 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Risk Invariance: Domain Generalization under Invariant Feature Shift
Jul 25, 2024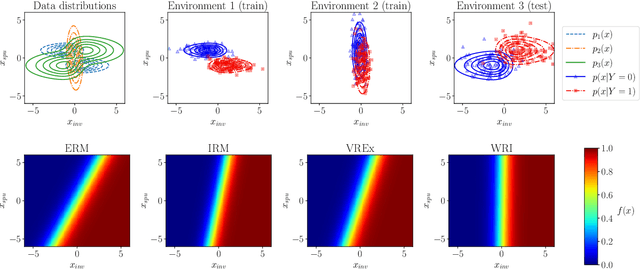
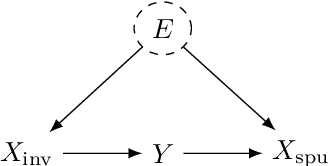

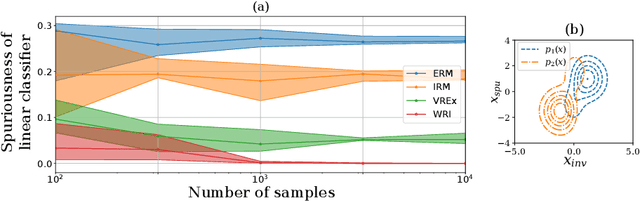
Learning models whose predictions are invariant under multiple environments is a promising approach for out-of-distribution generalization. Such models are trained to extract features $X_{\text{inv}}$ where the conditional distribution $Y \mid X_{\text{inv}}$ of the label given the extracted features does not change across environments. Invariant models are also supposed to generalize to shifts in the marginal distribution $p(X_{\text{inv}})$ of the extracted features $X_{\text{inv}}$, a type of shift we call an $\textit{invariant covariate shift}$. However, we show that proposed methods for learning invariant models underperform under invariant covariate shift, either failing to learn invariant models$\unicode{x2014}$even for data generated from simple and well-studied linear-Gaussian models$\unicode{x2014}$or having poor finite-sample performance. To alleviate these problems, we propose $\textit{weighted risk invariance}$ (WRI). Our framework is based on imposing invariance of the loss across environments subject to appropriate reweightings of the training examples. We show that WRI provably learns invariant models, i.e. discards spurious correlations, in linear-Gaussian settings. We propose a practical algorithm to implement WRI by learning the density $p(X_{\text{inv}})$ and the model parameters simultaneously, and we demonstrate empirically that WRI outperforms previous invariant learning methods under invariant covariate shift.
A Brief Survey on Person Recognition at a Distance
Dec 17, 2022



Person recognition at a distance entails recognizing the identity of an individual appearing in images or videos collected by long-range imaging systems such as drones or surveillance cameras. Despite recent advances in deep convolutional neural networks (DCNNs), this remains challenging. Images or videos collected by long-range cameras often suffer from atmospheric turbulence, blur, low-resolution, unconstrained poses, and poor illumination. In this paper, we provide a brief survey of recent advances in person recognition at a distance. In particular, we review recent work in multi-spectral face verification, person re-identification, and gait-based analysis techniques. Furthermore, we discuss the merits and drawbacks of existing approaches and identify important, yet under explored challenges for deploying remote person recognition systems in-the-wild.
