 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Covariate-Adjusted Homogeneity Test with Application to Facial Recognition Accuracy Assessment
Jul 17, 2023Ordinal scores occur commonly in medical imaging studies and in black-box forensic studies \citep{Phillips:2018}. To assess the accuracy of raters in the studies, one needs to estimate the receiver operating characteristic (ROC) curve while accounting for covariates of raters. In this paper, we propose a covariate-adjusted homogeneity test to determine differences in accuracy among multiple rater groups. We derived the theoretical results of the proposed test and conducted extensive simulation studies to evaluate the finite sample performance of the proposed test. Our proposed test is applied to a face recognition study to identify statistically significant differences among five participant groups.
Ontological Learning from Weak Labels
Mar 04, 2022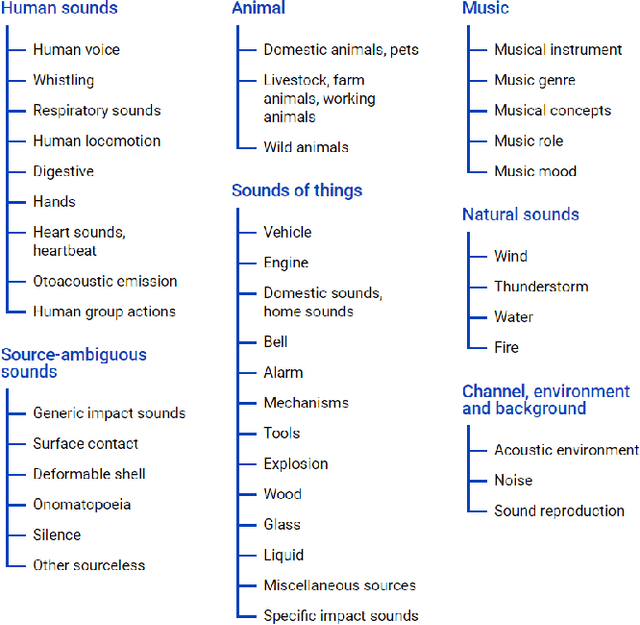

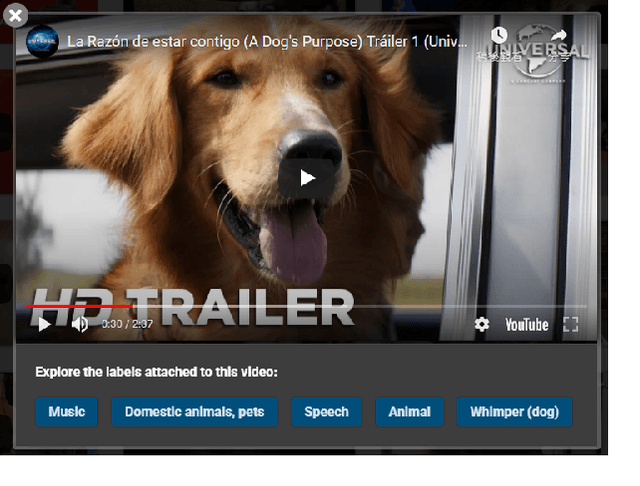

Ontologies encompass a formal representation of knowledge through the definition of concepts or properties of a domain, and the relationships between those concepts. In this work, we seek to investigate whether using this ontological information will improve learning from weakly labeled data, which are easier to collect since it requires only the presence or absence of an event to be known. We use the AudioSet ontology and dataset, which contains audio clips weakly labeled with the ontology concepts and the ontology providing the "Is A" relations between the concepts. We first re-implemented the model proposed by soundevent_ontology with modification to fit the multi-label scenario and then expand on that idea by using a Graph Convolutional Network (GCN) to model the ontology information to learn the concepts. We find that the baseline Siamese does not perform better by incorporating ontology information in the weak and multi-label scenario, but that the GCN does capture the ontology knowledge better for weak, multi-labeled data. In our experiments, we also investigate how different modules can tolerate noises introduced from weak labels and better incorporate ontology information. Our best Siamese-GCN model achieves mAP=0.45 and AUC=0.87 for lower-level concepts and mAP=0.72 and AUC=0.86 for higher-level concepts, which is an improvement over the baseline Siamese but about the same as our models that do not use ontology information.
