 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURFACEBENCH: Can Self-Evolving LLMs Find the Equations of 3D Scientific Surfaces?
Nov 13, 2025Equation discovery from data is a core challenge in machine learning for science, requiring the recovery of concise symbolic expressions that govern complex physical and geometric phenomena. Recent approaches with large language models (LLMs) show promise in symbolic regression, but their success often hinges on memorized formulas or overly simplified functional forms. Existing benchmarks exacerbate this limitation: they focus on scalar functions, ignore domain grounding, and rely on brittle string-matching based metrics that fail to capture scientific equivalence. We introduce SurfaceBench, first comprehensive benchmark for symbolic surface discovery. SurfaceBench comprises 183 tasks across 15 categories of symbolic complexity, spanning explicit, implicit, and parametric equation representation forms. Each task includes ground-truth equations, variable semantics, and synthetically sampled three dimensional data. Unlike prior SR datasets, our tasks reflect surface-level structure, resist LLM memorization through novel symbolic compositions, and are grounded in scientific domains such as fluid dynamics, robotics, electromagnetics, and geometry. To evaluate equation discovery quality, we pair symbolic checks with geometry-aware metrics such as Chamfer and Hausdorff distances, capturing both algebraic fidelity and spatial reconstruction accuracy. Our experiments reveal that state-of-the-art frameworks, while occasionally successful on specific families, struggle to generalize across representation types and surface complexities. SurfaceBench thus establishes a challenging and diagnostic testbed that bridges symbolic reasoning with geometric reconstruction, enabling principled benchmarking of progress in compositional generalization, data-driven scientific induction, and geometry-aware reasoning with LLMs. We release the code here: https://github.com/Sanchit-404/surfacebench
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Jun 07, 2025Recent generations of language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scaling properties, and limitations remain insufficiently understood. Current evaluations primarily focus on established math and coding benchmarks, emphasizing final answer accuracy. However, this evaluation paradigm often suffers from contamination and does not provide insights into the reasoning traces. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs think. Through extensive experiments, we show that LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counterintuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having remaining token budget. By comparing LRMs with their standard LLM counterparts under same inference compute, we identify three performance regimes: (1) low-complexity tasks where standard models outperform LRMs, (2) medium-complexity tasks where LRMs demonstrates advantage, and (3) high-complexity tasks where both models face complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across scales. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models' computational behavior, shedding light on their strengths, limitations, and raising questions about their reasoning capabilities.
LLM-SRBench: A New Benchmark for Scientific Equation Discovery with Large Language Models
Apr 14, 2025Scientific equation discovery is a fundamental task in the history of scientific progress, enabling the derivation of laws governing natural phenomena. Recently, Large Language Models (LLMs) have gained interest for this task due to their potential to leverage embedded scientific knowledge for hypothesis generation. However, evaluating the true discovery capabilities of these methods remains challenging, as existing benchmarks often rely on common equations that are susceptible to memorization by LLMs, leading to inflated performance metrics that do not reflect discovery. In this paper, we introduce LLM-SRBench, a comprehensive benchmark with 239 challenging problems across four scientific domains specifically designed to evaluate LLM-based scientific equation discovery methods while preventing trivial memorization. Our benchmark comprises two main categories: LSR-Transform, which transforms common physical models into less common mathematical representations to test reasoning beyond memorized forms, and LSR-Synth, which introduces synthetic, discovery-driven problems requiring data-driven reasoning. Through extensive evaluation of several state-of-the-art methods, using both open and closed LLMs, we find that the best-performing system so far achieves only 31.5% symbolic accuracy. These findings highlight the challenges of scientific equation discovery, positioning LLM-SRBench as a valuable resource for future research.
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Mar 18, 2025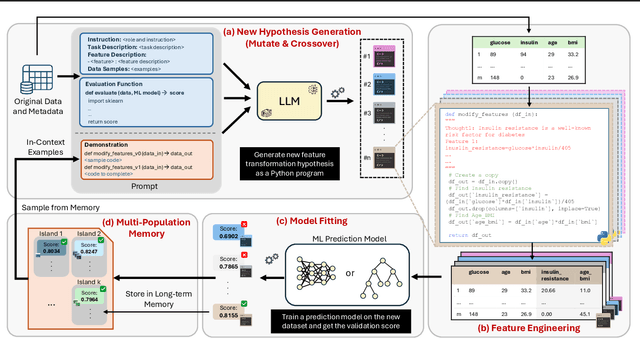

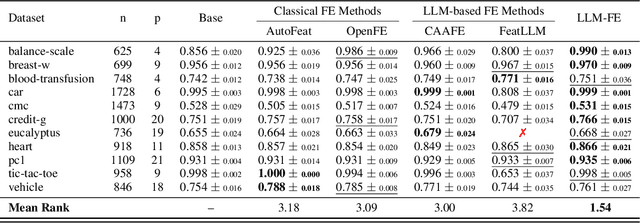
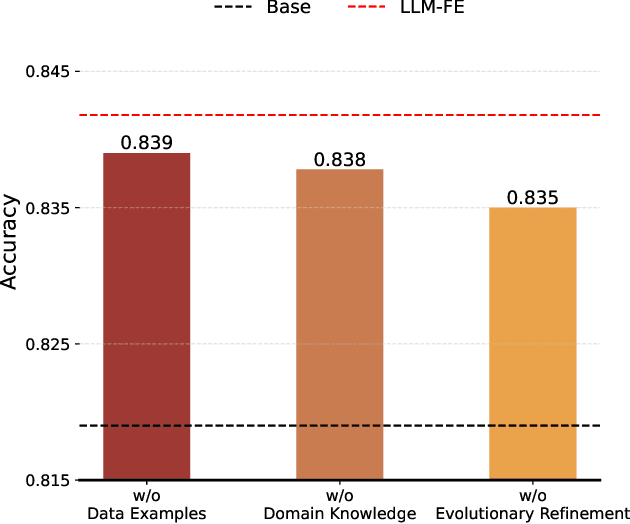
Automated feature engineering plays a critical role in improving predictive model performance for tabular learning tasks. Traditional automated feature engineering methods are limited by their reliance on pre-defined transformations within fixed, manually designed search spaces, often neglecting domain knowledge. Recent advances using Large Language Models (LLMs) have enabled the integration of domain knowledge into the feature engineering process. However, existing LLM-based approaches use direct prompting or rely solely on validation scores for feature selection, failing to leverage insights from prior feature discovery experiments or establish meaningful reasoning between feature generation and data-driven performance. To address these challenges, we propose LLM-FE, a novel framework that combines evolutionary search with the domain knowledge and reasoning capabilities of LLMs to automatically discover effective features for tabular learning tasks. LLM-FE formulates feature engineering as a program search problem, where LLMs propose new feature transformation programs iteratively, and data-driven feedback guides the search process. Our results demonstrate that LLM-FE consistently outperforms state-of-the-art baselines, significantly enhancing the performance of tabular prediction models across diverse classification and regression benchmarks.