Where in the World is this Image? Transformer-based Geo-localization in the Wild
Apr 29, 2022
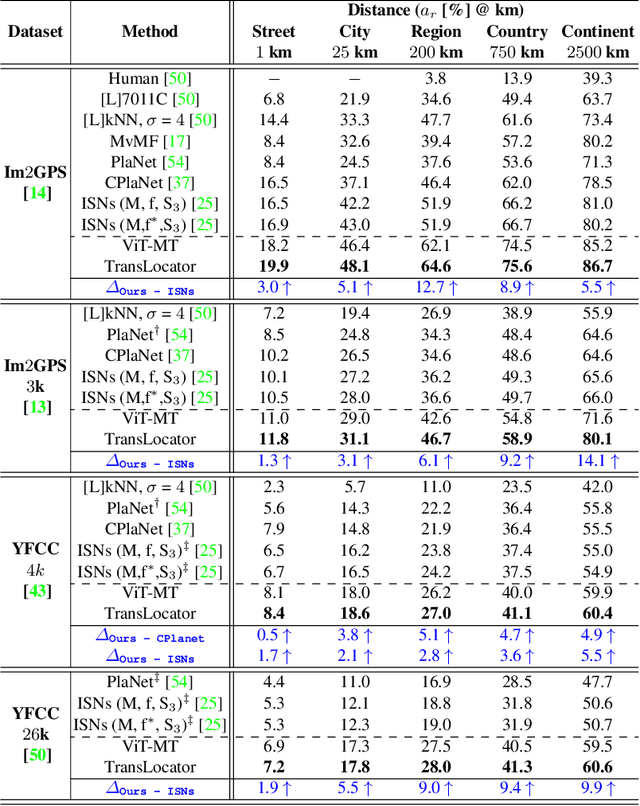
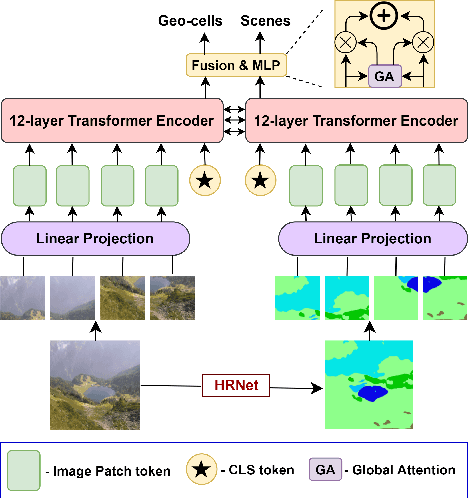
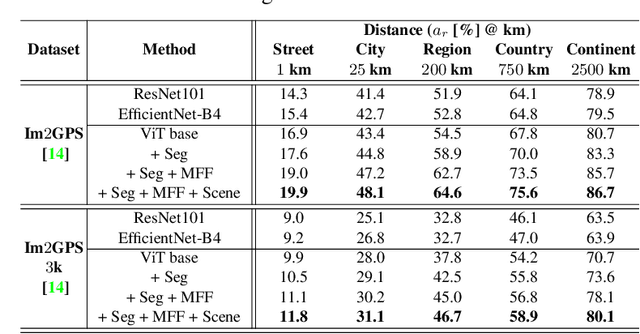
Predicting the geographic location (geo-localization) from a single ground-level RGB image taken anywhere in the world is a very challenging problem. The challenges include huge diversity of images due to different environmental scenarios, drastic variation in the appearance of the same location depending on the time of the day, weather, season, and more importantly, the prediction is made from a single image possibly having only a few geo-locating cues. For these reasons, most existing works are restricted to specific cities, imagery, or worldwide landmarks. In this work, we focus on developing an efficient solution to planet-scale single-image geo-localization. To this end, we propose TransLocator, a unified dual-branch transformer network that attends to tiny details over the entire image and produces robust feature representation under extreme appearance variations. TransLocator takes an RGB image and its semantic segmentation map as inputs, interacts between its two parallel branches after each transformer layer, and simultaneously performs geo-localization and scene recognition in a multi-task fashion. We evaluate TransLocator on four benchmark datasets - Im2GPS, Im2GPS3k, YFCC4k, YFCC26k and obtain 5.5%, 14.1%, 4.9%, 9.9% continent-level accuracy improvement over the state-of-the-art. TransLocator is also validated on real-world test images and found to be more effective than previous methods.
