 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin identification over viewpoint change: A deep convolutional neural network surpasses humans
Jul 12, 2022
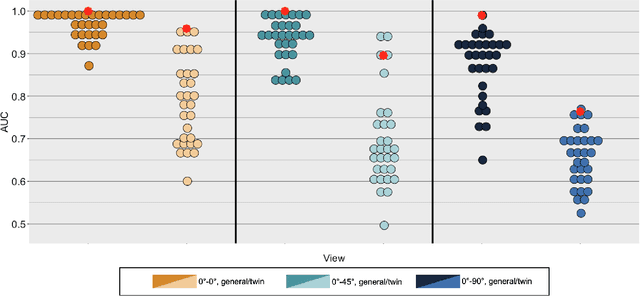
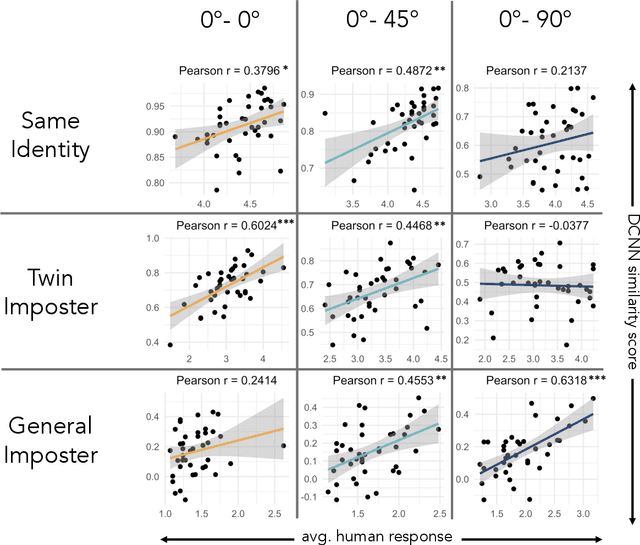
Deep convolutional neural networks (DCNNs) have achieved human-level accuracy in face identification (Phillips et al., 2018), though it is unclear how accurately they discriminate highly-similar faces. Here, humans and a DCNN performed a challenging face-identity matching task that included identical twins. Participants (N=87) viewed pairs of face images of three types: same-identity, general imposter pairs (different identities from similar demographic groups), and twin imposter pairs (identical twin siblings). The task was to determine whether the pairs showed the same person or different people. Identity comparisons were tested in three viewpoint-disparity conditions: frontal to frontal, frontal to 45-degree profile, and frontal to 90-degree profile. Accuracy for discriminating matched-identity pairs from twin-imposters and general imposters was assessed in each viewpoint-disparity condition. Humans were more accurate for general-imposter pairs than twin-imposter pairs, and accuracy declined with increased viewpoint disparity between the images in a pair. A DCNN trained for face identification (Ranjan et al., 2018) was tested on the same image pairs presented to humans. Machine performance mirrored the pattern of human accuracy, but with performance at or above all humans in all but one condition. Human and machine similarity scores were compared across all image-pair types. This item-level analysis showed that human and machine similarity ratings correlated significantly in six of nine image-pair types [range r=0.38 to r=0.63], suggesting general accord between the perception of face similarity by humans and the DCNN. These findings also contribute to our understanding of DCNN performance for discriminating high-resemblance faces, demonstrate that the DCNN performs at a level at or above humans, and suggest a degree of parity between the features used by humans and the DCNN.
