 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreater than the sum of its parts: The role of minority and majority status in collaborative problem-solving communication
Mar 07, 2024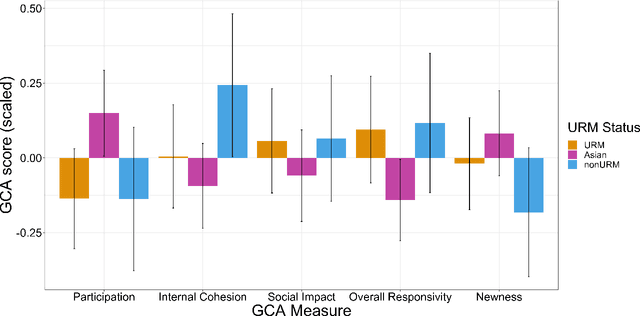
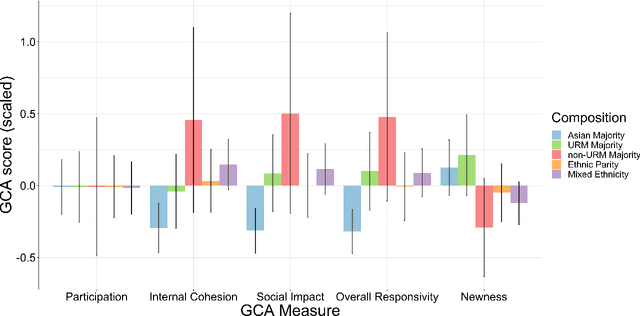
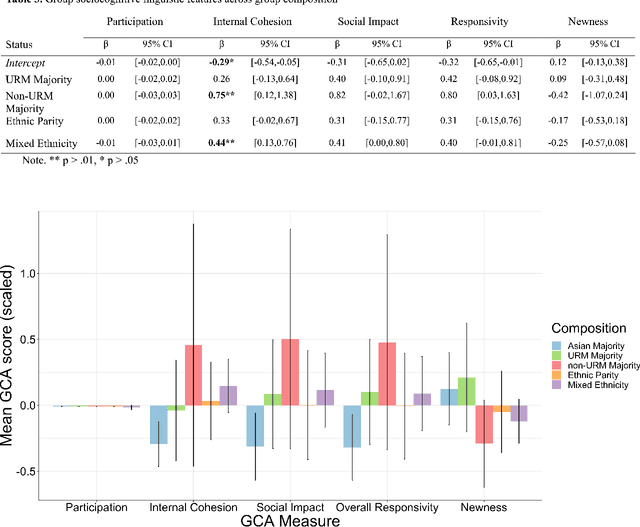
Collaborative problem-solving (CPS) is a vital skill used both in the workplace and in educational environments. CPS is useful in tackling increasingly complex global, economic, and political issues and is considered a central 21st century skill. The increasingly connected global community presents a fruitful opportunity for creative and collaborative problem-solving interactions and solutions that involve diverse perspectives. Unfortunately, women and underrepresented minorities (URMs) often face obstacles during collaborative interactions that hinder their key participation in these problem-solving conversations. Here, we explored the communication patterns of minority and non-minority individuals working together in a CPS task. Group Communication Analysis (GCA), a temporally-sensitive computational linguistic tool, was used to examine how URM status impacts individuals' sociocognitive linguistic patterns. Results show differences across racial/ethnic groups in key sociocognitive features that indicate fruitful collaborative interactions. We also investigated how the groups' racial/ethnic composition impacts both individual and group communication patterns. In general, individuals in more demographically diverse groups displayed more productive communication behaviors than individuals who were in majority-dominated groups. We discuss the implications of individual and group diversity on communication patterns that emerge during CPS and how these patterns can impact collaborative outcomes.
