 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Covariate-Adjusted Homogeneity Test with Application to Facial Recognition Accuracy Assessment
Jul 17, 2023Ordinal scores occur commonly in medical imaging studies and in black-box forensic studies \citep{Phillips:2018}. To assess the accuracy of raters in the studies, one needs to estimate the receiver operating characteristic (ROC) curve while accounting for covariates of raters. In this paper, we propose a covariate-adjusted homogeneity test to determine differences in accuracy among multiple rater groups. We derived the theoretical results of the proposed test and conducted extensive simulation studies to evaluate the finite sample performance of the proposed test. Our proposed test is applied to a face recognition study to identify statistically significant differences among five participant groups.
Human-Machine Comparison for Cross-Race Face Verification: Race Bias at the Upper Limits of Performance?
May 31, 2023Face recognition algorithms perform more accurately than humans in some cases, though humans and machines both show race-based accuracy differences. As algorithms continue to improve, it is important to continually assess their race bias relative to humans. We constructed a challenging test of 'cross-race' face verification and used it to compare humans and two state-of-the-art face recognition systems. Pairs of same- and different-identity faces of White and Black individuals were selected to be difficult for humans and an open-source implementation of the ArcFace face recognition algorithm from 2019 (5). Human participants (54 Black; 51 White) judged whether face pairs showed the same identity or different identities on a 7-point Likert-type scale. Two top-performing face recognition systems from the Face Recognition Vendor Test-ongoing performed the same test (7). By design, the test proved challenging for humans as a group, who performed above chance, but far less than perfect. Both state-of-the-art face recognition systems scored perfectly (no errors), consequently with equal accuracy for both races. We conclude that state-of-the-art systems for identity verification between two frontal face images of Black and White individuals can surpass the general population. Whether this result generalizes to challenging in-the-wild images is a pressing concern for deploying face recognition systems in unconstrained environments.
