 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds
Dec 09, 2024
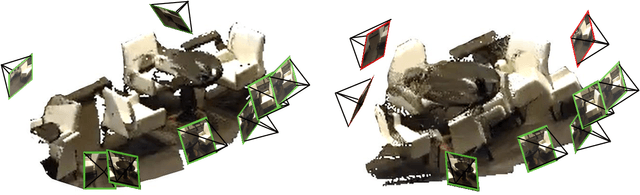
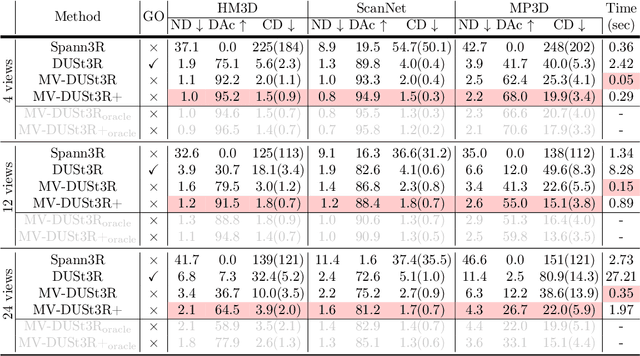
Recent sparse multi-view scene reconstruction advances like DUSt3R and MASt3R no longer require camera calibration and camera pose estimation. However, they only process a pair of views at a time to infer pixel-aligned pointmaps. When dealing with more than two views, a combinatorial number of error prone pairwise reconstructions are usually followed by an expensive global optimization, which often fails to rectify the pairwise reconstruction errors. To handle more views, reduce errors, and improve inference time, we propose the fast single-stage feed-forward network MV-DUSt3R. At its core are multi-view decoder blocks which exchange information across any number of views while considering one reference view. To make our method robust to reference view selection, we further propose MV-DUSt3R+, which employs cross-reference-view blocks to fuse information across different reference view choices. To further enable novel view synthesis, we extend both by adding and jointly training Gaussian splatting heads. Experiments on multi-view stereo reconstruction, multi-view pose estimation, and novel view synthesis confirm that our methods improve significantly upon prior art. Code will be released.
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture
May 18, 2023



The techniques for 3D indoor scene capturing are widely used, but the meshes produced leave much to be desired. In this paper, we propose "RoomDreamer", which leverages powerful natural language to synthesize a new room with a different style. Unlike existing image synthesis methods, our work addresses the challenge of synthesizing both geometry and texture aligned to the input scene structure and prompt simultaneously. The key insight is that a scene should be treated as a whole, taking into account both scene texture and geometry. The proposed framework consists of two significant components: Geometry Guided Diffusion and Mesh Optimization. Geometry Guided Diffusion for 3D Scene guarantees the consistency of the scene style by applying the 2D prior to the entire scene simultaneously. Mesh Optimization improves the geometry and texture jointly and eliminates the artifacts in the scanned scene. To validate the proposed method, real indoor scenes scanned with smartphones are used for extensive experiments, through which the effectiveness of our method is demonstrated.
