 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
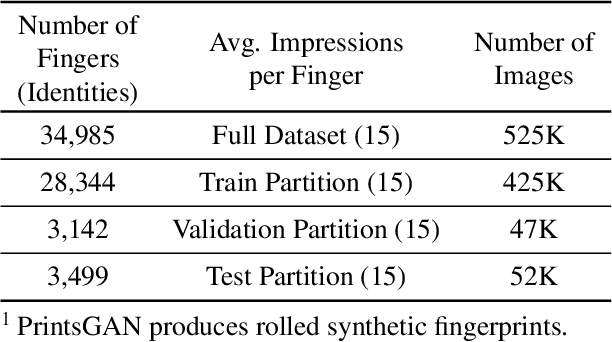
Add to EdgeData Pruning via Separability, Integrity, and Model Uncertainty-Aware Importance Sampling
Sep 20, 2024



This paper improves upon existing data pruning methods for image classification by introducing a novel pruning metric and pruning procedure based on importance sampling. The proposed pruning metric explicitly accounts for data separability, data integrity, and model uncertainty, while the sampling procedure is adaptive to the pruning ratio and considers both intra-class and inter-class separation to further enhance the effectiveness of pruning. Furthermore, the sampling method can readily be applied to other pruning metrics to improve their performance. Overall, the proposed approach scales well to high pruning ratio and generalizes better across different classification models, as demonstrated by experiments on four benchmark datasets, including the fine-grained classification scenario.
Minutiae-Guided Fingerprint Embeddings via Vision Transformers
Oct 26, 2022


Minutiae matching has long dominated the field of fingerprint recognition. However, deep networks can be used to extract fixed-length embeddings from fingerprints. To date, the few studies that have explored the use of CNN architectures to extract such embeddings have shown extreme promise. Inspired by these early works, we propose the first use of a Vision Transformer (ViT) to learn a discriminative fixed-length fingerprint embedding. We further demonstrate that by guiding the ViT to focus in on local, minutiae related features, we can boost the recognition performance. Finally, we show that by fusing embeddings learned by CNNs and ViTs we can reach near parity with a commercial state-of-the-art (SOTA) matcher. In particular, we obtain a TAR=94.23% @ FAR=0.1% on the NIST SD 302 public-domain dataset, compared to a SOTA commercial matcher which obtains TAR=96.71% @ FAR=0.1%. Additionally, our fixed-length embeddings can be matched orders of magnitude faster than the commercial system (2.5 million matches/second compared to 50K matches/second). We make our code and models publicly available to encourage further research on this topic: https://github.com/tba.
Deep Convolutional Neural Networks in the Face of Caricature: Identity and Image Revealed
Dec 28, 2018

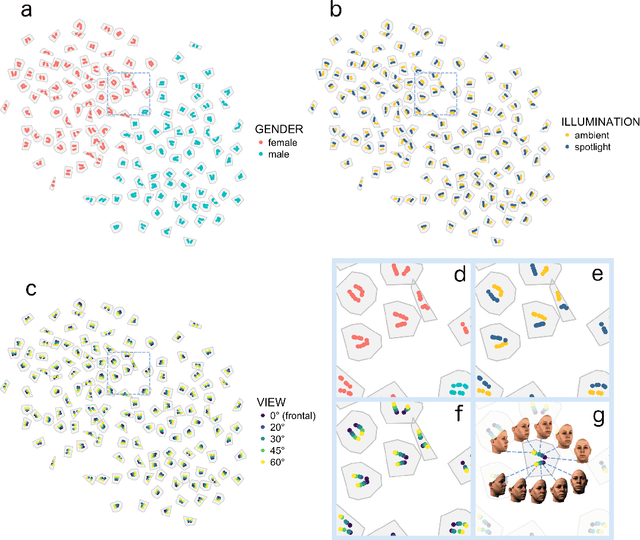
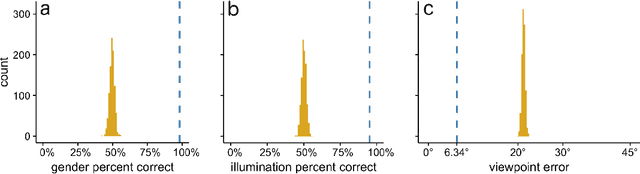
Real-world face recognition requires an ability to perceive the unique features of an individual face across multiple, variable images. The primate visual system solves the problem of image invariance using cascades of neurons that convert images of faces into categorical representations of facial identity. Deep convolutional neural networks (DCNNs) also create generalizable face representations, but with cascades of simulated neurons. DCNN representations can be examined in a multidimensional "face space", with identities and image parameters quantified via their projections onto the axes that define the space. We examined the organization of viewpoint, illumination, gender, and identity in this space. We show that the network creates a highly organized, hierarchically nested, face similarity structure in which information about face identity and imaging characteristics coexist. Natural image variation is accommodated in this hierarchy, with face identity nested under gender, illumination nested under identity, and viewpoint nested under illumination. To examine identity, we caricatured faces and found that network identification accuracy increased with caricature level, and--mimicking human perception--a caricatured distortion of a face "resembled" its veridical counterpart. Caricatures improved performance by moving the identity away from other identities in the face space and minimizing the effects of illumination and viewpoint. Deep networks produce face representations that solve long-standing computational problems in generalized face recognition. They also provide a unitary theoretical framework for reconciling decades of behavioral and neural results that emphasized either the image or the object/face in representations, without understanding how a neural code could seamlessly accommodate both.