Face Identification Proficiency Test Designed Using Item Response Theory
Jul 01, 2021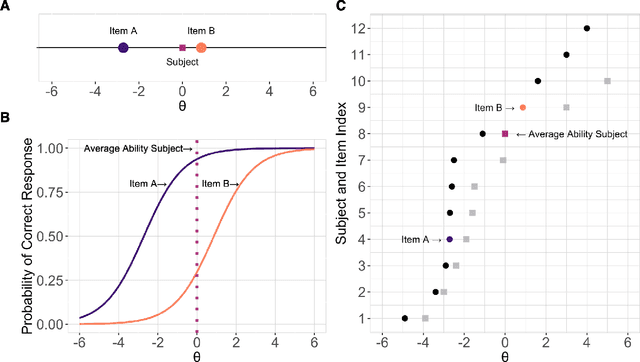
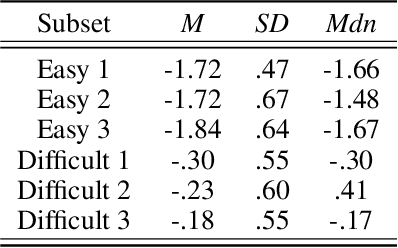
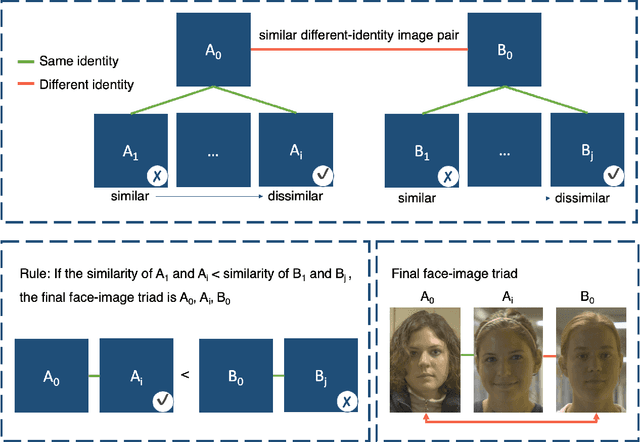
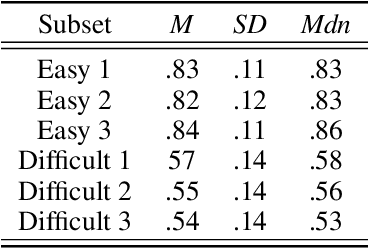
Measures of face identification proficiency are essential to ensure accurate and consistent performance by professional forensic face examiners and others who perform face identification tasks in applied scenarios. Current proficiency tests rely on static sets of stimulus items, and so, cannot be administered validly to the same individual multiple times. To create a proficiency test, a large number of items of "known" difficulty must be assembled. Multiple tests of equal difficulty can be constructed then using subsets of items. Here, we introduce a proficiency test, the Triad Identity Matching (TIM) test, based on stimulus difficulty measures based on Item Response Theory (IRT). Participants view face-image "triads" (N=225) (two images of one identity and one image of a different identity) and select the different identity. In Experiment 1, university students (N=197) showed wide-ranging accuracy on the TIM test. Furthermore, IRT modeling demonstrated that the TIM test produces items of various difficulty levels. In Experiment 2, IRT-based item difficulty measures were used to partition the TIM test into three equally "easy" and three equally "difficult" subsets. Simulation results indicated that the full set, as well as curated subsets, of the TIM items yielded reliable estimates of subject ability. In summary, the TIM test can provide a starting point for developing a framework that is flexible, calibrated, and adaptive to measure proficiency across various ability levels (e.g., professionals or populations with face processing deficits)