 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEP-Nets: Small and Effective Pattern Networks
Paper and Code
Jun 13, 2017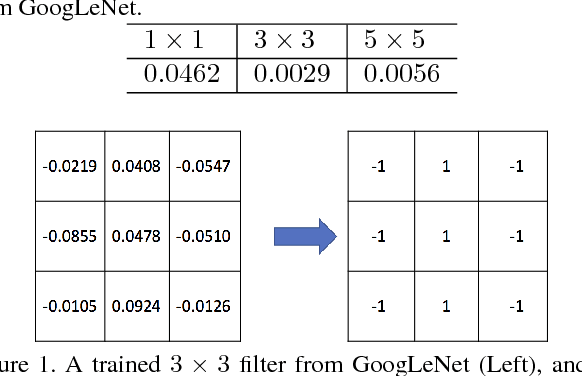
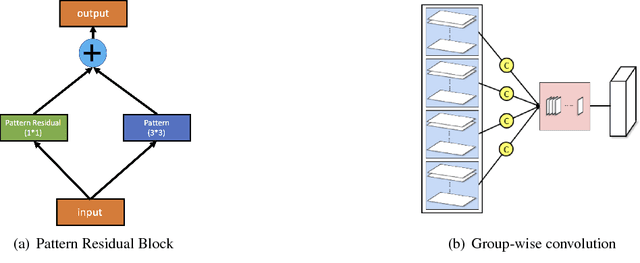


While going deeper has been witnessed to improve the performance of convolutional neural networks (CNN), going smaller for CNN has received increasing attention recently due to its attractiveness for mobile/embedded applications. It remains an active and important topic how to design a small network while retaining the performance of large and deep CNNs (e.g., Inception Nets, ResNets). Albeit there are already intensive studies on compressing the size of CNNs, the considerable drop of performance is still a key concern in many designs. This paper addresses this concern with several new contributions. First, we propose a simple yet powerful method for compressing the size of deep CNNs based on parameter binarization. The striking difference from most previous work on parameter binarization/quantization lies at different treatments of $1\times 1$ convolutions and $k\times k$ convolutions ($k>1$), where we only binarize $k\times k$ convolutions into binary patterns. The resulting networks are referred to as pattern networks. By doing this, we show that previous deep CNNs such as GoogLeNet and Inception-type Nets can be compressed dramatically with marginal drop in performance. Second, in light of the different functionalities of $1\times 1$ (data projection/transformation) and $k\times k$ convolutions (pattern extraction), we propose a new block structure codenamed the pattern residual block that adds transformed feature maps generated by $1\times 1$ convolutions to the pattern feature maps generated by $k\times k$ convolutions, based on which we design a small network with $\sim 1$ million parameters. Combining with our parameter binarization, we achieve better performance on ImageNet than using similar sized networks including recently released Google MobileNets.