 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Learning of Low-Precision Networks
May 28, 2019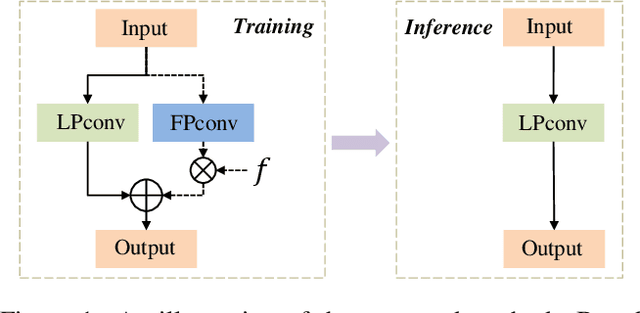
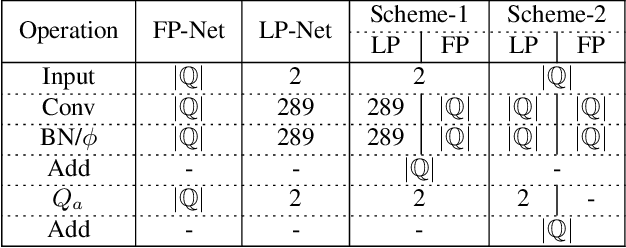
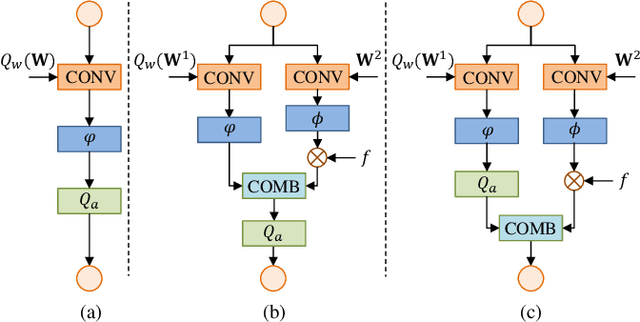

Recent years have witnessed the great advance of deep learning in a variety of vision tasks. Many state-of-the-art deep neural networks suffer from large size and high complexity, which makes it difficult to deploy in resource-limited platforms such as mobile devices. To this end, low-precision neural networks are widely studied which quantize weights or activations into the low-bit format. Though being efficient, low-precision networks are usually hard to train and encounter severe accuracy degradation. In this paper, we propose a new training strategy through expanding low-precision networks during training and removing the expanded parts for network inference. First, we equip each low-precision convolutional layer with an ancillary full-precision convolutional layer based on a low-precision network structure, which could guide the network to good local minima. Second, a decay method is introduced to reduce the output of the added full-precision convolution gradually, which keeps the resulted topology structure the same to the original low-precision one. Experiments on SVHN, CIFAR and ILSVRC-2012 datasets prove that the proposed method can bring faster convergence and higher accuracy for low-precision neural networks.
Deep Regionlets: Blended Representation and Deep Learning for Generic Object Detection
Nov 28, 2018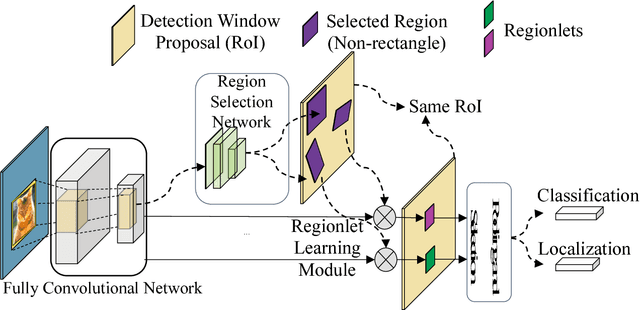
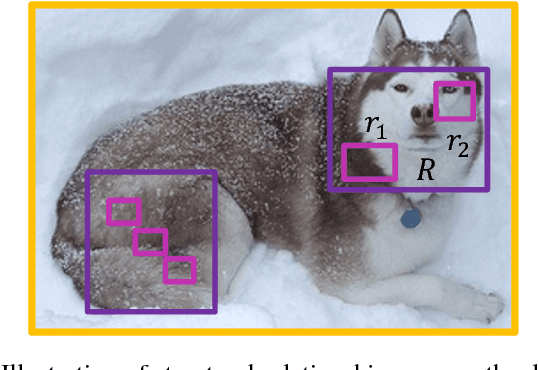

