 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Modeling of Contextual-Connection between Tracklets for Unconstrained Video-based Face Recognition
May 07, 2019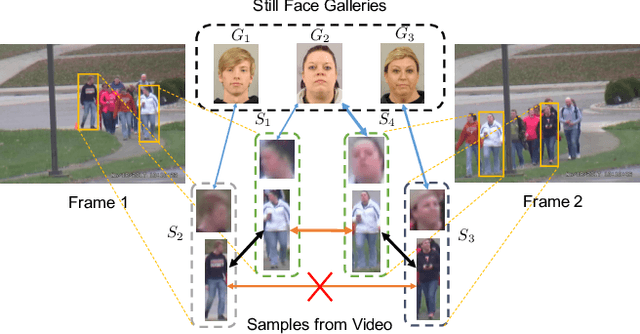
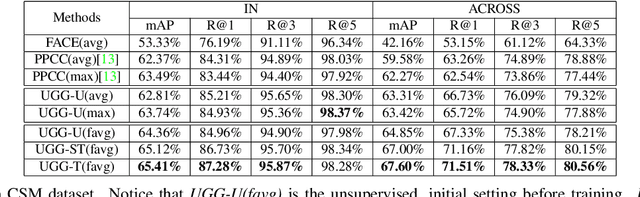
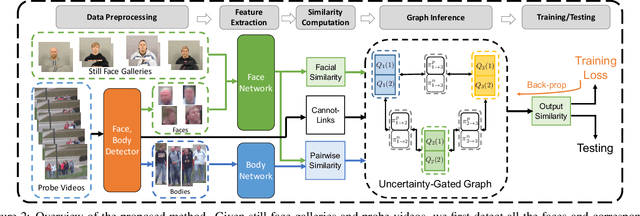

Unconstrained video-based face recognition is a challenging problem due to significant within-video variations caused by pose, occlusion and blur. To tackle this problem, an effective idea is to propagate the identity from high-quality faces to low-quality ones through contextual connections, which are constructed based on context such as body appearance. However, previous methods have often propagated erroneous information due to lack of uncertainty modeling of the noisy contextual connections. In this paper, we propose the Uncertainty-Gated Graph (UGG), which conducts graph-based identity propagation between tracklets, which are represented by nodes in a graph. UGG explicitly models the uncertainty of the contextual connections by adaptively updating the weights of the edge gates according to the identity distributions of the nodes during inference. UGG is a generic graphical model that can be applied at only inference time or with end-to-end training. We demonstrate the effectiveness of UGG with state-of-the-art results in the recently released challenging Cast Search in Movies and IARPA Janus Surveillance Video Benchmark dataset.
Unsupervised Domain-Specific Deblurring via Disentangled Representations
Mar 05, 2019
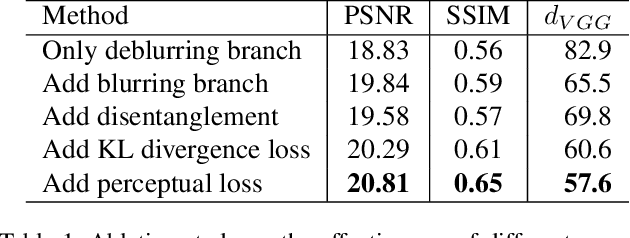
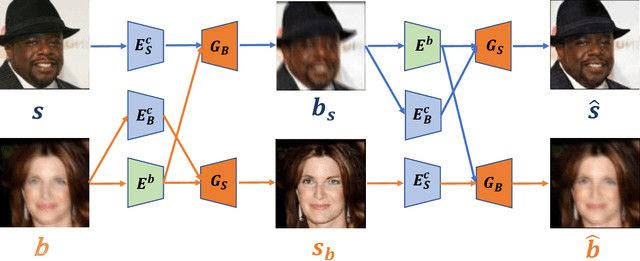
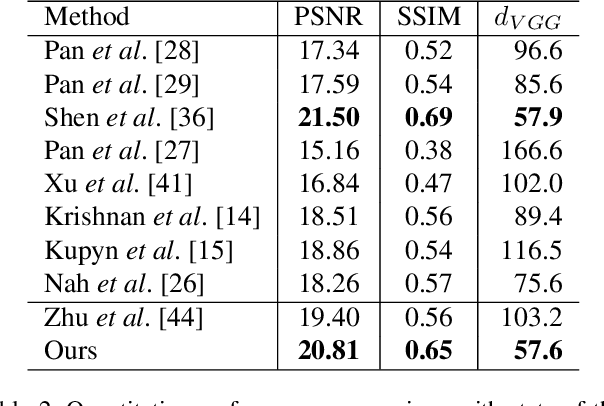
Image deblurring aims to restore the latent sharp images from the corresponding blurred ones. In this paper, we present an unsupervised method for domain-specific single-image deblurring based on disentangled representations. The disentanglement is achieved by splitting the content and blur features in a blurred image using content encoders and blur encoders. We enforce a KL divergence loss to regularize the distribution range of extracted blur attributes such that little content information is contained. Meanwhile, to handle the unpaired training data, a blurring branch and the cycle-consistency loss are added to guarantee that the content