Distill and De-bias: Mitigating Bias in Face Recognition using Knowledge Distillation
Dec 17, 2021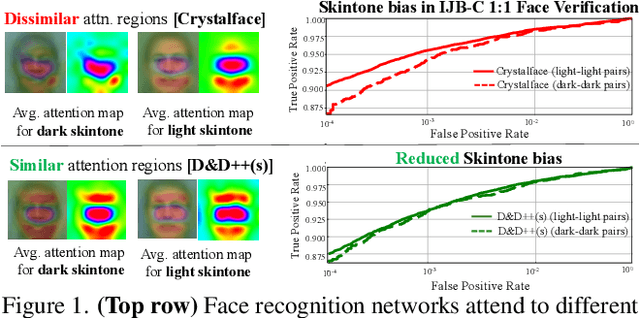
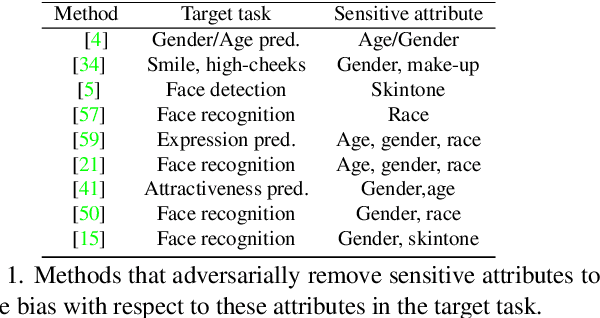
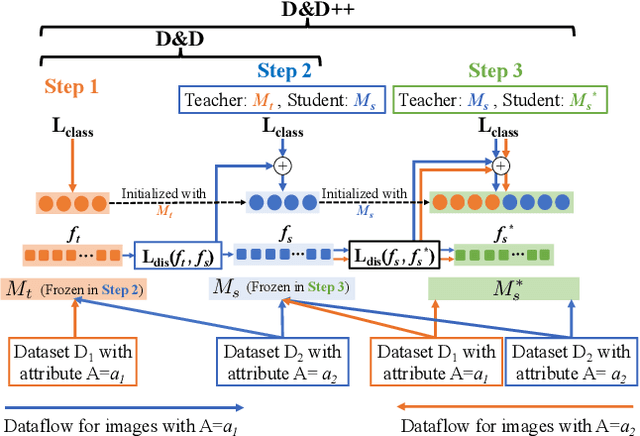
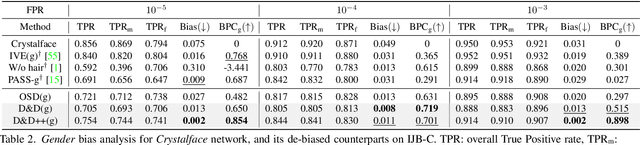
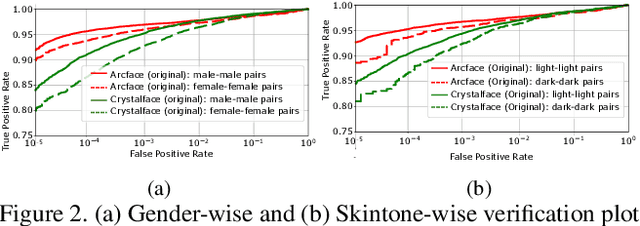
Face recognition networks generally demonstrate bias with respect to sensitive attributes like gender, skintone etc. For gender and skintone, we observe that the regions of the face that a network attends to vary by the category of an attribute. This might contribute to bias. Building on this intuition, we propose a novel distillation-based approach called Distill and De-bias (D&D) to enforce a network to attend to similar face regions, irrespective of the attribute category. In D&D, we train a teacher network on images from one category of an attribute; e.g. light skintone. Then distilling information from the teacher, we train a student network on images of the remaining category; e.g., dark skintone. A feature-level distillation loss constrains the student network to generate teacher-like representations. This allows the student network to attend to similar face regions for all attribute categories and enables it to reduce bias. We also propose a second distillation step on top of D&D, called D&D++. For the D&D++ network, we distill the `un-biasedness' of the D&D network into a new student network, the D&D++ network. We train the new network on all attribute categories; e.g., both light and dark skintones. This helps us train a network that is less biased for an attribute, while obtaining higher face verification performance than D&D. We show that D&D++ outperforms existing baselines in reducing gender and skintone bias on the IJB-C dataset, while obtaining higher face verification performance than existing adversarial de-biasing methods. We evaluate the effectiveness of our proposed methods on two state-of-the-art face recognition networks: Crystalface and ArcFace.