Twin identification over viewpoint change: A deep convolutional neural network surpasses humans
Jul 12, 2022
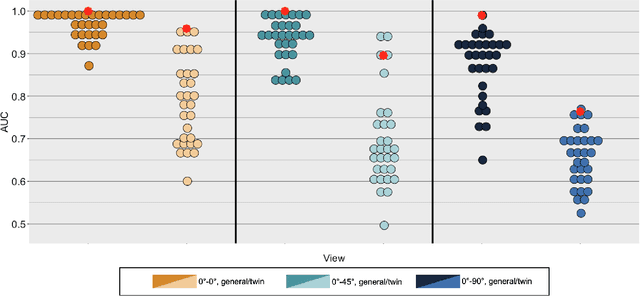
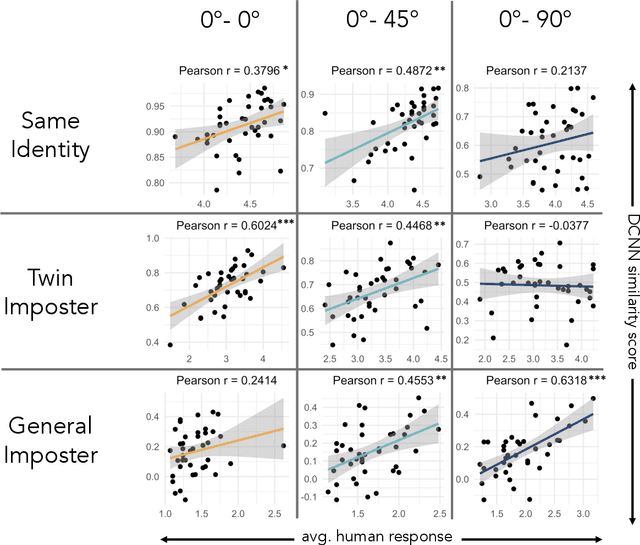
Deep convolutional neural networks (DCNNs) have achieved human-level accuracy in face identification (Phillips et al., 2018), though it is unclear how accurately they discriminate highly-similar faces. Here, humans and a DCNN performed a challenging face-identity matching task that included identical twins. Participants (N=87) viewed pairs of face images of three types: same-identity, general imposter pairs (different identities from similar demographic groups), and twin imposter pairs (identical twin siblings). The task was to determine whether the pairs showed the same person or different people. Identity comparisons were tested in three viewpoint-disparity conditions: frontal to frontal, frontal to 45-degree profile, and frontal to 90-degree profile. Accuracy for discriminating matched-identity pairs from twin-imposters and general imposters was assessed in each viewpoint-disparity condition. Humans were more accurate for general-imposter pairs than twin-imposter pairs, and accuracy declined with increased viewpoint disparity between the images in a pair. A DCNN trained for face identification (Ranjan et al., 2018) was tested on the same image pairs presented to humans. Machine performance mirrored the pattern of human accuracy, but with performance at or above all humans in all but one condition. Human and machine similarity scores were compared across all image-pair types. This item-level analysis showed that human and machine similarity ratings correlated significantly in six of nine image-pair types [range r=0.38 to r=0.63], suggesting general accord between the perception of face similarity by humans and the DCNN. These findings also contribute to our understanding of DCNN performance for discriminating high-resemblance faces, demonstrate that the DCNN performs at a level at or above humans, and suggest a degree of parity between the features used by humans and the DCNN.
Face Identification Proficiency Test Designed Using Item Response Theory
Jul 01, 2021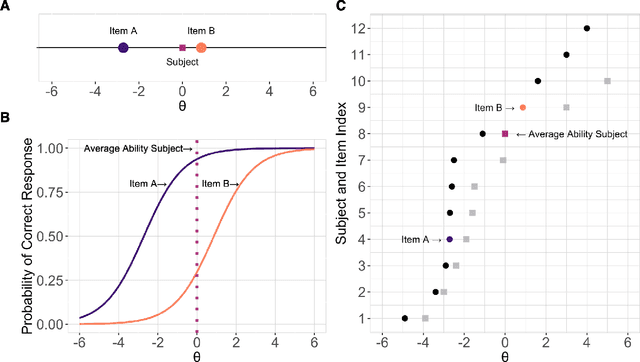
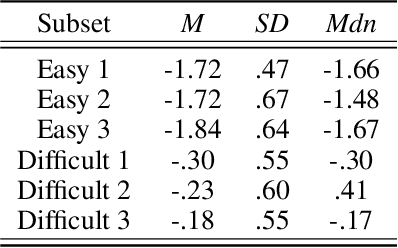
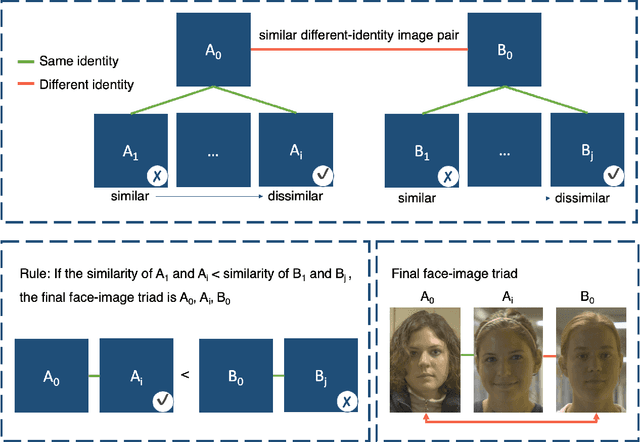
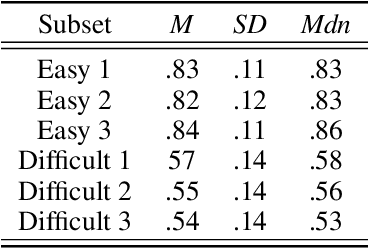
