 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning pre-trained extractive QA models for clinical document parsing
Dec 04, 2023Electronic health records (EHRs) contain a vast amount of high-dimensional multi-modal data that can accurately represent a patient's medical history. Unfortunately, most of this data is either unstructured or semi-structured, rendering it unsuitable for real-time and retrospective analyses. A remote patient monitoring (RPM) program for Heart Failure (HF) patients needs to have access to clinical markers like EF (Ejection Fraction) or LVEF (Left Ventricular Ejection Fraction) in order to ascertain eligibility and appropriateness for the program. This paper explains a system that can parse echocardiogram reports and verify EF values. This system helps identify eligible HF patients who can be enrolled in such a program. At the heart of this system is a pre-trained extractive QA transformer model that is fine-tuned on custom-labeled data. The methods used to prepare such a model for deployment are illustrated by running experiments on a public clinical dataset like MIMIC-IV-Note. The pipeline can be used to generalize solutions to similar problems in a low-resource setting. We found that the system saved over 1500 hours for our clinicians over 12 months by automating the task at scale.
Execution-based Code Generation using Deep Reinforcement Learning
Feb 13, 2023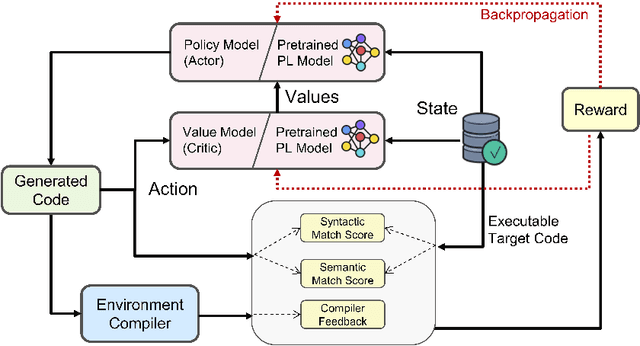
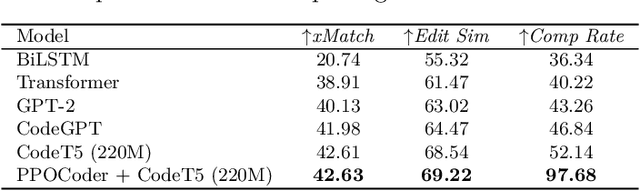
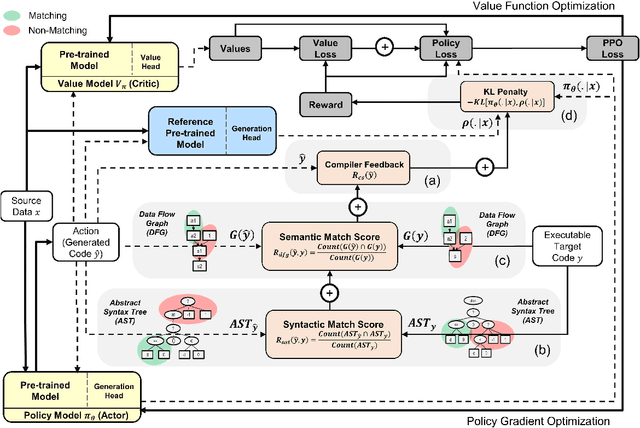
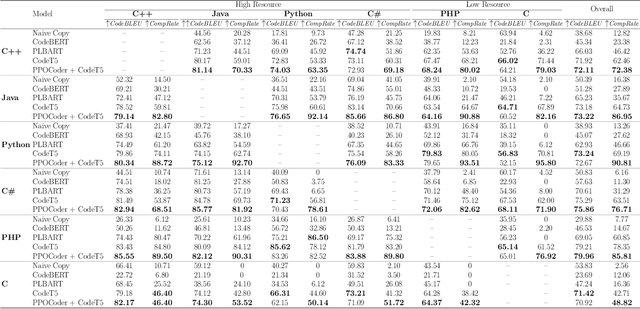
The utilization of programming language (PL) models, pretrained on large-scale code corpora, as a means of automating software engineering processes has demonstrated considerable potential in streamlining various code generation tasks such as code completion, code translation, and program synthesis. However, current approaches mainly rely on supervised fine-tuning objectives borrowed from text generation, neglecting specific sequence-level features of code, including but not limited to compilability as well as syntactic and functional correctness. To address this limitation, we propose PPOCoder, a new framework for code generation that combines pretrained PL models with Proximal Policy Optimization (PPO) deep reinforcement learning and employs execution feedback as the external source of knowledge into the model optimization. PPOCoder is transferable across different code generation tasks and PLs. Extensive experiments on three code generation tasks demonstrate the effectiveness of our proposed approach compared to SOTA methods, improving the success rate of compilation and functional correctness over different PLs. Our code can be found at https://github.com/reddy-lab-code-research/PPOCoder .
XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence
Jun 16, 2022
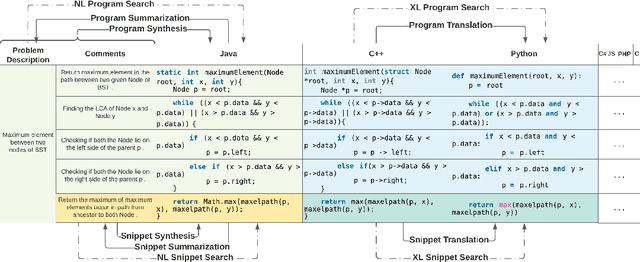
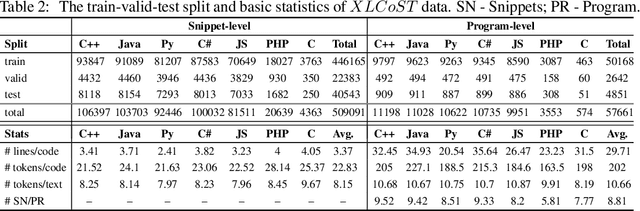
Recent advances in machine learning have significantly improved the understanding of source code data and achieved good performance on a number of downstream tasks. Open source repositories like GitHub enable this process with rich unlabeled code data. However, the lack of high quality labeled data has largely hindered the progress of several code related tasks, such as program translation, summarization, synthesis, and code search. This paper introduces XLCoST, Cross-Lingual Code SnippeT dataset, a new benchmark dataset for cross-lingual code intelligence. Our dataset contains fine-grained parallel data from 8 languages (7 commonly used programming languages and English), and supports 10 cross-lingual code tasks. To the best of our knowledge, it is the largest parallel dataset for source code both in terms of size and the number of languages. We also provide the performance of several state-of-the-art baseline models for each task. We believe this new dataset can be a valuable asset for the research community and facilitate the development and validation of new methods for cross-lingual code intelligence.