A Synthesis-Based Approach for Thermal-to-Visible Face Verification
Aug 21, 2021
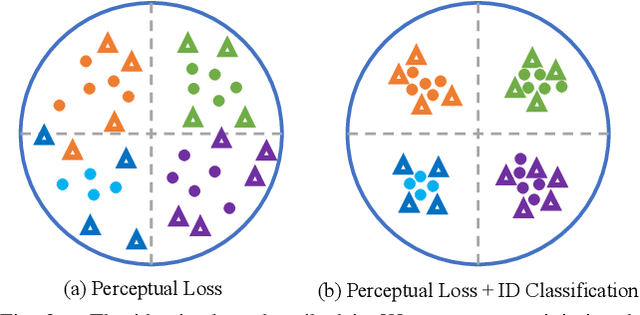
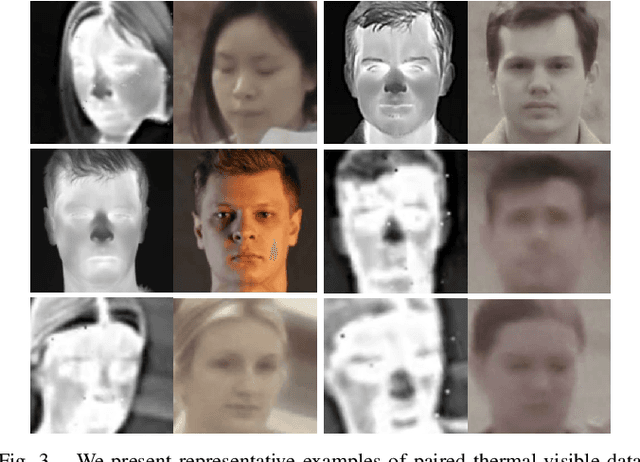
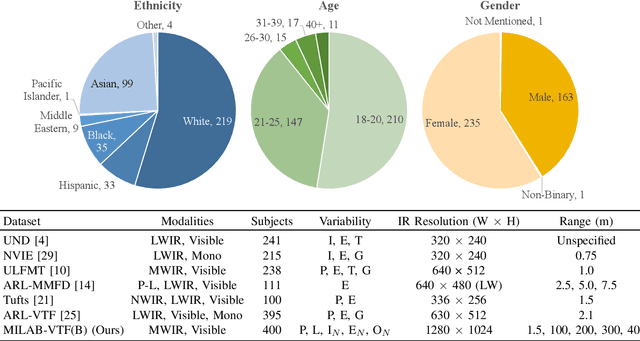
In recent years, visible-spectrum face verification systems have been shown to match expert forensic examiner recognition performance. However, such systems are ineffective in low-light and nighttime conditions. Thermal face imagery, which captures body heat emissions, effectively augments the visible spectrum, capturing discriminative facial features in scenes with limited illumination. Due to the increased cost and difficulty of obtaining diverse, paired thermal and visible spectrum datasets, algorithms and large-scale benchmarks for low-light recognition are limited. This paper presents an algorithm that achieves state-of-the-art performance on both the ARL-VTF and TUFTS multi-spectral face datasets. Importantly, we study the impact of face alignment, pixel-level correspondence, and identity classification with label smoothing for multi-spectral face synthesis and verification. We show that our proposed method is widely applicable, robust, and highly effective. In addition, we show that the proposed method significantly outperforms face frontalization methods on profile-to-frontal verification. Finally, we present MILAB-VTF(B), a challenging multi-spectral face dataset that is composed of paired thermal and visible videos. To the best of our knowledge, with face data from 400 subjects, this dataset represents the most extensive collection of publicly available indoor and long-range outdoor thermal-visible face imagery. Lastly, we show that our end-to-end thermal-to-visible face verification system provides strong performance on the MILAB-VTF(B) dataset.