Distill and De-bias: Mitigating Bias in Face Recognition using Knowledge Distillation
Dec 17, 2021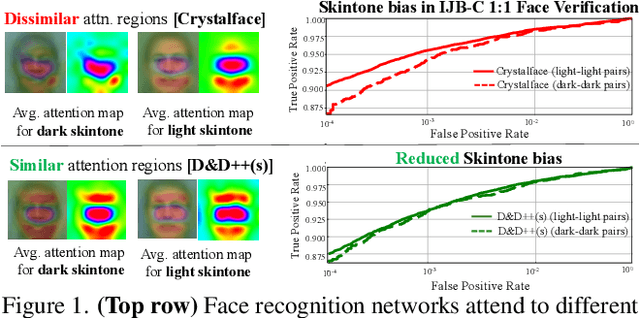
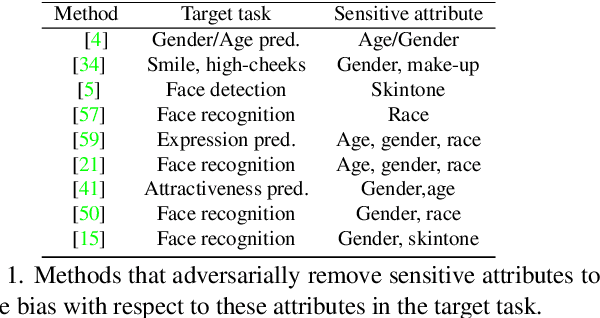
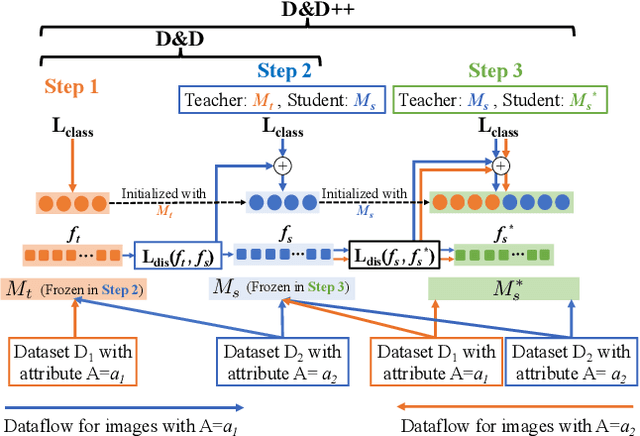
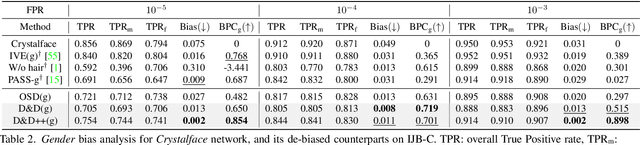
Face recognition networks generally demonstrate bias with respect to sensitive attributes like gender, skintone etc. For gender and skintone, we observe that the regions of the face that a network attends to vary by the category of an attribute. This might contribute to bias. Building on this intuition, we propose a novel distillation-based approach called Distill and De-bias (D&D) to enforce a network to attend to similar face regions, irrespective of the attribute category. In D&D, we train a teacher network on images from one category of an attribute; e.g. light skintone. Then distilling information from the teacher, we train a student network on images of the remaining category; e.g., dark skintone. A feature-level distillation loss constrains the student network to generate teacher-like representations. This allows the student network to attend to similar face regions for all attribute categories and enables it to reduce bias. We also propose a second distillation step on top of D&D, called D&D++. For the D&D++ network, we distill the `un-biasedness' of the D&D network into a new student network, the D&D++ network. We train the new network on all attribute categories; e.g., both light and dark skintones. This helps us train a network that is less biased for an attribute, while obtaining higher face verification performance than D&D. We show that D&D++ outperforms existing baselines in reducing gender and skintone bias on the IJB-C dataset, while obtaining higher face verification performance than existing adversarial de-biasing methods. We evaluate the effectiveness of our proposed methods on two state-of-the-art face recognition networks: Crystalface and ArcFace.
Face Identification Proficiency Test Designed Using Item Response Theory
Jul 01, 2021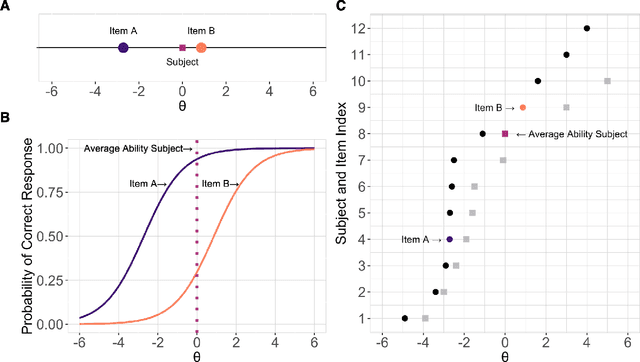
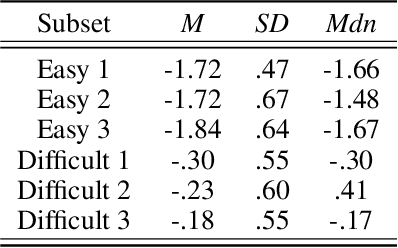
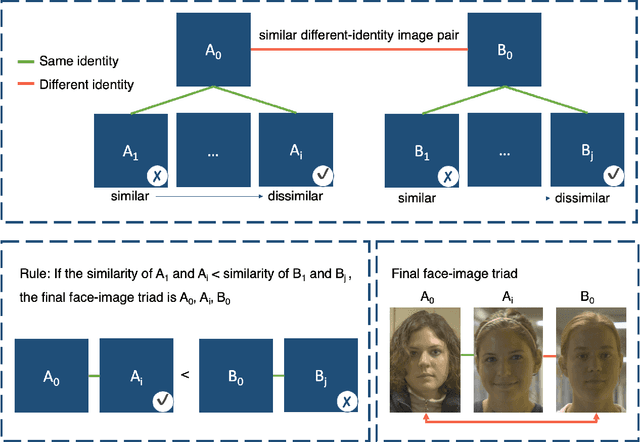
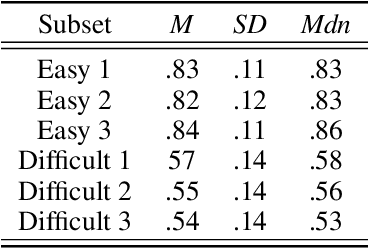
