 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
Dec 22, 2021
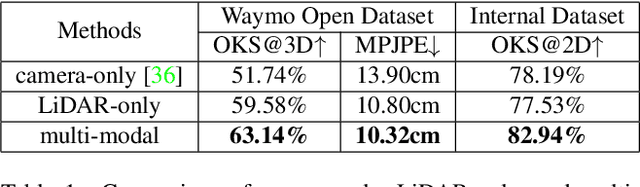
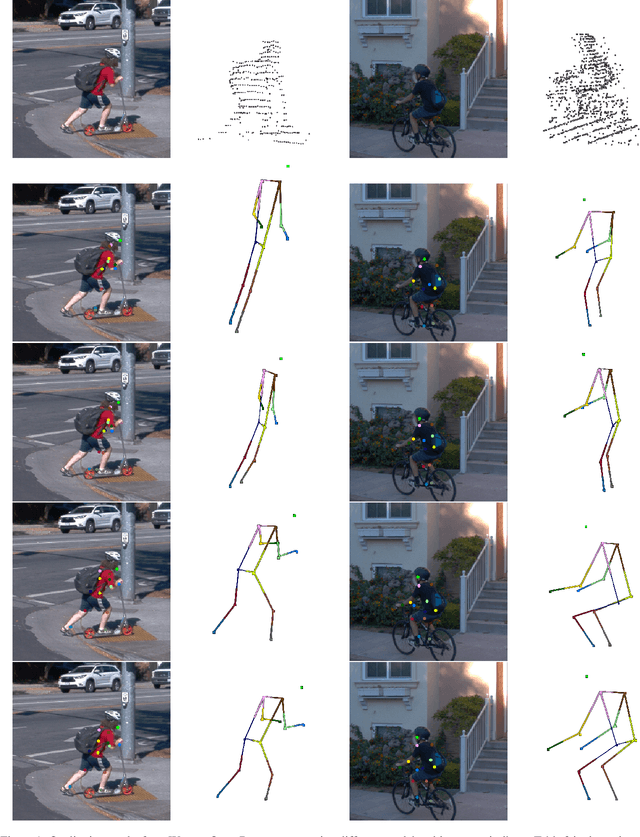
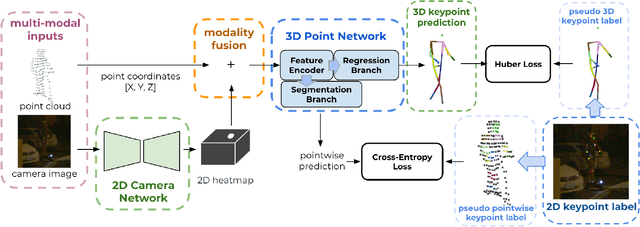
3D human pose estimation (HPE) in autonomous vehicles (AV) differs from other use cases in many factors, including the 3D resolution and range of data, absence of dense depth maps, failure modes for LiDAR, relative location between the camera and LiDAR, and a high bar for estimation accuracy. Data collected for other use cases (such as virtual reality, gaming, and animation) may therefore not be usable for AV applications. This necessitates the collection and annotation of a large amount of 3D data for HPE in AV, which is time-consuming and expensive. In this paper, we propose one of the first approaches to alleviate this problem in the AV setting. Specifically, we propose a multi-modal approach which uses 2D labels on RGB images as weak supervision to perform 3D HPE. The proposed multi-modal architecture incorporates LiDAR and camera inputs with an auxiliary segmentation branch. On the Waymo Open Dataset, our approach achieves a 22% relative improvement over camera-only 2D HPE baseline, and 6% improvement over LiDAR-only model. Finally, careful ablation studies and parts based analysis illustrate the advantages of each of our contributions.