PASS: Protected Attribute Suppression System for Mitigating Bias in Face Recognition
Aug 09, 2021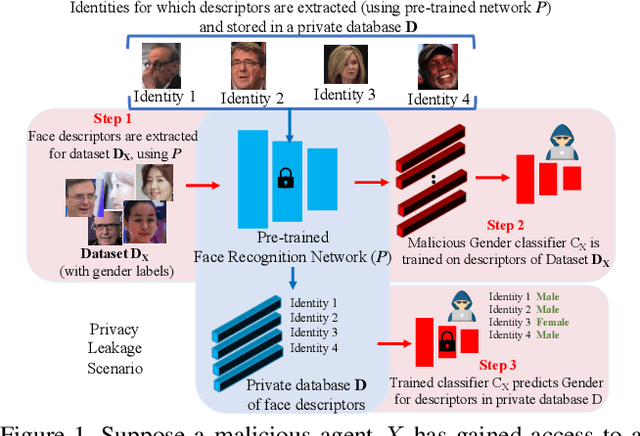
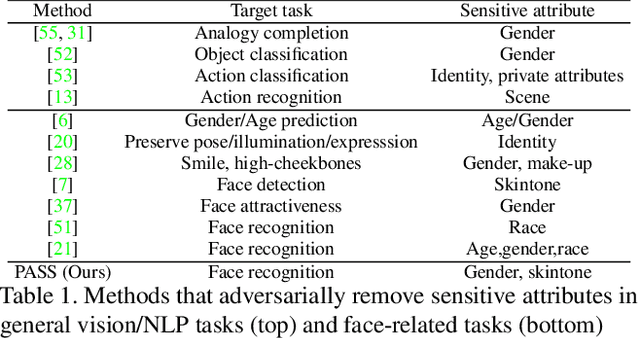

Face recognition networks encode information about sensitive attributes while being trained for identity classification. Such encoding has two major issues: (a) it makes the face representations susceptible to privacy leakage (b) it appears to contribute to bias in face recognition. However, existing bias mitigation approaches generally require end-to-end training and are unable to achieve high verification accuracy. Therefore, we present a descriptor-based adversarial de-biasing approach called `Protected Attribute Suppression System (PASS)'. PASS can be trained on top of descriptors obtained from any previously trained high-performing network to classify identities and simultaneously reduce encoding of sensitive attributes. This eliminates the need for end-to-end training. As a component of PASS, we present a novel discriminator training strategy that discourages a network from encoding protected attribute information. We show the efficacy of PASS to reduce gender and skintone information in descriptors from SOTA face recognition networks like Arcface. As a result, PASS descriptors outperform existing baselines in reducing gender and skintone bias on the IJB-C dataset, while maintaining a high verification accuracy.
An adversarial learning algorithm for mitigating gender bias in face recognition
Jun 14, 2020
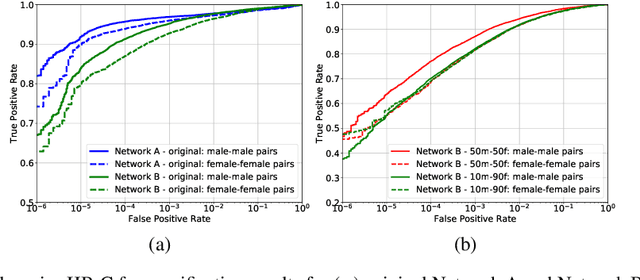
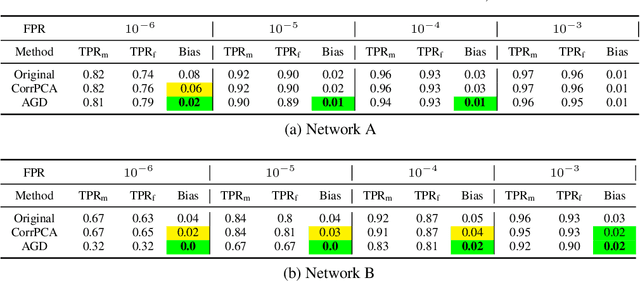
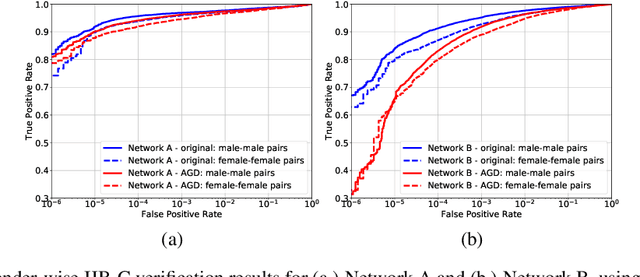
State-of-the-art face recognition networks implicitly encode gender information while being trained for identity classification. Gender is often viewed as an important face attribute to recognize humans. But, the expression of gender information in deep facial features appears to contribute to gender bias in face recognition, i.e. we find a significant difference in the recognition accuracy of DCNNs on male and female faces. We hypothesize that reducing implicitly encoded gender information will help reduce this gender bias. Therefore, we present a novel approach called `Adversarial Gender De-biasing (AGD)' to reduce the strength of gender information in face recognition features. We accomplish this by introducing a bias reducing classification loss $L_{br}$. We show that AGD significantly reduces bias, while achieving reasonable recognition performance. The results of our approach are presented on two state-of-the-art networks.