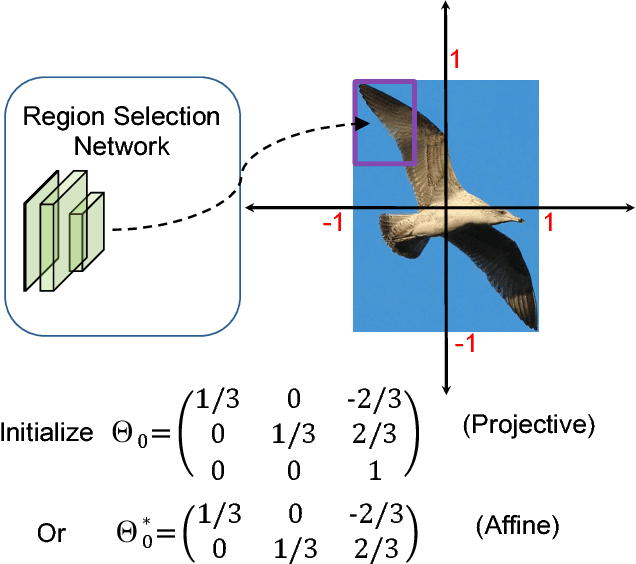
In this paper, we propose a novel object detection algorithm named "Deep Regionlets" by integrating deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the advantages of regionlets on modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions from which features can be learned from. The regionlet learning module focuses on local feature selection and transformation to alleviate the effects of appearance variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We present the results of ablation studies and extensive experiments on PASCAL VOC and Microsoft COCO datasets. The proposed algorithm outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
Deep Regionlets for Object Detection
Aug 23, 2018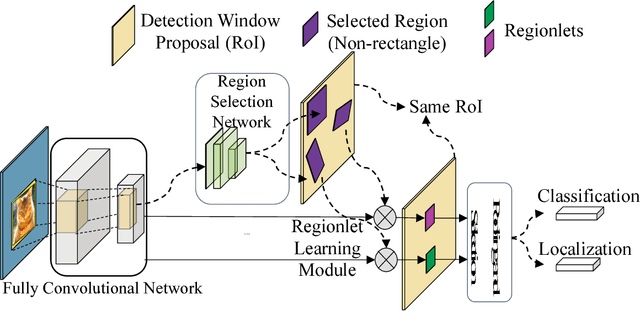
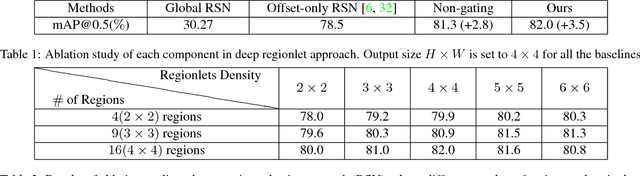
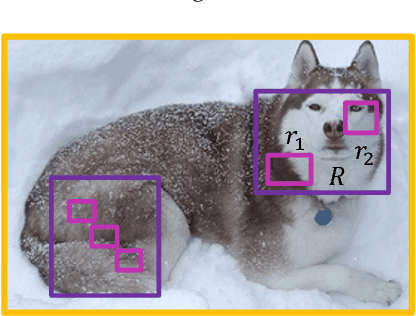
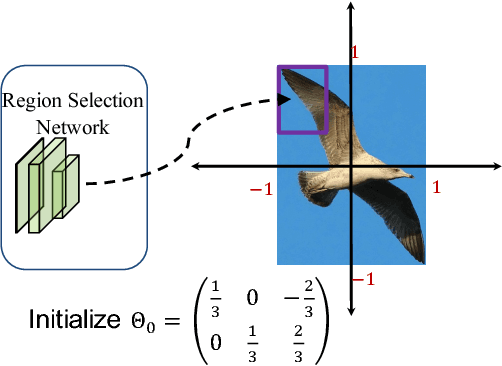
In this paper, we propose a novel object detection framework named "Deep Regionlets" by establishing a bridge between deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the abilities of regionlets for modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions to learn the features from. The regionlet learning module focuses on local feature selection and transformation to alleviate local variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We perform ablation studies and conduct extensive experiments on the PASCAL VOC and Microsoft COCO datasets. The proposed framework outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
SEP-Nets: Small and Effective Pattern Networks
Jun 13, 2017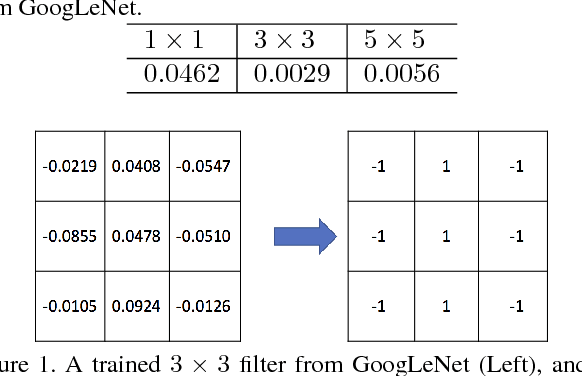
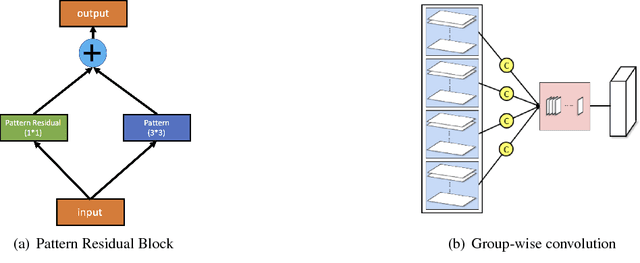