Uncertainty Modeling of Contextual-Connection between Tracklets for Unconstrained Video-based Face Recognition
May 07, 2019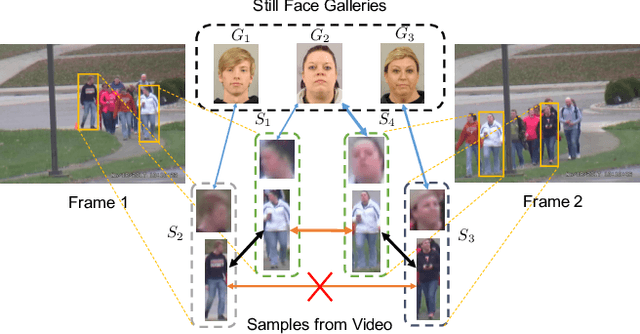
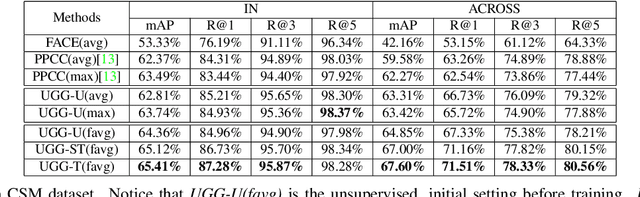
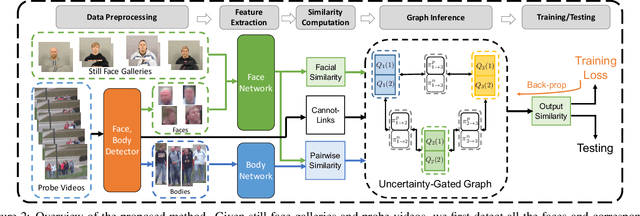

Unconstrained video-based face recognition is a challenging problem due to significant within-video variations caused by pose, occlusion and blur. To tackle this problem, an effective idea is to propagate the identity from high-quality faces to low-quality ones through contextual connections, which are constructed based on context such as body appearance. However, previous methods have often propagated erroneous information due to lack of uncertainty modeling of the noisy contextual connections. In this paper, we propose the Uncertainty-Gated Graph (UGG), which conducts graph-based identity propagation between tracklets, which are represented by nodes in a graph. UGG explicitly models the uncertainty of the contextual connections by adaptively updating the weights of the edge gates according to the identity distributions of the nodes during inference. UGG is a generic graphical model that can be applied at only inference time or with end-to-end training. We demonstrate the effectiveness of UGG with state-of-the-art results in the recently released challenging Cast Search in Movies and IARPA Janus Surveillance Video Benchmark dataset.
An Automatic System for Unconstrained Video-Based Face Recognition
Dec 10, 2018

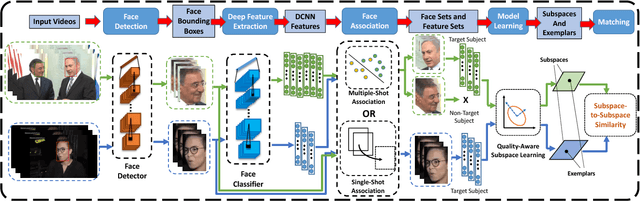

Although deep learning approaches have achieved performance surpassing humans for still image-based face recognition, unconstrained video-based face recognition is still a challenging task due to large volume of data to be processed and intra/inter-video variations on pose, illumination, occlusion, scene, blur, video quality, etc. In this work, we consider challenging scenarios for unconstrained video-based face recognition from multiple-shot videos and surveillance videos with low-quality frames. To handle these problems, we propose a robust and efficient system for unconstrained video-based face recognition, which is composed of face/fiducial detection, face association, and face recognition. First, we use multi-scale single-shot face detectors to efficiently