How are attributes expressed in face DCNNs?
Oct 12, 2019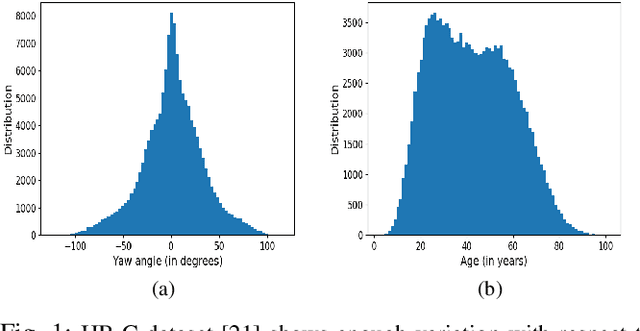
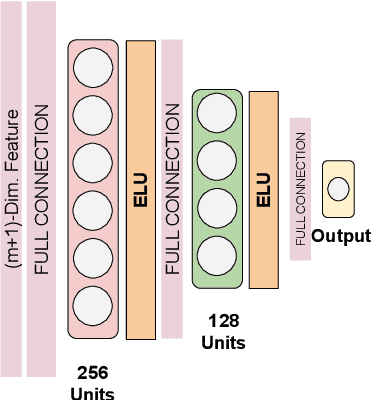
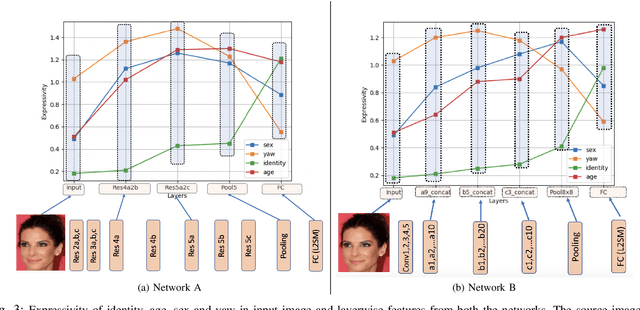
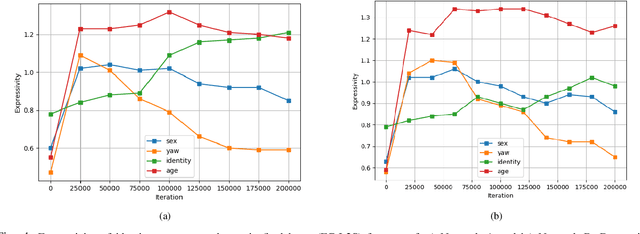
As deep networks become increasingly accurate at recognizing faces, it is vital to understand how these networks process faces. While these networks are solely trained to recognize identities, they also contain face related information such as sex, age, and pose of the face. The networks are not trained to learn these attributes. We introduce expressivity as a measure of how much a feature vector informs us about an attribute, where a feature vector can be from internal or final layers of a network. Expressivity is computed by a second neural network whose inputs are features and attributes. The output of the second neural network approximates the mutual information between feature vectors and an attribute. We investigate the expressivity for two different deep convolutional neural network (DCNN) architectures: a Resnet-101 and an Inception Resnet v2. In the final fully connected layer of the networks, we found the order of expressivity for facial attributes to be Age > Sex > Yaw. Additionally, we studied the changes in the encoding of facial attributes over training iterations. We found that as training progresses, expressivities of yaw, sex, and age decrease. Our technique can be a tool for investigating the sources of bias in a network and a step towards explaining the network's identity decisions.
