&D++ outperforms existing baselines in reducing gender and skintone bias on the IJB-C dataset, while obtaining higher face verification performance than existing adversarial de-biasing methods. We evaluate the effectiveness of our proposed methods on two state-of-the-art face recognition networks: Crystalface and ArcFace.
PASS: Protected Attribute Suppression System for Mitigating Bias in Face Recognition
Aug 09, 2021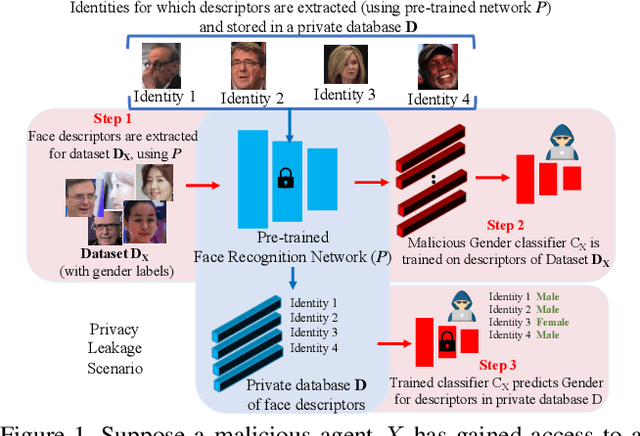
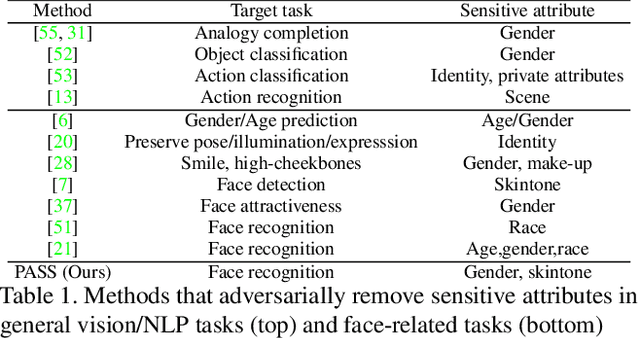
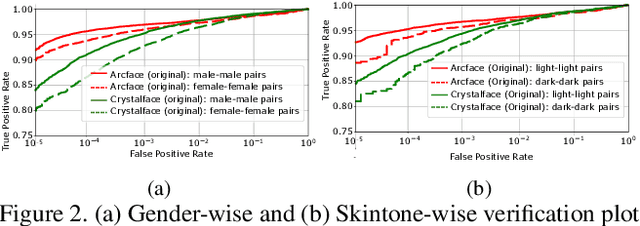

Face recognition networks encode information about sensitive attributes while being trained for identity classification. Such encoding has two major issues: (a) it makes the face representations susceptible to privacy leakage (b) it appears to contribute to bias in face recognition. However, existing bias mitigation approaches generally require end-to-end training and are unable to achieve high verification accuracy. Therefore, we present a descriptor-based adversarial de-biasing approach called `Protected Attribute Suppression System (PASS)'. PASS can be trained on top of descriptors obtained from any previously trained high-performing network to classify identities and simultaneously reduce encoding of sensitive attributes. This eliminates the need for end-to-end training. As a component of PASS, we present a novel discriminator training strategy that discourages a network from encoding protected attribute information. We show the efficacy of PASS to reduce gender and skintone information in descriptors from SOTA face recognition networks like Arcface. As a result, PASS descriptors outperform existing baselines in reducing gender and skintone bias on the IJB-C dataset, while maintaining a high verification accuracy.