Measures of face identification proficiency are essential to ensure accurate and consistent performance by professional forensic face examiners and others who perform face identification tasks in applied scenarios. Current proficiency tests rely on static sets of stimulus items, and so, cannot be administered validly to the same individual multiple times. To create a proficiency test, a large number of items of "known" difficulty must be assembled. Multiple tests of equal difficulty can be constructed then using subsets of items. Here, we introduce a proficiency test, the Triad Identity Matching (TIM) test, based on stimulus difficulty measures based on Item Response Theory (IRT). Participants view face-image "triads" (N=225) (two images of one identity and one image of a different identity) and select the different identity. In Experiment 1, university students (N=197) showed wide-ranging accuracy on the TIM test. Furthermore, IRT modeling demonstrated that the TIM test produces items of various difficulty levels. In Experiment 2, IRT-based item difficulty measures were used to partition the TIM test into three equally "easy" and three equally "difficult" subsets. Simulation results indicated that the full set, as well as curated subsets, of the TIM items yielded reliable estimates of subject ability. In summary, the TIM test can provide a starting point for developing a framework that is flexible, calibrated, and adaptive to measure proficiency across various ability levels (e.g., professionals or populations with face processing deficits)
Four Principles of Explainable AI as Applied to Biometrics and Facial Forensic Algorithms
Feb 03, 2020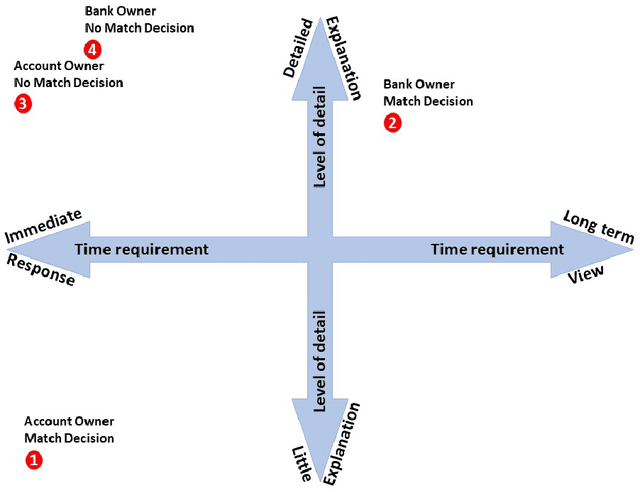
Traditionally, researchers in automatic face recognition and biometric technologies have focused on developing accurate algorithms. With this technology being integrated into operational systems, engineers and scientists are being asked, do these systems meet societal norms? The origin of this line of inquiry is `trust' of artificial intelligence (AI) systems. In this paper, we concentrate on adapting explainable AI to face recognition and biometrics, and we present four principles of explainable AI to face recognition and biometrics. The principles are illustrated by $\it{four}$ case studies, which show the challenges and issues in developing algorithms that can produce explanations.
Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
Dec 16, 2019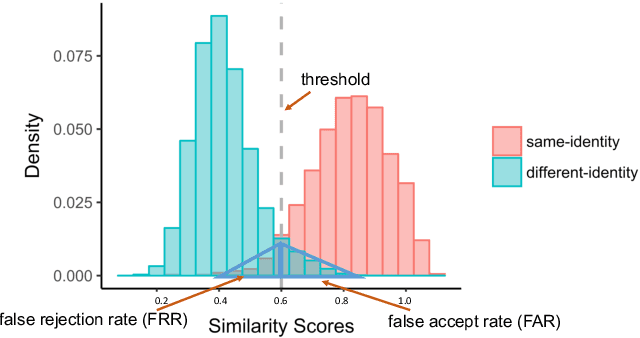
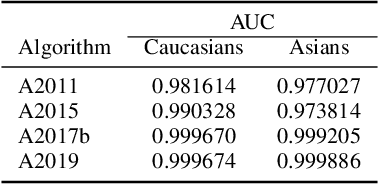

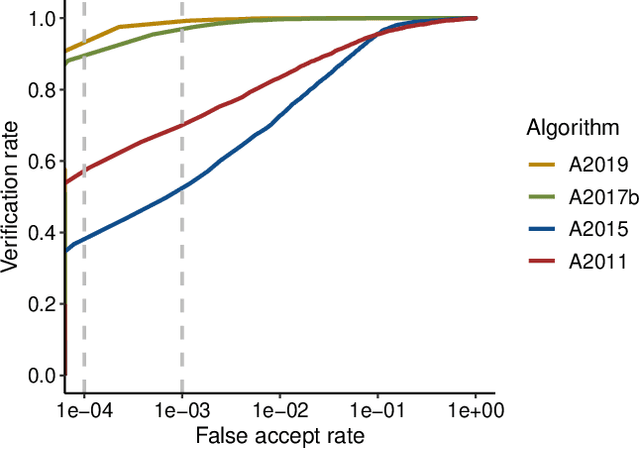
Previous generations of face recognition algorithms differ in accuracy for faces of different races (race bias). Whether deep convolutional neural networks (DCNNs) are race biased is less studied. To measure race bias in algorithms, it is important to consider the underlying factors. Here, we present the possible underlying factors and methodological considerations for assessing race bias in algorithms. We investigate data-driven and scenario modeling factors. Data-driven factors include image quality, image population statistics, and algorithm architecture. Scenario modeling considers the role of the "user" of the algorithm (e.g., threshold decisions and demographic constraints). To illustrate how these issues apply, we present data from four face recognition algorithms (one pre- DCNN, three DCNN) for Asian and Caucasian faces. First, for all four algorithms, the degree of bias varied depending on the identification decision threshold. Second, for all algorithms, to achieve equal false accept rates (FARs), Asian faces required higher identification thresholds than Caucasian faces. Third, dataset difficulty affected both overall recognition accuracy and race bias. Fourth, demographic constraints on the formulation of the distributions used in the test, impacted estimates of algorithm accuracy. We conclude with a recommended checklist for measuring race bias in face recognition algorithms.
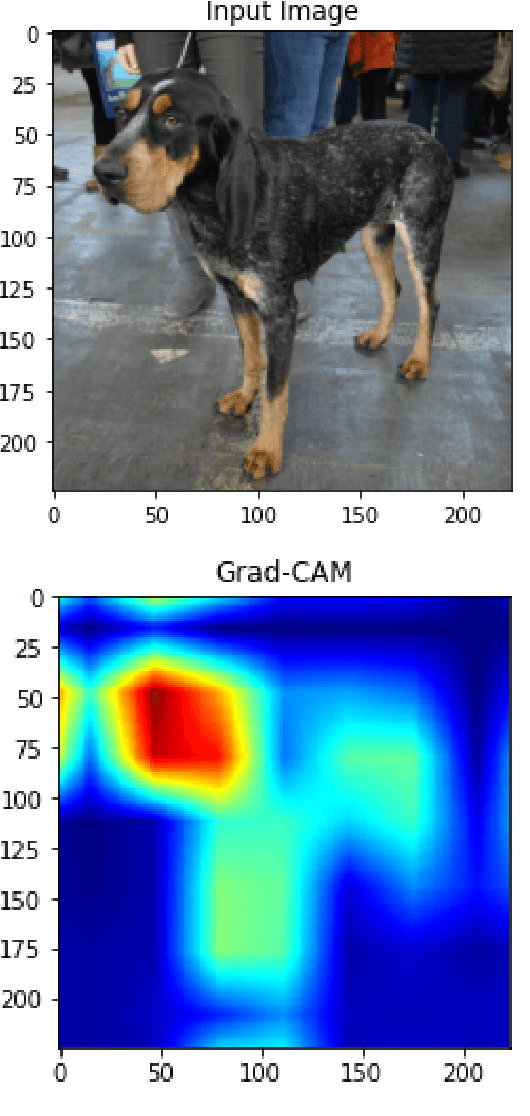
How are attributes expressed in face DCNNs?