An Automatic System for Unconstrained Video-Based Face Recognition
Dec 10, 2018

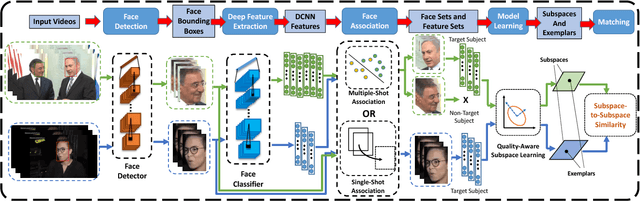

Although deep learning approaches have achieved performance surpassing humans for still image-based face recognition, unconstrained video-based face recognition is still a challenging task due to large volume of data to be processed and intra/inter-video variations on pose, illumination, occlusion, scene, blur, video quality, etc. In this work, we consider challenging scenarios for unconstrained video-based face recognition from multiple-shot videos and surveillance videos with low-quality frames. To handle these problems, we propose a robust and efficient system for unconstrained video-based face recognition, which is composed of face/fiducial detection, face association, and face recognition. First, we use multi-scale single-shot face detectors to efficiently localize faces in videos. The detected faces are then grouped respectively through carefully designed face association methods, especially for multi-shot videos. Finally, the faces are recognized by the proposed face matcher based on an unsupervised subspace learning approach and a subspace-to-subspace similarity metric. Extensive experiments on challenging video datasets, such as Multiple Biometric Grand Challenge (MBGC), Face and Ocular Challenge Series (FOCS), JANUS Challenge Set 6 (CS6) for low-quality surveillance videos and IARPA JANUS Benchmark B (IJB-B) for multiple-shot videos, demonstrate that the proposed system can accurately detect and associate faces from unconstrained videos and effectively learn robust and discriminative features for recognition.
A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos
Nov 23, 2018


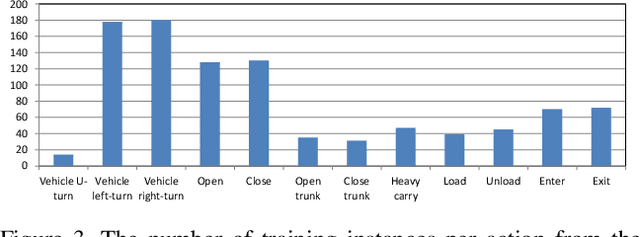