A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos
Nov 23, 2018


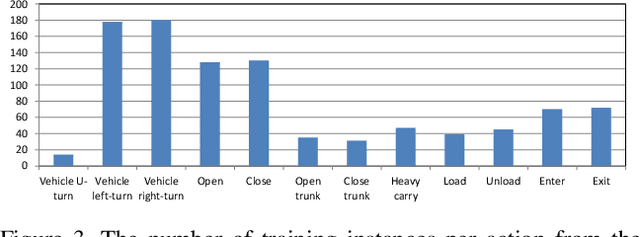
Existing approaches for spatio-temporal action detection in videos are limited by the spatial extent and temporal duration of the actions. In this paper, we present a modular system for spatio-temporal action detection in untrimmed security videos. We propose a two stage approach. The first stage generates dense spatio-temporal proposals using hierarchical clustering and temporal jittering techniques on frame-wise object detections. The second stage is a Temporal Refinement I3D (TRI-3D) network that performs action classification and temporal refinement on the generated proposals. The object detection-based proposal generation step helps in detecting actions occurring in a small spatial region of a video frame, while temporal jittering and refinement helps in detecting actions of variable lengths. Experimental results on the spatio-temporal action detection dataset - DIVA - show the effectiveness of our system. For comparison, the performance of our system is also evaluated on the THUMOS14 temporal action detection dataset.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018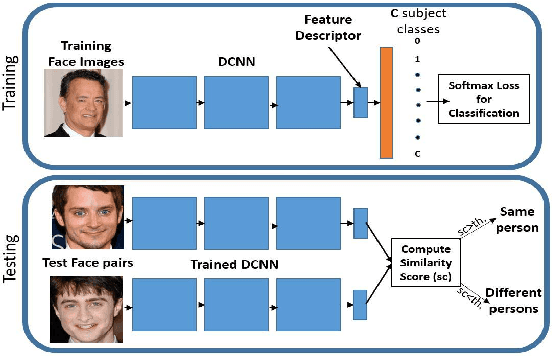
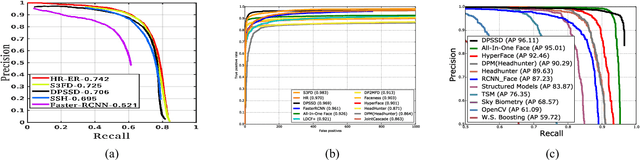
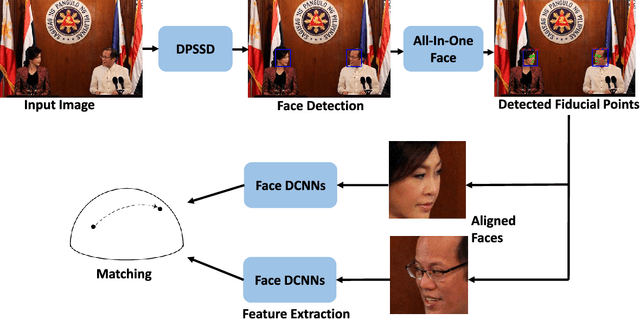
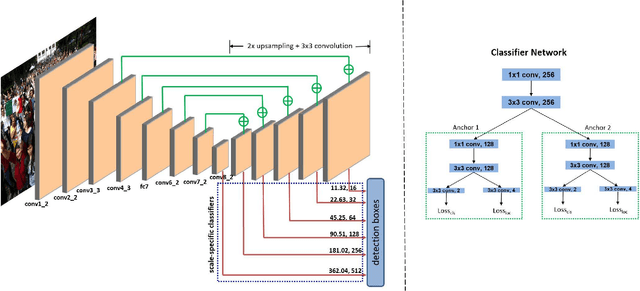
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).