localize faces in videos. The detected faces are then grouped respectively through carefully designed face association methods, especially for multi-shot videos. Finally, the faces are recognized by the proposed face matcher based on an unsupervised subspace learning approach and a subspace-to-subspace similarity metric. Extensive experiments on challenging video datasets, such as Multiple Biometric Grand Challenge (MBGC), Face and Ocular Challenge Series (FOCS), JANUS Challenge Set 6 (CS6) for low-quality surveillance videos and IARPA JANUS Benchmark B (IJB-B) for multiple-shot videos, demonstrate that the proposed system can accurately detect and associate faces from unconstrained videos and effectively learn robust and discriminative features for recognition.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018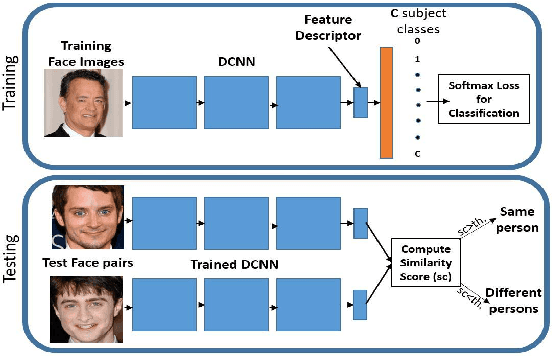
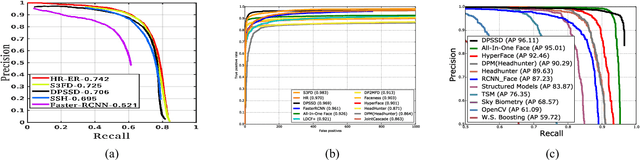
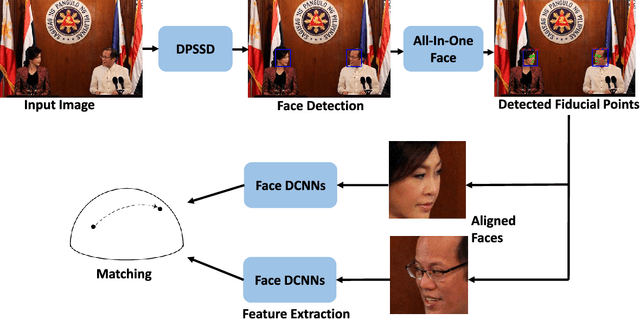
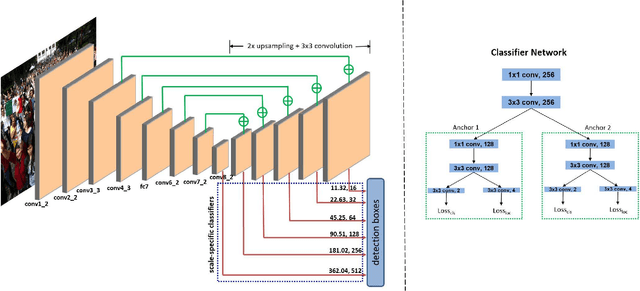
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
Representing Videos based on Scene Layouts for Recognizing Agent-in-Place Actions
Apr 04, 2018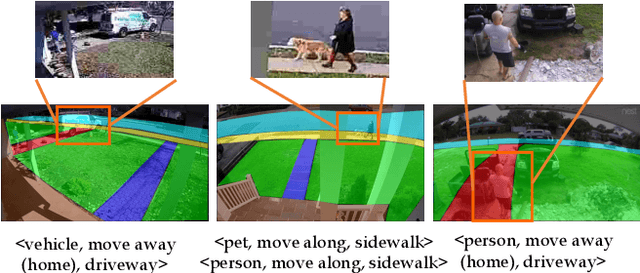
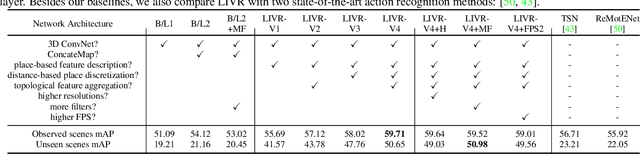
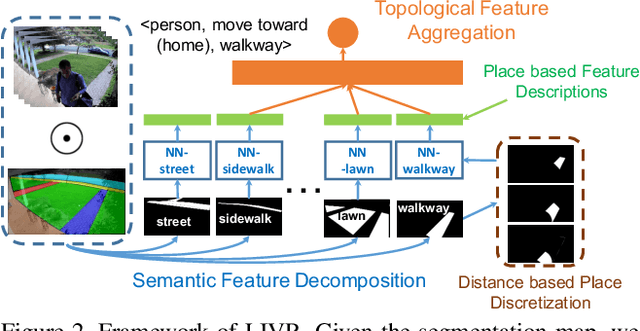
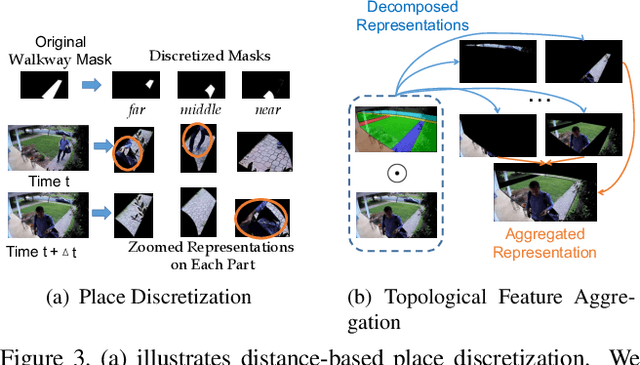
We address the recognition of agent-in-place actions, which are associated with agents who perform them and places where they occur, in the context of outdoor home surveillance. We introduce a representation of the geometry and topology of scene layouts so that a network can generalize from the layouts observed in the training set to unseen layouts in the test set. This Layout-Induced Video Representation (LIVR) abstracts away low-level appearance variance and encodes geometric and topological relationships of places in a specific scene layout. LIVR partitions the semantic features of a video clip into different places to force the network to learn place-based feature descriptions; to predict the confidence of each action, LIVR aggregates features from the place associated with an action and its adjacent places on the scene layout. We introduce the Agent-in-Place Action dataset to show that our method allows neural network models to generalize significantly better to unseen scenes.