The Influence of the Other-Race Effect on Susceptibility to Face Morphing Attacks
Apr 26, 2022
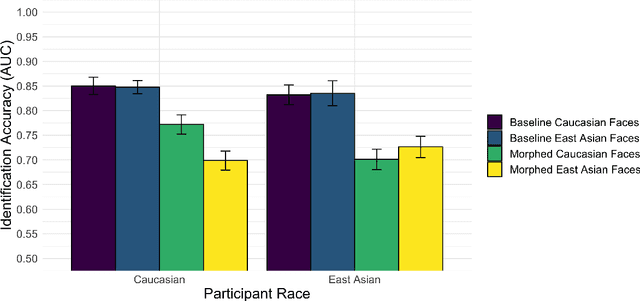
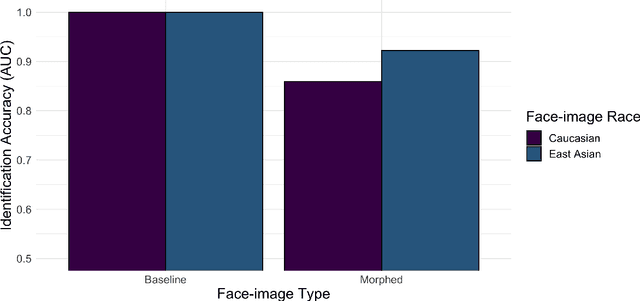
Facial morphs created between two identities resemble both of the faces used to create the morph. Consequently, humans and machines are prone to mistake morphs made from two identities for either of the faces used to create the morph. This vulnerability has been exploited in "morph attacks" in security scenarios. Here, we asked whether the "other-race effect" (ORE) -- the human advantage for identifying own- vs. other-race faces -- exacerbates morph attack susceptibility for humans. We also asked whether face-identification performance in a deep convolutional neural network (DCNN) is affected by the race of morphed faces. Caucasian (CA) and East-Asian (EA) participants performed a face-identity matching task on pairs of CA and EA face images in two conditions. In the morph condition, different-identity pairs consisted of an image of identity "A" and a 50/50 morph between images of identity "A" and "B". In the baseline condition, morphs of different identities never appeared. As expected, morphs were identified mistakenly more often than original face images. Moreover, CA participants showed an advantage for CA faces in comparison to EA faces (a partial ORE). Of primary interest, morph identification was substantially worse for cross-race faces than for own-race faces. Similar to humans, the DCNN performed more accurately for original face images than for morphed image pairs. Notably, the deep network proved substantially more accurate than humans in both cases. The results point to the possibility that DCNNs might be useful for improving face identification accuracy when morphed faces are presented. They also indicate the significance of the ORE in morph attack susceptibility in applied settings.
Single Unit Status in Deep Convolutional Neural Network Codes for Face Identification: Sparseness Redefined
Mar 01, 2020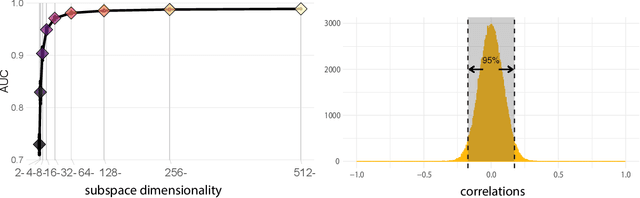
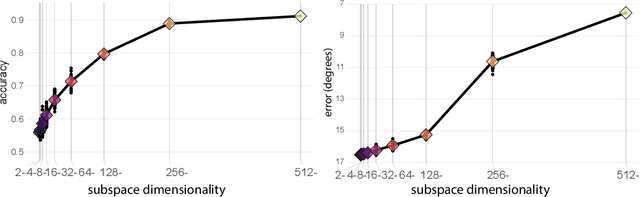
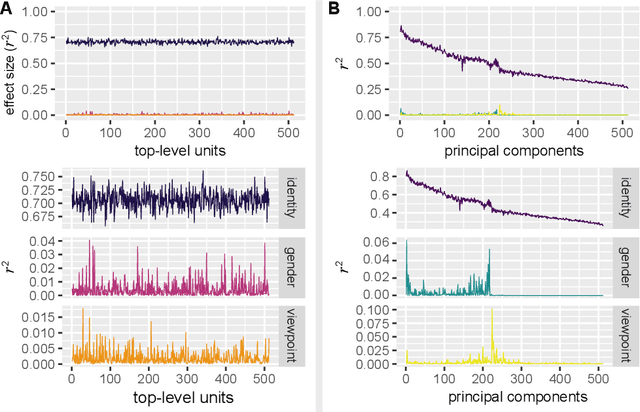
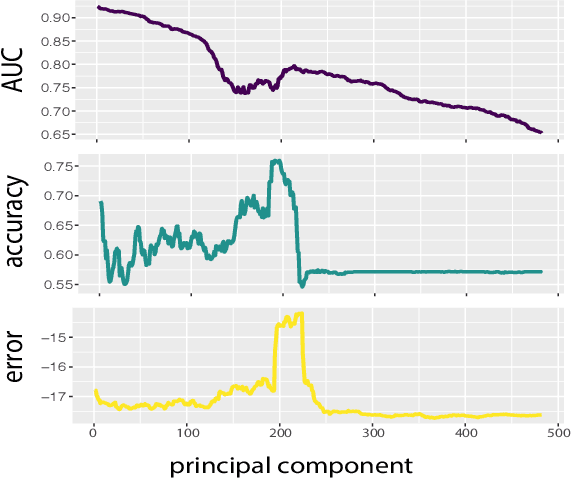
Deep convolutional neural networks (DCNNs) trained for face identification develop representations that generalize over variable images, while retaining subject (e.g., gender) and image (e.g., viewpoint) information. Identity, gender, and viewpoint codes were studied at the "neural unit" and ensemble levels of a face-identification network. At the unit level, identification, gender classification, and viewpoint estimation were measured by deleting units to create variably-sized, randomly-sampled subspaces at the top network layer. Identification of 3,531 identities remained high (area under the ROC approximately 1.0) as dimensionality decreased from 512 units to 16 (0.95), 4 (0.80), and 2 (0.72) units. Individual identities separated statistically on every top-layer unit. Cross-unit responses were minimally correlated, indicating that units code non-redundant identity cues. This "distributed" code requires only a sparse, random sample of units to identify faces accurately. Gender classification declined gradually and viewpoint estimation fell steeply as dimensionality decreased. Individual units were weakly predictive of gender and viewpoint, but ensembles proved effective predictors. Therefore, distributed and sparse codes co-exist in the network units to represent different face attributes. At the ensemble level, principal component analysis of face representations showed that identity, gender, and viewpoint information separated into high-dimensional subspaces, ordered by explained variance. Identity, gender, and viewpoint information contributed to all individual unit responses, undercutting a neural tuning analogy for face attributes. Interpretation of neural-like codes from DCNNs, and by analogy, high-level visual codes, cannot be inferred from single unit responses. Instead, "meaning" is encoded by directions in the high-dimensional space.