Delving into Robust Object Detection from Unmanned Aerial Vehicles: A Deep Nuisance Disentanglement Approach
Aug 11, 2019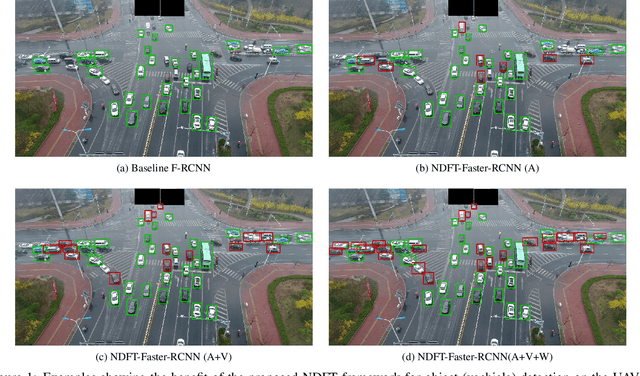
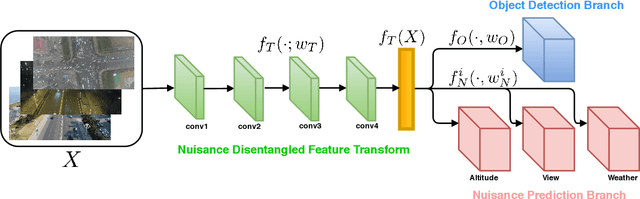


Object detection from images captured by Unmanned Aerial Vehicles (UAVs) is becoming increasingly useful. Despite the great success of the generic object detection methods trained on ground-to-ground images, a huge performance drop is observed when they are directly applied to images captured by UAVs. The unsatisfactory performance is owing to many UAV-specific nuisances, such as varying flying altitudes, adverse weather conditions, dynamically changing viewing angles, etc. Those nuisances constitute a large number of fine-grained domains, across which the detection model has to stay robust. Fortunately, UAVs will record meta-data that depict those varying attributes, which are either freely available along with the UAV images, or can be easily obtained. We propose to utilize those free meta-data in conjunction with associated UAV images to learn domain-robust features via an adversarial training framework dubbed Nuisance Disentangled Feature Transform (NDFT), for the specific challenging problem of object detection in UAV images, achieving a substantial gain in robustness to those nuisances. We demonstrate the effectiveness of our proposed algorithm, by showing state-of-the-art performance (single model) on two existing UAV-based object detection benchmarks. The code is available at https://github.com/TAMU-VITA/UAV-NDFT.