While going deeper has been witnessed to improve the performance of convolutional neural networks (CNN), going smaller for CNN has received increasing attention recently due to its attractiveness for mobile/embedded applications. It remains an active and important topic how to design a small network while retaining the performance of large and deep CNNs (e.g., Inception Nets, ResNets). Albeit there are already intensive studies on compressing the size of CNNs, the considerable drop of performance is still a key concern in many designs. This paper addresses this concern with several new contributions. First, we propose a simple yet powerful method for compressing the size of deep CNNs based on parameter binarization. The striking difference from most previous work on parameter binarization/quantization lies at different treatments of $1\times 1$ convolutions and $k\times k$ convolutions ($k>1$), where we only binarize $k\times k$ convolutions into binary patterns. The resulting networks are referred to as pattern networks. By doing this, we show that previous deep CNNs such as GoogLeNet and Inception-type Nets can be compressed dramatically with marginal drop in performance. Second, in light of the different functionalities of $1\times 1$ (data projection/transformation) and $k\times k$ convolutions (pattern extraction), we propose a new block structure codenamed the pattern residual block that adds transformed feature maps generated by $1\times 1$ convolutions to the pattern feature maps generated by $k\times k$ convolutions, based on which we design a small network with $\sim 1$ million parameters. Combining with our parameter binarization, we achieve better performance on ImageNet than using similar sized networks including recently released Google MobileNets.
Deep Reinforcement Learning-based Image Captioning with Embedding Reward
Apr 12, 2017

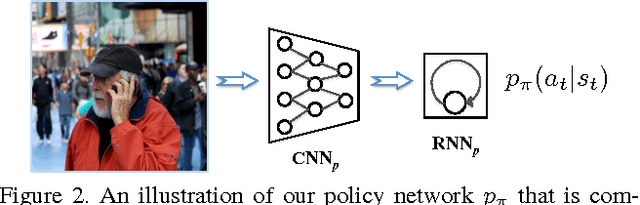

Image captioning is a challenging problem owing to the complexity in understanding the image content and diverse ways of describing it in natural language. Recent advances in deep neural networks have substantially improved the performance of this task. Most state-of-the-art approaches follow an encoder-decoder framework, which generates captions using a sequential recurrent prediction model. However, in this paper, we introduce a novel decision-making framework for image captioning. We utilize a "policy network" and a "value network" to collaboratively generate captions. The policy network serves as a local guidance by providing the confidence of predicting the next word according to the current state. Additionally, the value network serves as a global and lookahead guidance by evaluating all possible extensions of the current state. In essence, it adjusts the goal of predicting the correct words towards the goal of generating captions similar to the ground truth captions. We train both networks using an actor-critic reinforcement learning model, with a novel reward defined by visual-semantic embedding. Extensive experiments and analyses on the Microsoft COCO dataset show that the proposed framework outperforms state-of-the-art approaches across different evaluation metrics.