An adversarial learning algorithm for mitigating gender bias in face recognition
Jun 14, 2020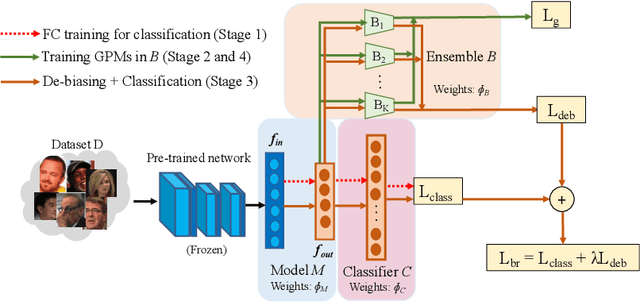
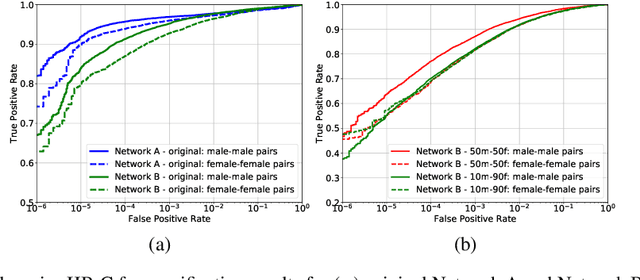
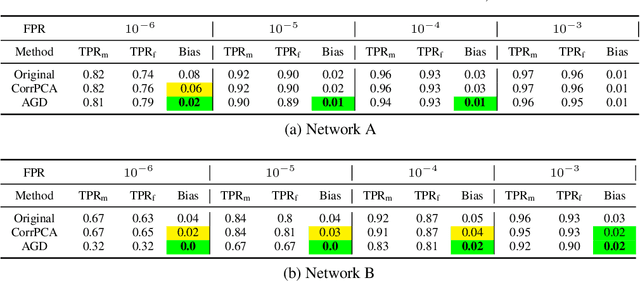
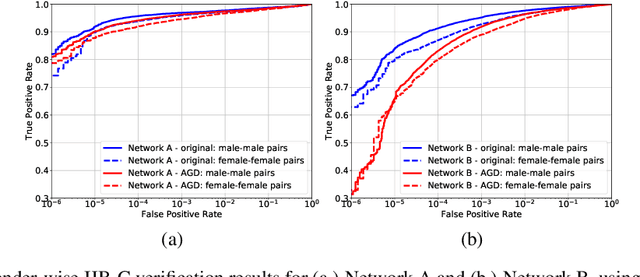
State-of-the-art face recognition networks implicitly encode gender information while being trained for identity classification. Gender is often viewed as an important face attribute to recognize humans. But, the expression of gender information in deep facial features appears to contribute to gender bias in face recognition, i.e. we find a significant difference in the recognition accuracy of DCNNs on male and female faces. We hypothesize that reducing implicitly encoded gender information will help reduce this gender bias. Therefore, we present a novel approach called `Adversarial Gender De-biasing (AGD)' to reduce the strength of gender information in face recognition features. We accomplish this by introducing a bias reducing classification loss $L_{br}$. We show that AGD significantly reduces bias, while achieving reasonable recognition performance. The results of our approach are presented on two state-of-the-art networks.
Single Unit Status in Deep Convolutional Neural Network Codes for Face Identification: Sparseness Redefined
Mar 01, 2020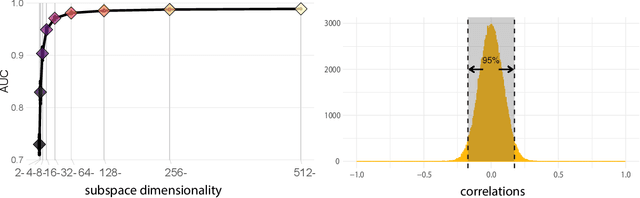
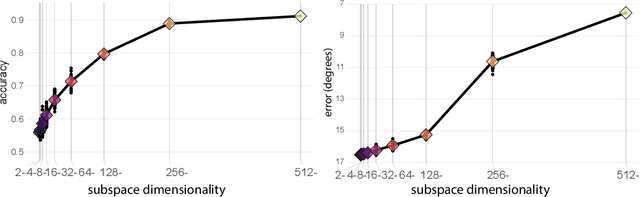
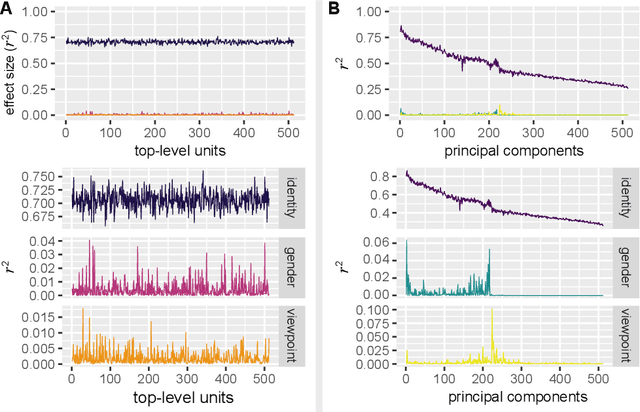
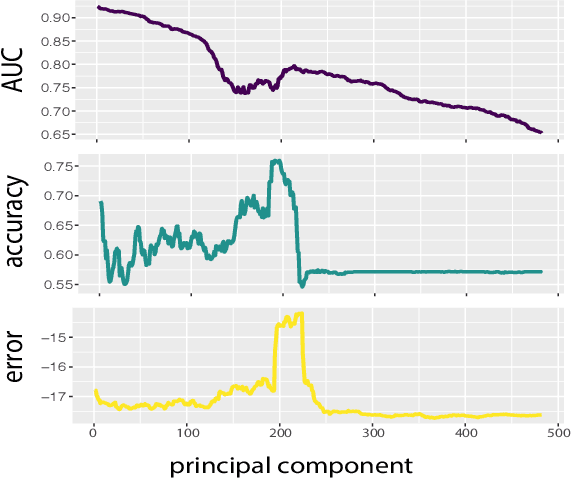
Deep convolutional neural networks (DCNNs) trained for face identification develop representations that generalize over variable images, while retaining subject (e.g., gender) and image (e.g., viewpoint) information. Identity, gender, and viewpoint codes were studied at the "neural unit" and ensemble levels of a face-identification network. At the unit level, identification, gender classification, and viewpoint estimation were measured by deleting units to create variably-sized, randomly-sampled subspaces at the top network layer. Identification of 3,531 identities remained high (area under the ROC approximately 1.0) as dimensionality decreased from 512 units to 16 (0.95), 4 (0.80), and 2 (0.72) units. Individual identities separated statistically on every top-layer unit. Cross-unit responses were minimally correlated, indicating that units code non-redundant identity cues. This "distributed" code requires only a sparse, random sample