Deep Convolutional Neural Networks in the Face of Caricature: Identity and Image Revealed
Dec 28, 2018

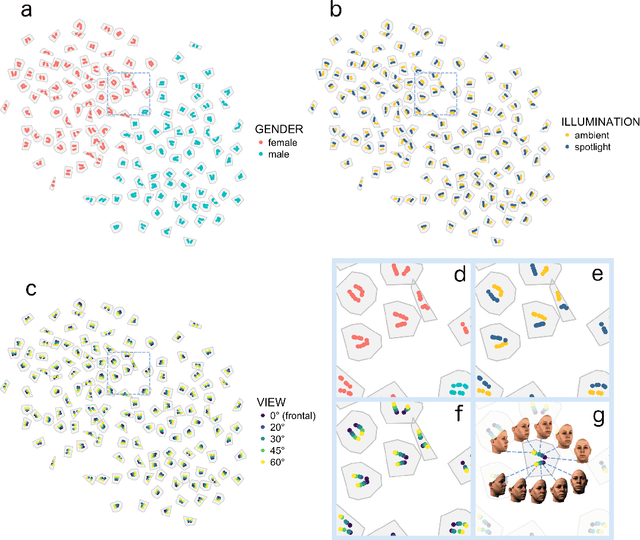
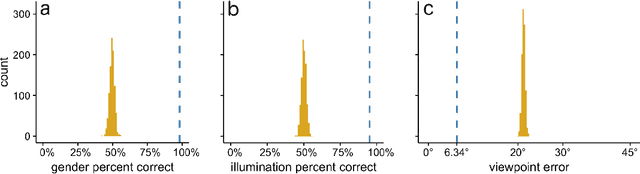
Real-world face recognition requires an ability to perceive the unique features of an individual face across multiple, variable images. The primate visual system solves the problem of image invariance using cascades of neurons that convert images of faces into categorical representations of facial identity. Deep convolutional neural networks (DCNNs) also create generalizable face representations, but with cascades of simulated neurons. DCNN representations can be examined in a multidimensional "face space", with identities and image parameters quantified via their projections onto the axes that define the space. We examined the organization of viewpoint, illumination, gender, and identity in this space. We show that the network creates a highly organized, hierarchically nested, face similarity structure in which information about face identity and imaging characteristics coexist. Natural image variation is accommodated in this hierarchy, with face identity nested under gender, illumination nested under identity, and viewpoint nested under illumination. To examine identity, we caricatured faces and found that network identification accuracy increased with caricature level, and--mimicking human perception--a caricatured distortion of a face "resembled" its veridical counterpart. Caricatures improved performance by moving the identity away from other identities in the face space and minimizing the effects of illumination and viewpoint. Deep networks produce face representations that solve long-standing computational problems in generalized face recognition. They also provide a unitary theoretical framework for reconciling decades of behavioral and neural results that emphasized either the image or the object/face in representations, without understanding how a neural code could seamlessly accommodate both.