Existing approaches for spatio-temporal action detection in videos are limited by the spatial extent and temporal duration of the actions. In this paper, we present a modular system for spatio-temporal action detection in untrimmed security videos. We propose a two stage approach. The first stage generates dense spatio-temporal proposals using hierarchical clustering and temporal jittering techniques on frame-wise object detections. The second stage is a Temporal Refinement I3D (TRI-3D) network that performs action classification and temporal refinement on the generated proposals. The object detection-based proposal generation step helps in detecting actions occurring in a small spatial region of a video frame, while temporal jittering and refinement helps in detecting actions of variable lengths. Experimental results on the spatio-temporal action detection dataset - DIVA - show the effectiveness of our system. For comparison, the performance of our system is also evaluated on the THUMOS14 temporal action detection dataset.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018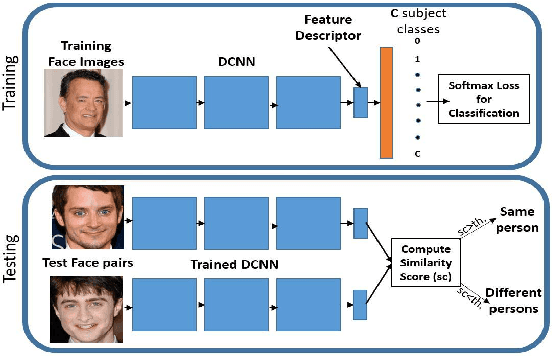
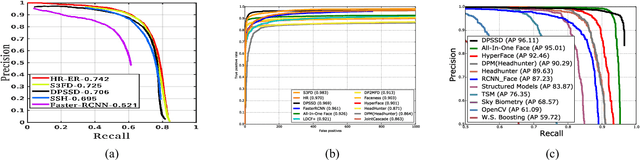
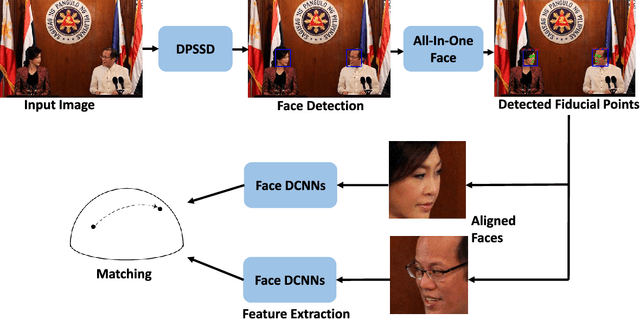
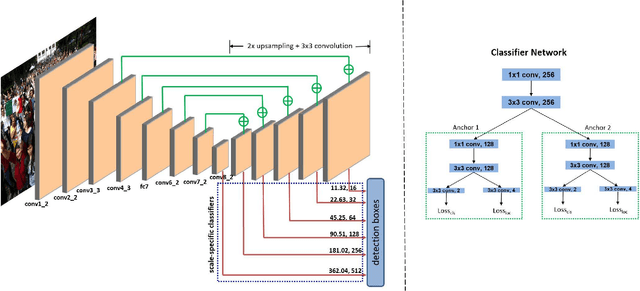
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
Locate, Segment and Match: A Pipeline for Object Matching and Registration
May 01, 2018
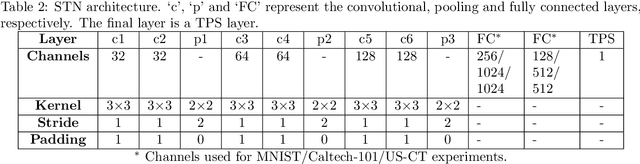
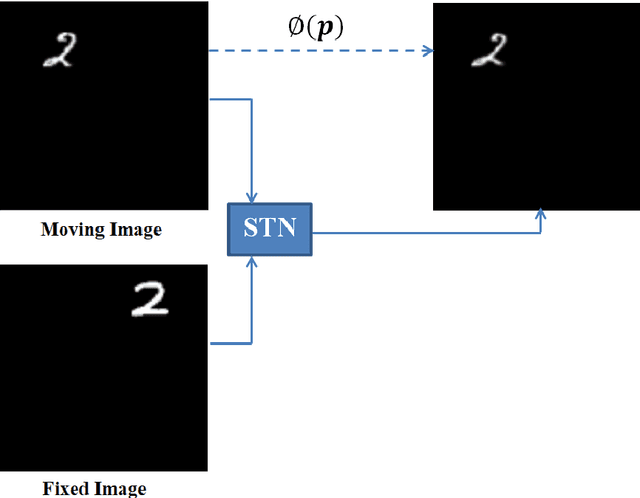
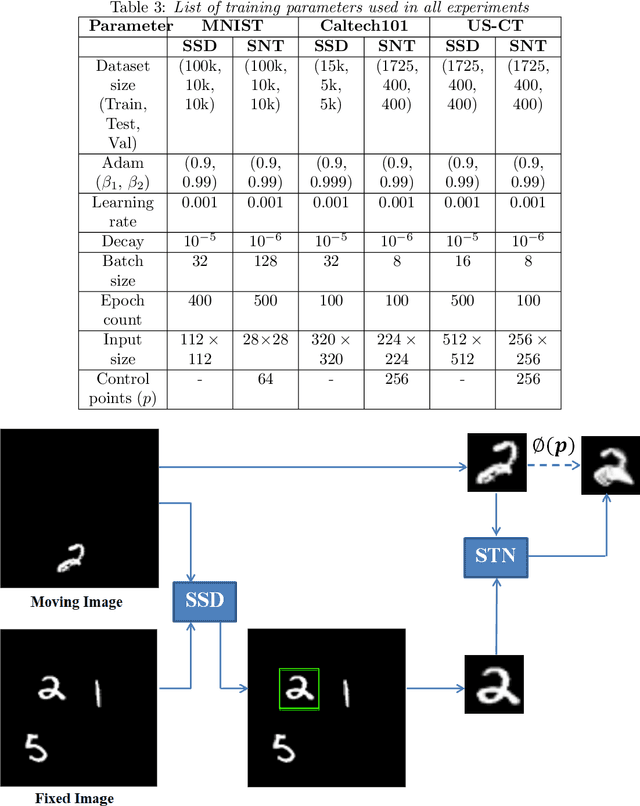
Image registration requires simultaneous processing of multiple images to match the keypoints or landmarks of the contained objects. These images often come from different modalities for example CT and Ultrasound (US), and pose the challenge of establishing one to one correspondence. In this work, a novel pipeline of convolutional neural networks is developed to perform the desired registration. The complete objective is divided into three parts: localization of the object of interest, segmentation and matching transformation. Most of the existing approaches skip the localization step and are prone to fail in