of units to identify faces accurately. Gender classification declined gradually and viewpoint estimation fell steeply as dimensionality decreased. Individual units were weakly predictive of gender and viewpoint, but ensembles proved effective predictors. Therefore, distributed and sparse codes co-exist in the network units to represent different face attributes. At the ensemble level, principal component analysis of face representations showed that identity, gender, and viewpoint information separated into high-dimensional subspaces, ordered by explained variance. Identity, gender, and viewpoint information contributed to all individual unit responses, undercutting a neural tuning analogy for face attributes. Interpretation of neural-like codes from DCNNs, and by analogy, high-level visual codes, cannot be inferred from single unit responses. Instead, "meaning" is encoded by directions in the high-dimensional space.
How are attributes expressed in face DCNNs?
Oct 12, 2019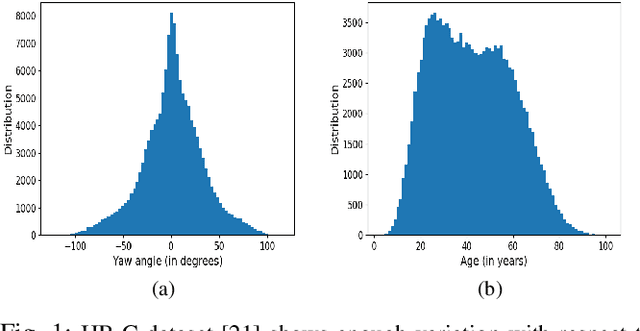
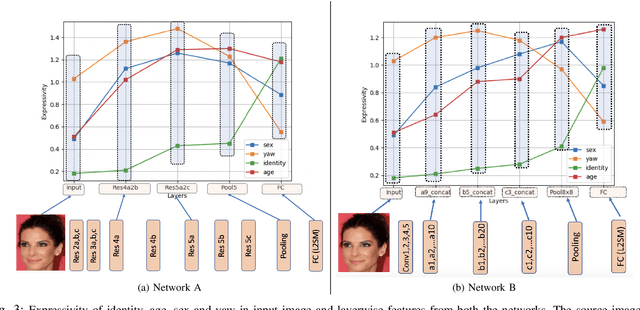
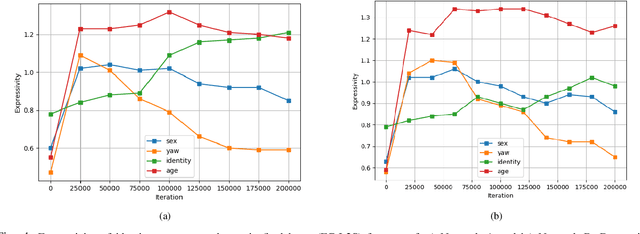
As deep networks become increasingly accurate at recognizing faces, it is vital to understand how these networks process faces. While these networks are solely trained to recognize identities, they also contain face related information such as sex, age, and pose of the face. The networks are not trained to learn these attributes. We introduce expressivity as a measure of how much a feature vector informs us about an attribute, where a feature vector can be from internal or final layers of a network. Expressivity is computed by a second neural network whose inputs are features and attributes. The output of the second neural network approximates the mutual information between feature vectors and an attribute. We investigate the expressivity for two different deep convolutional neural network (DCNN) architectures: a Resnet-101 and an Inception Resnet v2. In the final fully connected layer of the networks, we found the order of expressivity for facial attributes to be Age > Sex > Yaw. Additionally, we studied the changes in the encoding of facial attributes over training iterations. We found that as training progresses, expressivities of yaw, sex, and age decrease. Our technique can be a tool for investigating the sources of bias in a network and a step towards explaining the network's identity decisions.