Deep Heterogeneous Feature Fusion for Template-Based Face Recognition
Feb 15, 2017
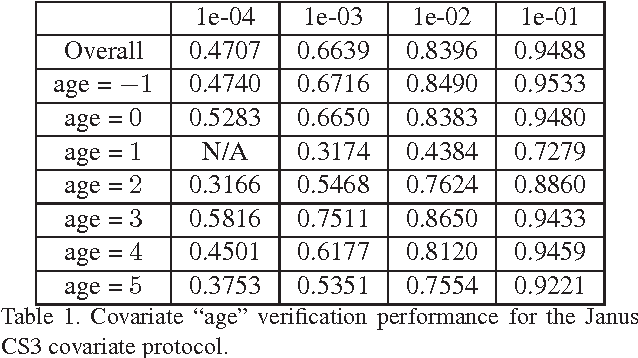
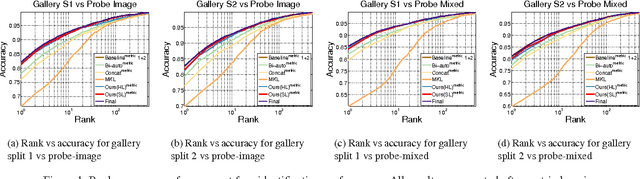
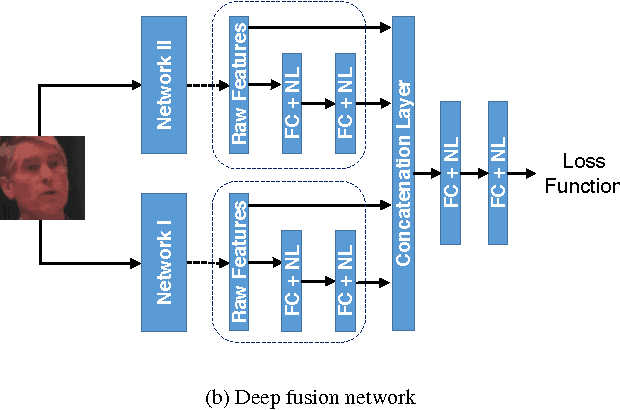
Although deep learning has yielded impressive performance for face recognition, many studies have shown that different networks learn different feature maps: while some networks are more receptive to pose and illumination others appear to capture more local information. Thus, in this work, we propose a deep heterogeneous feature fusion network to exploit the complementary information present in features generated by different deep convolutional neural networks (DCNNs) for template-based face recognition, where a template refers to a set of still face images or video frames from different sources which introduces more blur, pose, illumination and other variations than traditional face datasets. The proposed approach efficiently fuses the discriminative information of different deep features by 1) jointly learning the non-linear high-dimensional projection of the deep features and 2) generating a more discriminative template representation which preserves the inherent geometry of the deep features in the feature space. Experimental results on the IARPA Janus Challenge Set 3 (Janus CS3) dataset demonstrate that the proposed method can effectively improve the recognition performance. In addition, we also present a series of covariate experiments on the face verification task for in-depth qualitative evaluations for the proposed approach.