Deep Regionlets: Blended Representation and Deep Learning for Generic Object Detection
Nov 28, 2018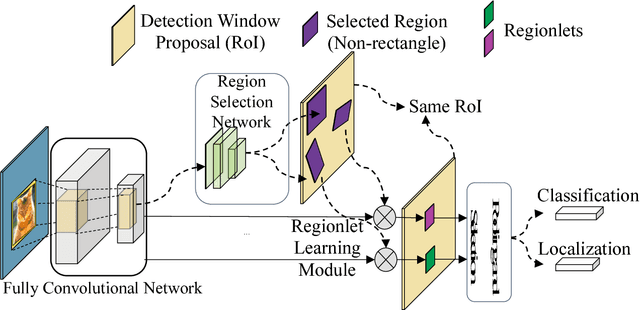
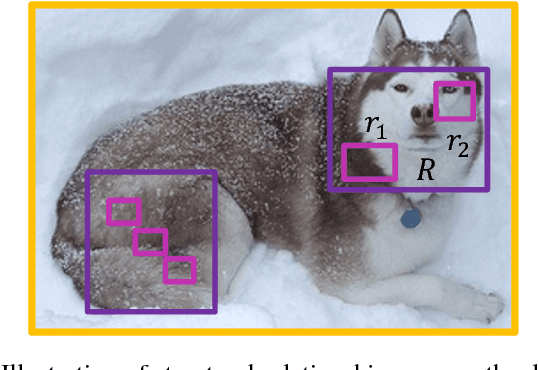

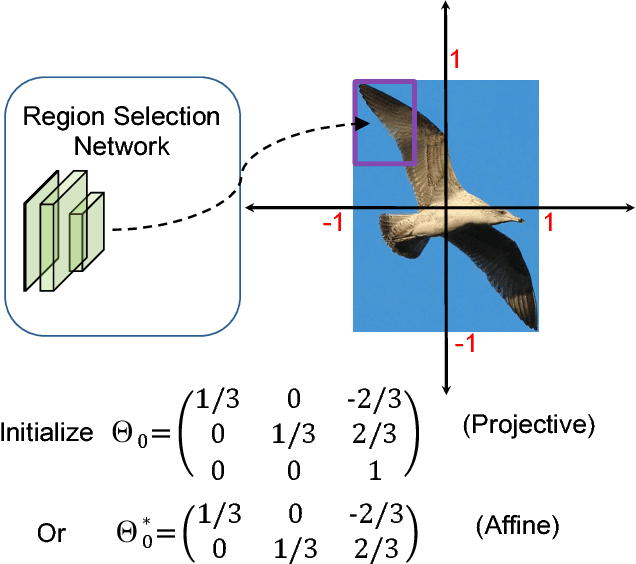
In this paper, we propose a novel object detection algorithm named "Deep Regionlets" by integrating deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the advantages of regionlets on modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions from which features can be learned from. The regionlet learning module focuses on local feature selection and transformation to alleviate the effects of appearance variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We present the results of ablation studies and extensive experiments on PASCAL VOC and Microsoft COCO datasets. The proposed algorithm outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018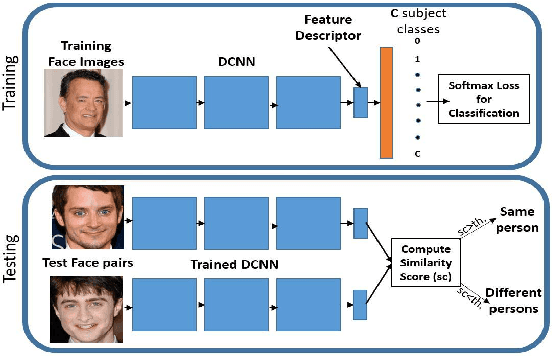
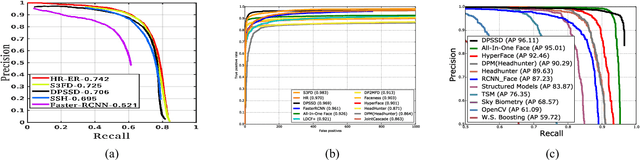
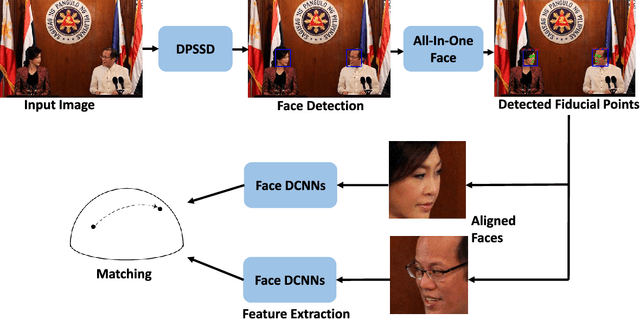
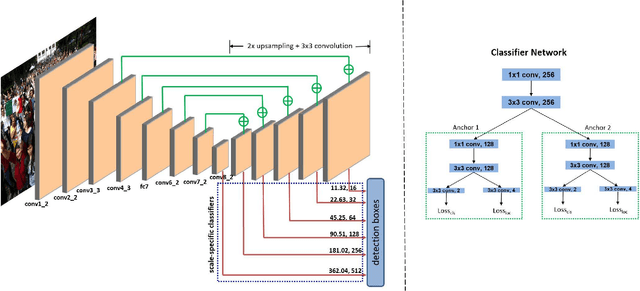
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
Deep Regionlets for Object Detection
Aug 23, 2018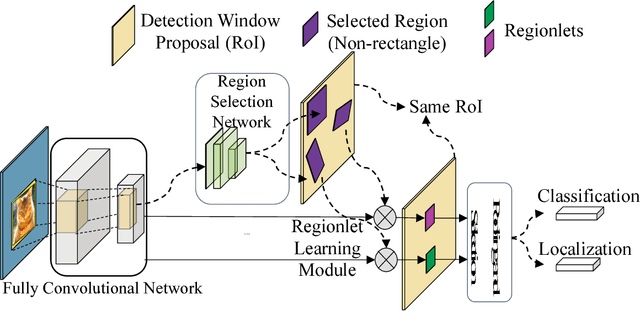
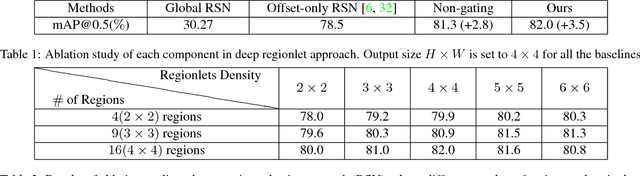
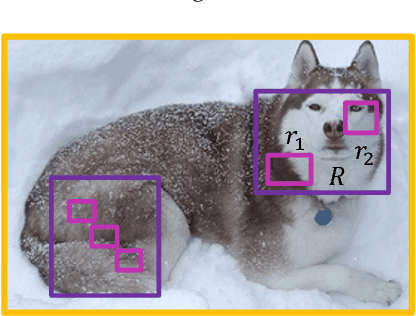
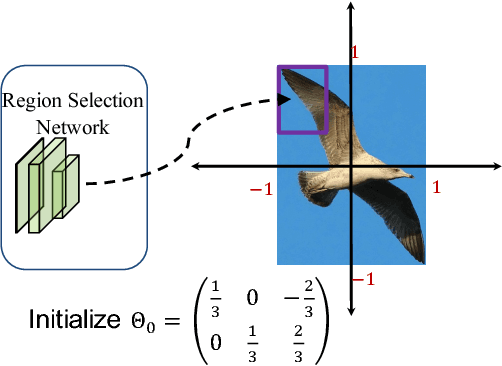
In this paper, we propose a novel object detection framework named "Deep Regionlets" by establishing a bridge between deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the abilities of regionlets for modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions to learn the features from. The