Oct 12, 2019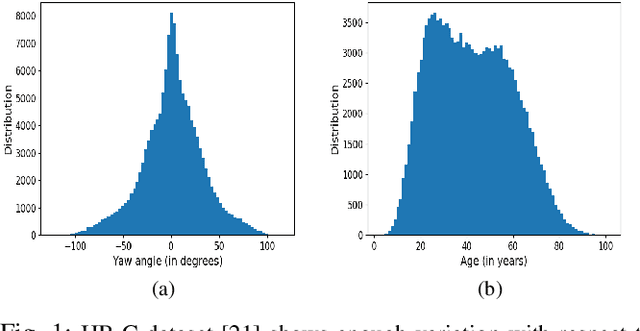
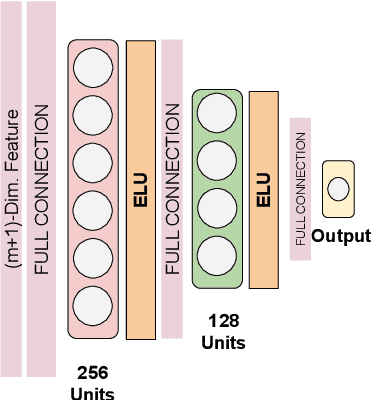
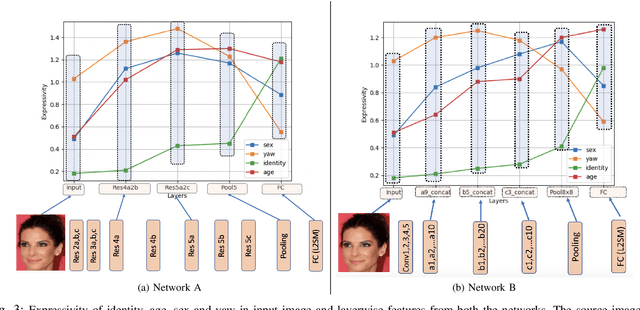
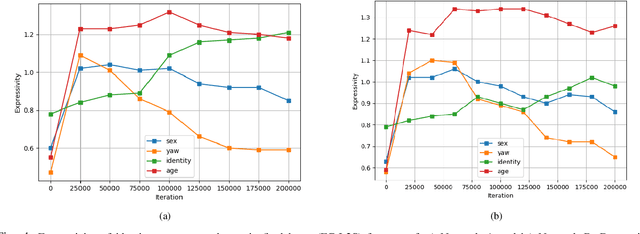
As deep networks become increasingly accurate at recognizing faces, it is vital to understand how these networks process faces. While these networks are solely trained to recognize identities, they also contain face related information such as sex, age, and pose of the face. The networks are not trained to learn these attributes. We introduce expressivity as a measure of how much a feature vector informs us about an attribute, where a feature vector can be from internal or final layers of a network. Expressivity is computed by a second neural network whose inputs are features and attributes. The output of the second neural network approximates the mutual information between feature vectors and an attribute. We investigate the expressivity for two different deep convolutional neural network (DCNN) architectures: a Resnet-101 and an Inception Resnet v2. In the final fully connected layer of the networks, we found the order of expressivity for facial attributes to be Age > Sex > Yaw. Additionally, we studied the changes in the encoding of facial attributes over training iterations. We found that as training progresses, expressivities of yaw, sex, and age decrease. Our technique can be a tool for investigating the sources of bias in a network and a step towards explaining the network's identity decisions.