On measuring the iconicity of a face
Mar 04, 2019

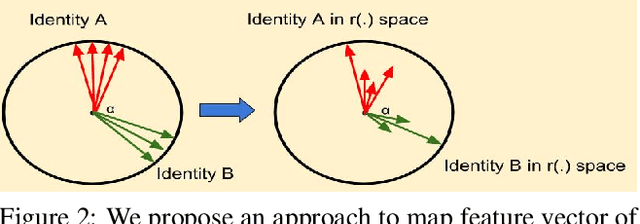
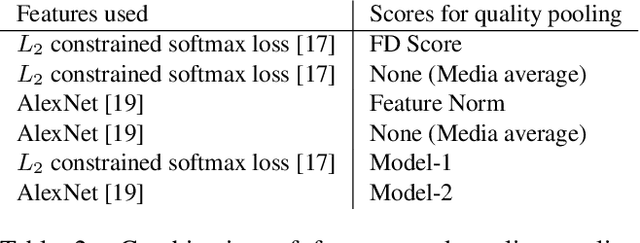
For a given identity in a face dataset, there are certain iconic images which are more representative of the subject than others. In this paper, we explore the problem of computing the iconicity of a face. The premise of the proposed approach is as follows: For an identity containing a mixture of iconic and non iconic images, if a given face cannot be successfully matched with any other face of the same identity, then the iconicity of the face image is low. Using this information, we train a Siamese Multi-Layer Perceptron network, such that each of its twins predict iconicity scores of the image feature pair, fed in as input. We observe the variation of the obtained scores with respect to covariates such as blur, yaw, pitch, roll and occlusion to demonstrate that they effectively predict the quality of the image and compare it with other existing metrics. Furthermore, we use these scores to weight features for template-based face verification and compare it with media averaging of features.
Learning without Memorizing
Nov 20, 2018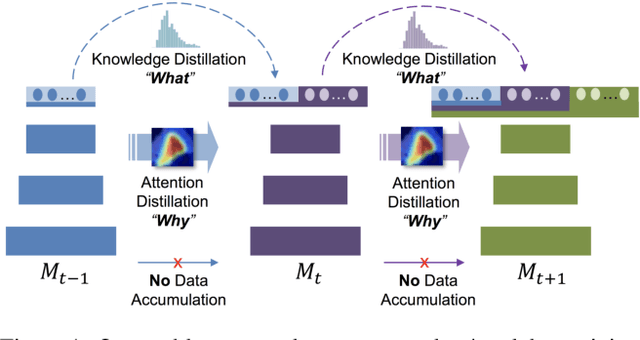


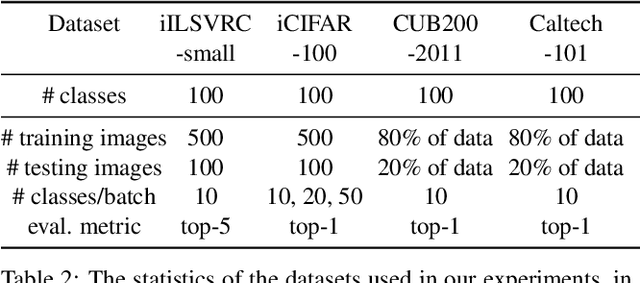
Incremental learning (IL) is an important task aimed to increase the capability of a trained model, in terms of the number of classes recognizable by the model. The key problem in this task is the requirement of storing data (e.g. images) associated with existing classes, while training the classifier to learn new classes. However, this is impractical as it increases the memory requirement at every incremental step, which makes it impossible to implement IL algorithms on the edge devices with limited memory. Hence, we propose a novel approach, called "Learning without Memorizing (LwM)", to preserve the information with respect to existing (base) classes, without storing any of their data, while making the classifier progressively learn the new classes. In LwM, we present an information preserving penalty: Attention Distillation Loss, and demonstrate that penalizing the changes in classifiers' attention maps helps to retain information of the base classes, as new classes are added. We show that adding Attention Distillation Loss to the distillation loss which is an existing information preserving loss consistently outperforms the state-of-the-art performance in the iILSVRC-small and iCIFAR-100 datasets in terms of the overall accuracy of base and incrementally learned classes.