 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpike Hijacking in Late-Interaction Retrieval
Apr 06, 2026Late-interaction retrieval models rely on hard maximum similarity (MaxSim) to aggregate token-level similarities. Although effective, this winner-take-all pooling rule may structurally bias training dynamics. We provide a mechanistic study of gradient routing and robustness in MaxSim-based retrieval. In a controlled synthetic environment with in-batch contrastive training, we demonstrate that MaxSim induces significantly higher patch-level gradient concentration than smoother alternatives such as Top-k pooling and softmax aggregation. While sparse routing can improve early discrimination, it also increases sensitivity to document length: as the number of document patches grows, MaxSim degrades more sharply than mild smoothing variants. We corroborate these findings on a real-world multi-vector retrieval benchmark, where controlled document-length sweeps reveal similar brittleness under hard max pooling. Together, our results isolate pooling-induced gradient concentration as a structural property of late-interaction retrieval and highlight a sparsity-robustness tradeoff. These findings motivate principled alternatives to hard max pooling in multi-vector retrieval systems.
CPT: Controllable and Editable Design Variations with Language Models
Apr 06, 2026Designing visually diverse and high-quality designs remains a manual, time-consuming process, limiting scalability and personalization in creative workflows. We present a system for generating editable design variations using a decoder-only language model, the Creative Pre-trained Transformer (CPT), trained to predict visual style attributes in design templates. At the core of our approach is a new representation called Creative Markup Language (CML), a compact, machine-learning-friendly format that captures canvas-level structure, page layout, and element-level details (text, images, and vector graphics), including both content and style. We fine-tune CPT on a large corpus of design templates authored by professional designers, enabling it to learn meaningful, context-aware predictions for attributes such as color schemes and font choices. The model produces semantically structured and stylistically coherent outputs, preserving internal consistency across elements. Unlike generative image models, our system yields fully editable design documents rather than pixel-only images, allowing users to iterate and personalize within a design editor. In experiments, our approach generates contextual color and font variations for existing templates and shows promise in adjusting layouts while maintaining design principles.
Retrieval-Augmented Question Answering over Scientific Literature for the Electron-Ion Collider
Apr 02, 2026To harness the power of Language Models in answering domain specific specialized technical questions, Retrieval Augmented Generation (RAG) is been used widely. In this work, we have developed a Q\&A application inspired by the Retrieval Augmented Generation (RAG), which is comprised of an in-house database indexed on the arXiv articles related to the Electron-Ion Collider (EIC) experiment - one of the largest international scientific collaboration and incorporated an open-source LLaMA model for answer generation. This is an extension to it's proceeding application built on proprietary model and Cloud-hosted external knowledge-base for the EIC experiment. This locally-deployed RAG-system offers a cost-effective, resource-constraint alternative solution to build a RAG-assisted Q\&A application on answering domain-specific queries in the field of experimental nuclear physics. This set-up facilitates data-privacy, avoids sending any pre-publication scientific data and information to public domain. Future improvement will expand the knowledge base to encompass heterogeneous EIC-related publications and reports and upgrade the application pipeline orchestration to the LangGraph framework.
Scalable AI-assisted Workflow Management for Detector Design Optimization Using Distributed Computing
Mar 31, 2026The Production and Distributed Analysis (PanDA) system, originally developed for the ATLAS experiment at the CERN Large Hadron Collider (LHC), has evolved into a robust platform for orchestrating large-scale workflows across distributed computing resources. Coupled with its intelligent Distributed Dispatch and Scheduling (iDDS) component, PanDA supports AI/ML-driven workflows through a scalable and flexible workflow engine. We present an AI-assisted framework for detector design optimization that integrates multi-objective Bayesian optimization with the PanDA--iDDS workflow engine to coordinate iterative simulations across heterogeneous resources. The framework addresses the challenge of exploring high-dimensional parameter spaces inherent in modern detector design. We demonstrate the framework using benchmark problems and realistic studies of the ePIC and dRICH detectors for the Electron-Ion Collider (EIC). Results show improved automation, scalability, and efficiency in multi-objective optimization. This work establishes a flexible and extensible paradigm for AI-driven detector design and other computationally intensive scientific applications.