general scenarios. We overcome this challenge through detection which also establishes initial correspondence between the images. A modified version of single shot multibox detector is used for this purpose. The detected region is cropped and subsequently segmented to generate a mask corresponding to the desired object. The mask is used by a spatial transformer network employing thin plate spline deformation to perform the desired registration. Initial experiments on MNIST and Caltech-101 datasets show that the proposed model is able to accurately match the segmented images. The proposed framework is extended to the registration of CT and US images, which is free from any data specific assumptions and has better generalization capability as compared to the existing rule based/classical approaches.
Light-weight Head Pose Invariant Gaze Tracking
Apr 23, 2018

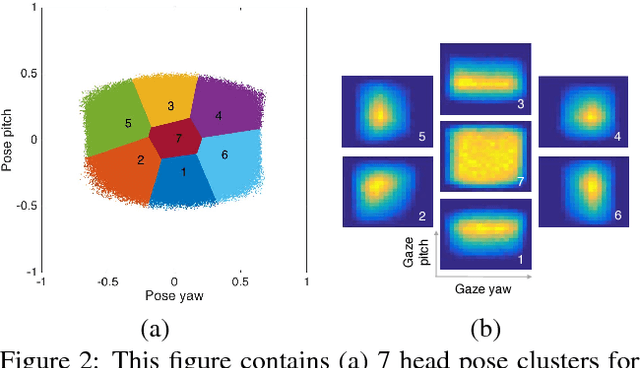
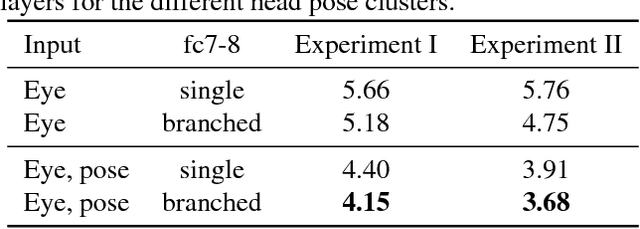
Unconstrained remote gaze tracking using off-the-shelf cameras is a challenging problem. Recently, promising algorithms for appearance-based gaze estimation using convolutional neural networks (CNN) have been proposed. Improving their robustness to various confounding factors including variable head pose, subject identity, illumination and image quality remain open problems. In this work, we study the effect of variable head pose on machine learning regressors trained to estimate gaze direction. We propose a novel branched CNN architecture that improves the robustness of gaze classifiers to variable head pose, without increasing computational cost. We also present various procedures to effectively train our gaze network including transfer learning from the more closely related task of object viewpoint estimation and from a large high-fidelity synthetic gaze dataset, which enable our ten times faster gaze network to achieve competitive accuracy to its current state-of-the-art direct competitor.