regionlet learning module focuses on local feature selection and transformation to alleviate local variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We perform ablation studies and conduct extensive experiments on the PASCAL VOC and Microsoft COCO datasets. The proposed framework outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
Learning Simple Thresholded Features with Sparse Support Recovery
Apr 16, 2018
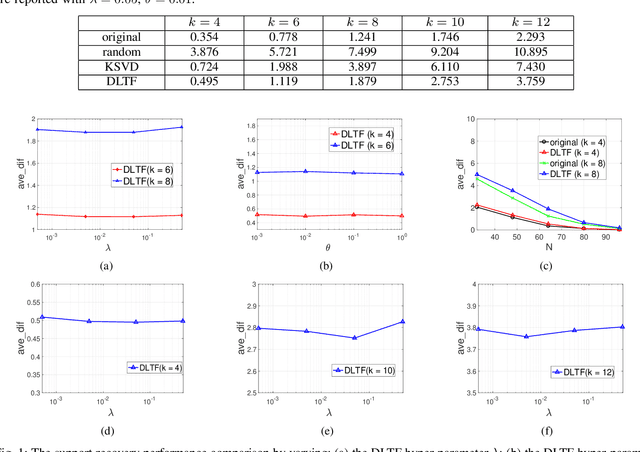
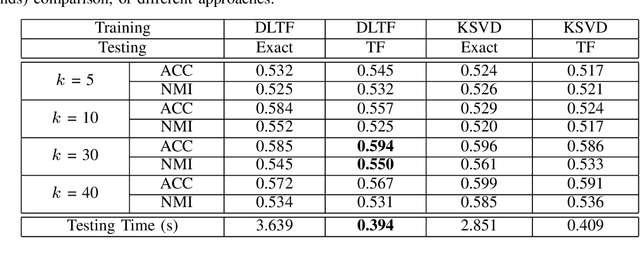

The thresholded feature has recently emerged as an extremely efficient, yet rough empirical approximation, of the time-consuming sparse coding inference process. Such an approximation has not yet been rigorously examined, and standard dictionaries often lead to non-optimal performance when used for computing thresholded features. In this paper, we first present two theoretical recovery guarantees for the thresholded feature to exactly recover the nonzero support of the sparse code. Motivated by them, we then formulate the Dictionary Learning for Thresholded Features (DLTF) model, which learns an optimized dictionary for applying the thresholded feature. In particular, for the $(k, 2)$ norm involved, a novel proximal operator with log-linear time complexity $O(m\log m)$ is derived. We evaluate the performance of DLTF on a vast range of synthetic and real-data tasks, where DLTF demonstrates remarkable efficiency, effectiveness and robustness in all experiments. In addition, we briefly discuss the potential link between DLTF and deep learning building blocks.