Physics Event Classification Using Large Language Models
Apr 05, 2024The 2023 AI4EIC hackathon was the culmination of the third annual AI4EIC workshop at The Catholic University of America. This workshop brought together researchers from physics, data science and computer science to discuss the latest developments in Artificial Intelligence (AI) and Machine Learning (ML) for the Electron Ion Collider (EIC), including applications for detectors, accelerators, and experimental control. The hackathon, held on the final day of the workshop, involved using a chatbot powered by a Large Language Model, ChatGPT-3.5, to train a binary classifier neutrons and photons in simulated data from the \textsc{GlueX} Barrel Calorimeter. In total, six teams of up to four participants from all over the world took part in this intense educational and research event. This article highlights the hackathon challenge, the resources and methodology used, and the results and insights gained from analyzing physics data using the most cutting-edge tools in AI/ML.
Towards a RAG-based Summarization Agent for the Electron-Ion Collider
Mar 26, 2024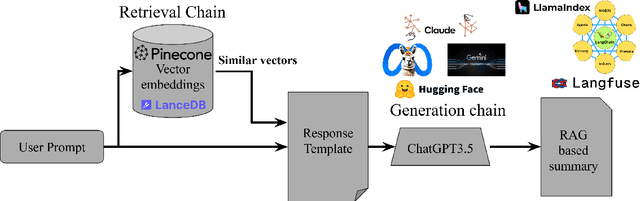
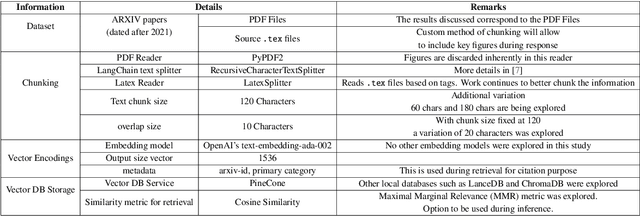
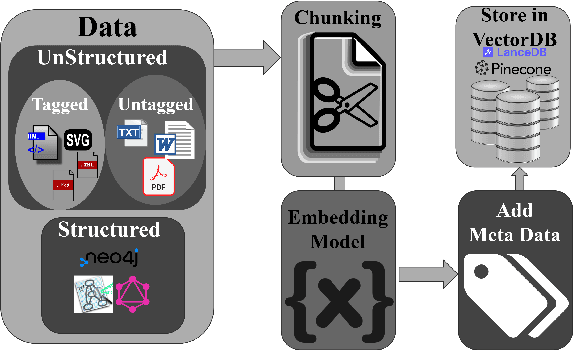

The complexity and sheer volume of information encompassing documents, papers, data, and other resources from large-scale experiments demand significant time and effort to navigate, making the task of accessing and utilizing these varied forms of information daunting, particularly for new collaborators and early-career scientists. To tackle this issue, a Retrieval Augmented Generation (RAG)--based Summarization AI for EIC (RAGS4EIC) is under development. This AI-Agent not only condenses information but also effectively references relevant responses, offering substantial advantages for collaborators. Our project involves a two-step approach: first, querying a comprehensive vector database containing all pertinent experiment information; second, utilizing a Large Language Model (LLM) to generate concise summaries enriched with citations based on user queries and retrieved data. We describe the evaluation methods that use RAG assessments (RAGAs) scoring mechanisms to assess the effectiveness of responses. Furthermore, we describe the concept of prompt template-based instruction-tuning which provides flexibility and accuracy in summarization. Importantly, the implementation relies on LangChain, which serves as the foundation of our entire workflow. This integration ensures efficiency and scalability, facilitating smooth deployment and accessibility for various user groups within the Electron Ion Collider (EIC) community. This innovative AI-driven framework not only simplifies the understanding of vast datasets but also encourages collaborative participation, thereby empowering researchers. As a demonstration, a web application has been developed to explain each stage of the RAG Agent development in detail.
XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence
Jun 16, 2022
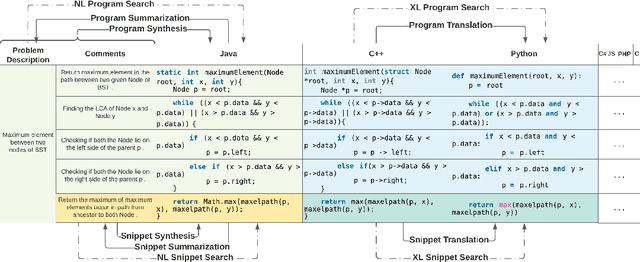
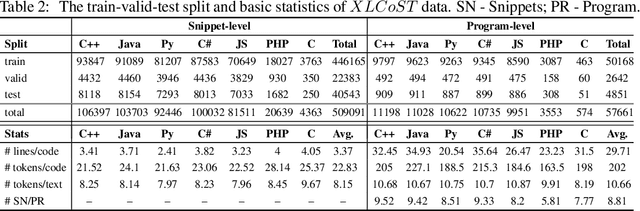
Recent advances in machine learning have significantly improved the understanding of source code data and achieved good performance on a number of downstream tasks. Open source repositories like GitHub enable this process with rich unlabeled code data. However, the lack of high quality labeled data has largely hindered the progress of several code related tasks, such as program translation, summarization, synthesis, and code search. This paper introduces XLCoST, Cross-Lingual Code SnippeT dataset, a new benchmark dataset for cross-lingual code intelligence. Our dataset contains fine-grained parallel data from 8 languages (7 commonly used programming languages and English), and supports 10 cross-lingual code tasks. To the best of our knowledge, it is the largest parallel dataset for source code both in terms of size and the number of languages. We also provide the performance of several state-of-the-art baseline models for each task. We believe this new dataset can be a valuable asset for the research community and facilitate the development and validation of new methods for cross-lingual code intelligence.
Delving into Robust Object Detection from Unmanned Aerial Vehicles: A Deep Nuisance Disentanglement Approach
Aug 11, 2019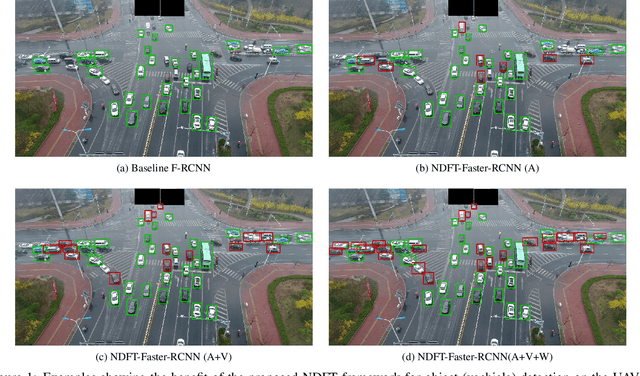
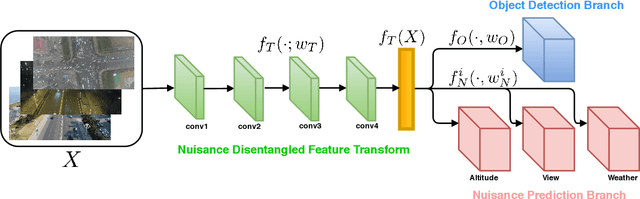


Object detection from images captured by Unmanned Aerial Vehicles (UAVs) is becoming increasingly useful. Despite the great success of the generic object detection methods trained on ground-to-ground images, a huge performance drop is observed when they are directly applied to images captured by UAVs. The unsatisfactory performance is owing to many UAV-specific nuisances, such as varying flying altitudes, adverse weather conditions, dynamically changing viewing angles, etc. Those nuisances constitute a large number of fine-grained domains, across which the detection model has to stay robust. Fortunately, UAVs will record meta-data that depict those varying attributes, which are either freely available along with the UAV images, or can be easily obtained. We propose to utilize those free meta-data in conjunction with associated UAV images to learn domain-robust features via an adversarial training framework dubbed Nuisance Disentangled Feature Transform (NDFT), for the specific challenging problem of object detection in UAV images, achieving a substantial gain in robustness to those nuisances. We demonstrate the effectiveness of our proposed algorithm, by showing state-of-the-art performance (single model) on two existing UAV-based object detection benchmarks. The code is available at https://github.com/TAMU-VITA/UAV-NDFT.