Measures of face identification proficiency are essential to ensure accurate and consistent performance by professional forensic face examiners and others who perform face identification tasks in applied scenarios. Current proficiency tests rely on static sets of stimulus items, and so, cannot be administered validly to the same individual multiple times. To create a proficiency test, a large number of items of "known" difficulty must be assembled. Multiple tests of equal difficulty can be constructed then using subsets of items. Here, we introduce a proficiency test, the Triad Identity Matching (TIM) test, based on stimulus difficulty measures based on Item Response Theory (IRT). Participants view face-image "triads" (N=225) (two images of one identity and one image of a different identity) and select the different identity. In Experiment 1, university students (N=197) showed wide-ranging accuracy on the TIM test. Furthermore, IRT modeling demonstrated that the TIM test produces items of various difficulty levels. In Experiment 2, IRT-based item difficulty measures were used to partition the TIM test into three equally "easy" and three equally "difficult" subsets. Simulation results indicated that the full set, as well as curated subsets, of the TIM items yielded reliable estimates of subject ability. In summary, the TIM test can provide a starting point for developing a framework that is flexible, calibrated, and adaptive to measure proficiency across various ability levels (e.g., professionals or populations with face processing deficits)
Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
Dec 16, 2019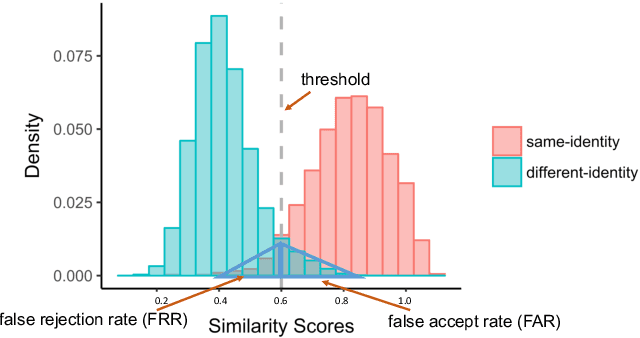
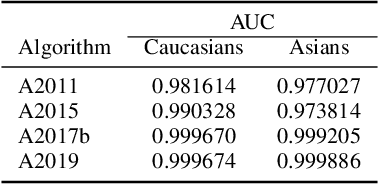

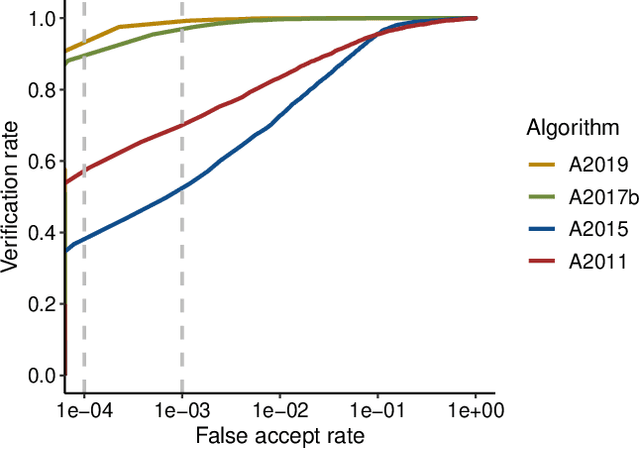
Previous generations of face recognition algorithms differ in accuracy for faces of different races (race bias). Whether deep convolutional neural networks (DCNNs) are race biased is less studied. To measure race bias in algorithms, it is important to consider the underlying factors. Here, we present the possible underlying factors and methodological considerations for assessing race bias in algorithms. We investigate data-driven and scenario modeling factors. Data-driven factors include image quality, image population statistics, and algorithm architecture. Scenario modeling considers the role of the "user" of the algorithm (e.g., threshold decisions and demographic constraints). To illustrate how these issues apply, we present data from four face recognition algorithms (one pre- DCNN, three DCNN) for Asian and Caucasian faces. First, for all four algorithms, the degree of bias varied depending on the identification decision threshold. Second, for all algorithms, to achieve equal false accept rates (FARs), Asian faces required higher identification thresholds than Caucasian faces. Third, dataset difficulty affected both overall recognition accuracy and race bias. Fourth, demographic constraints on the formulation of the distributions used in the test, impacted estimates of algorithm accuracy. We conclude with a recommended checklist for measuring race bias in face recognition algorithms.