Deep Convolutional Neural Network Features and the Original Image
Nov 06, 2016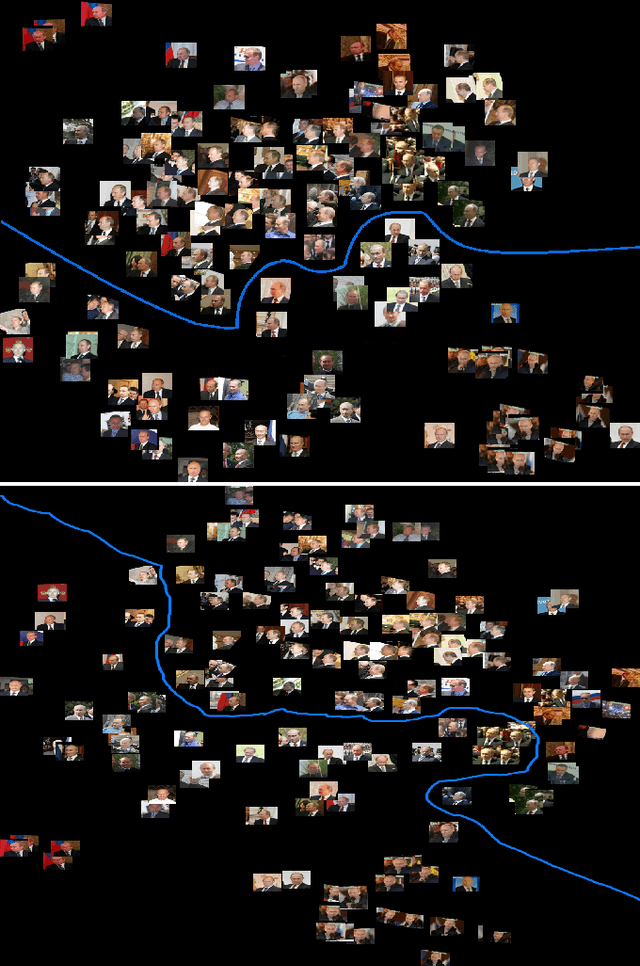
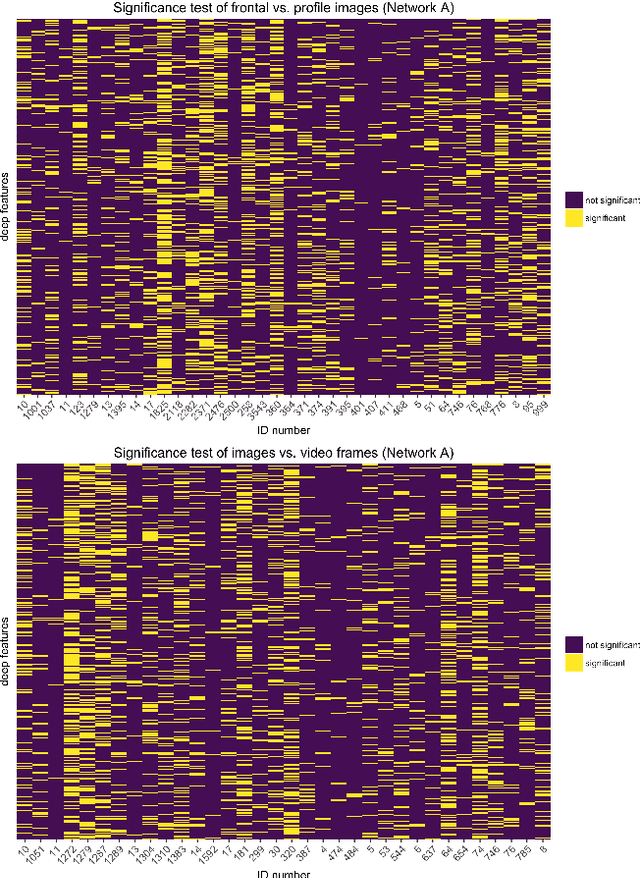


Face recognition algorithms based on deep convolutional neural networks (DCNNs) have made progress on the task of recognizing faces in unconstrained viewing conditions. These networks operate with compact feature-based face representations derived from learning a very large number of face images. While the learned features produced by DCNNs can be highly robust to changes in viewpoint, illumination, and appearance, little is known about the nature of the face code that emerges at the top level of such networks. We analyzed the DCNN features produced by two face recognition algorithms. In the first set of experiments we used the top-level features from the DCNNs as input into linear classifiers aimed at predicting metadata about the images. The results show that the DCNN features contain surprisingly accurate information about the yaw and pitch of a face, and about whether the face came from a still image or a video frame. In the second set of experiments, we measured the extent to which individual DCNN features operated in a view-dependent or view-invariant manner. We found that view-dependent coding was a characteristic of the identities rather than the DCNN features - with some identities coded consistently in a view-dependent way and others in a view-independent way. In our third analysis, we visualized the DCNN feature space for over 24,000 images of 500 identities. Images in the center of the space were uniformly of low quality (e.g., extreme views, face occlusion, low resolution). Image quality increased monotonically as a function of distance from the origin. This result suggests that image quality information is available in the DCNN features, such that consistently average feature values reflect coding failures that reliably indicate poor or unusable images. Combined, the results offer insight into the coding mechanisms that support robust representation of faces in DCNNs.