structures of the deblurred results match the original images. We also add an adversarial loss on deblurred results to generate visually realistic images and a perceptual loss to further mitigate the artifacts. We perform extensive experiments on the tasks of face and text deblurring using both synthetic datasets and real images, and achieve improved results compared to recent state-of-the-art deblurring methods.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018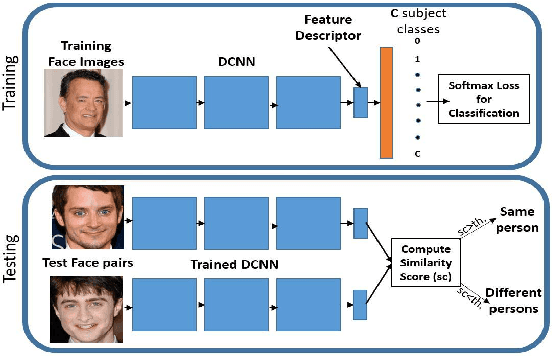
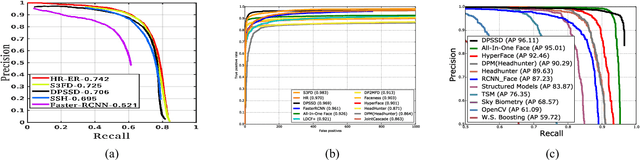
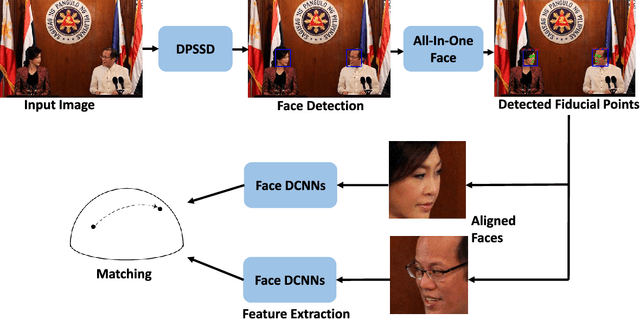
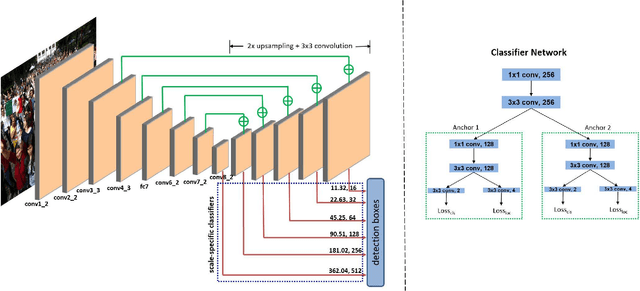
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
An Experimental Evaluation of Covariates Effects on Unconstrained Face Verification
Aug 16, 2018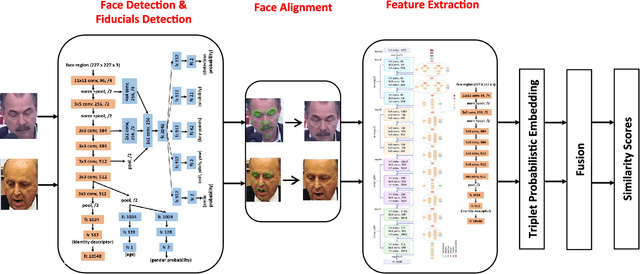


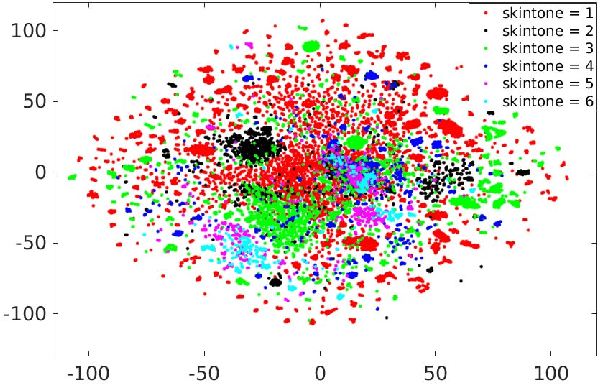
Covariates are factors that have a debilitating influence on face verification performance. In this paper, we comprehensively study two covariate related problems for unconstrained face verification: first, how covariates affect the performance of deep neural networks on the large-scale unconstrained face verification problem; second, how to utilize covariates to improve verification performance. To study the first problem, we implement five state-of-the-art deep convolutional networks (DCNNs) for face verification and evaluate them on three challenging covariates datasets. In total, seven covariates are considered: pose (yaw and roll), age, facial hair, gender, indoor/outdoor, occlusion (nose and mouth visibility, eyes visibility, and forehead visibility), and skin tone. These covariates cover both intrinsic subject-specific characteristics and extrinsic factors of faces. Some of the results confirm and extend the findings of previous studies, others are new findings that were rarely mentioned previously or did not show consistent trends. For the second problem, we demonstrate that with the assistance of gender information, the quality of a pre-curated noisy large-scale face dataset for face recognition can be further improved. After retraining the face recognition model using the curated data, performance improvement is observed at low False Acceptance Rates (FARs) (FAR=$10^{-5}$, $10^{-6}$, $10^{-7}$).