Crystal Loss and Quality Pooling for Unconstrained Face Verification and Recognition
Apr 03, 2018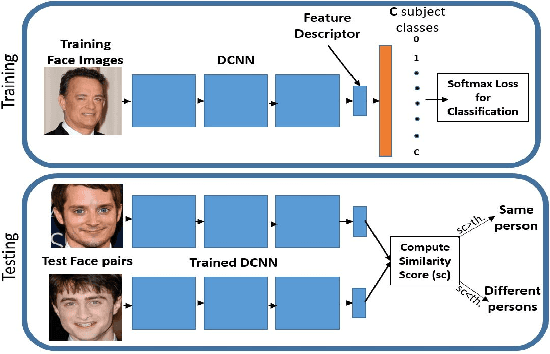

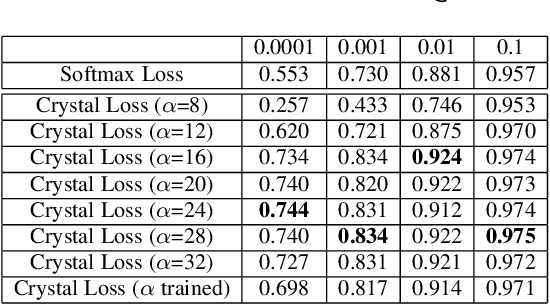
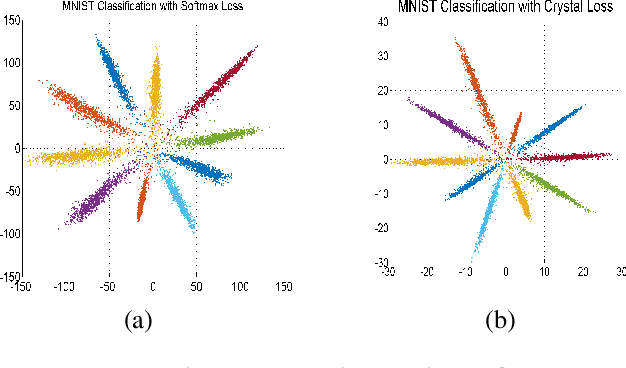
In recent years, the performance of face verification and recognition systems based on deep convolutional neural networks (DCNNs) has significantly improved. A typical pipeline for face verification includes training a deep network for subject classification with softmax loss, using the penultimate layer output as the feature descriptor, and generating a cosine similarity score given a pair of face images or videos. The softmax loss function does not optimize the features to have higher similarity score for positive pairs and lower similarity score for negative pairs, which leads to a performance gap. In this paper, we propose a new loss function, called Crystal Loss, that restricts the features to lie on a hypersphere of a fixed radius. The loss can be easily implemented using existing deep learning frameworks. We show that integrating this simple step in the training pipeline significantly improves the performance of face verification and recognition systems. We achieve state-of-the-art performance for face verification and recognition on challenging LFW, IJB-A, IJB-B and IJB-C datasets over a large range of false alarm rates (10-1 to 10-7).
Improving Network Robustness against Adversarial Attacks with Compact Convolution
Mar 22, 2018
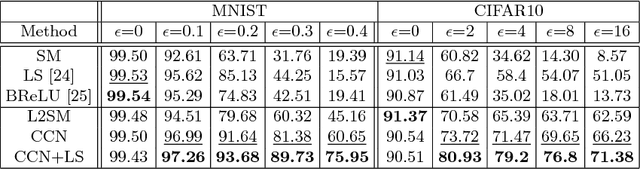
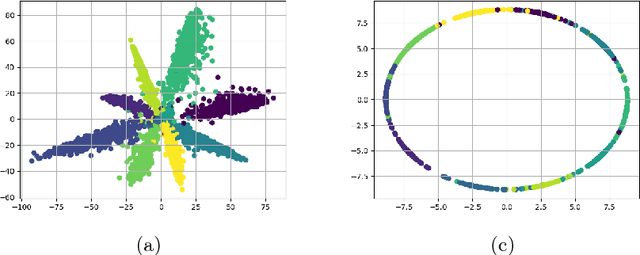
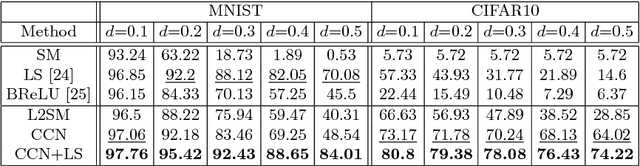
Though Convolutional Neural Networks (CNNs) have surpassed human-level performance on tasks such as object classification and face verification, they can easily be fooled by adversarial attacks. These attacks add a small perturbation to the input image that causes the network to misclassify the sample. In this paper, we focus on neutralizing adversarial attacks by compact feature learning. In particular, we show that learning features in a closed and bounded space improves the robustness of the network. We explore the effect of L2-Softmax Loss, that enforces compactness in the learned features, thus resulting in enhanced robustness to adversarial perturbations. Additionally, we propose compact convolution, a novel method of convolution that when incorporated in conventional CNNs improves their robustness. Compact convolution ensures feature compactness at every layer such that they are bounded and close to each other. Extensive experiments show that Compact Convolutional Networks (CCNs) neutralize multiple types of attacks, and perform better than existing methods in defending adversarial attacks, without incurring any additional training overhead compared to CNNs.