Federated Retrieval Augmented Generation for Multi-Product Question Answering
Jan 25, 2025



Recent advancements in Large Language Models and Retrieval-Augmented Generation have boosted interest in domain-specific question-answering for enterprise products. However, AI Assistants often face challenges in multi-product QA settings, requiring accurate responses across diverse domains. Existing multi-domain RAG-QA approaches either query all domains indiscriminately, increasing computational costs and LLM hallucinations, or rely on rigid resource selection, which can limit search results. We introduce MKP-QA, a novel multi-product knowledge-augmented QA framework with probabilistic federated search across domains and relevant knowledge. This method enhances multi-domain search quality by aggregating query-domain and query-passage probabilistic relevance. To address the lack of suitable benchmarks for multi-product QAs, we also present new datasets focused on three Adobe products: Adobe Experience Platform, Target, and Customer Journey Analytics. Our experiments show that MKP-QA significantly boosts multi-product RAG-QA performance in terms of both retrieval accuracy and response quality.
Towards Scientific Discovery with Generative AI: Progress, Opportunities, and Challenges
Dec 16, 2024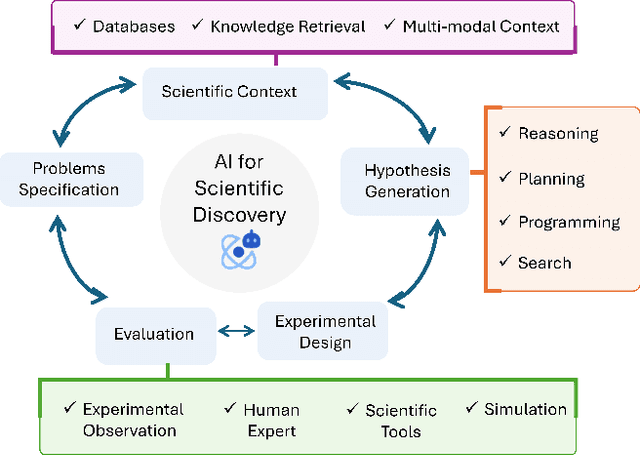
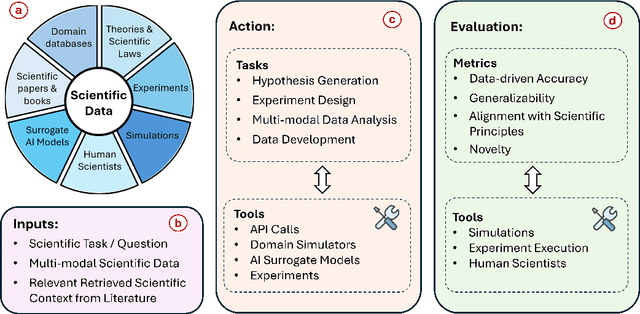
Scientific discovery is a complex cognitive process that has driven human knowledge and technological progress for centuries. While artificial intelligence (AI) has made significant advances in automating aspects of scientific reasoning, simulation, and experimentation, we still lack integrated AI systems capable of performing autonomous long-term scientific research and discovery. This paper examines the current state of AI for scientific discovery, highlighting recent progress in large language models and other AI techniques applied to scientific tasks. We then outline key challenges and promising research directions toward developing more comprehensive AI systems for scientific discovery, including the need for science-focused AI agents, improved benchmarks and evaluation metrics, multimodal scientific representations, and unified frameworks combining reasoning, theorem proving, and data-driven modeling. Addressing these challenges could lead to transformative AI tools to accelerate progress across disciplines towards scientific discovery.
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models
Apr 29, 2024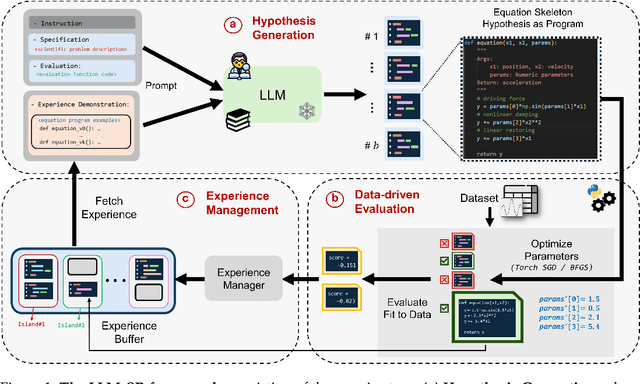
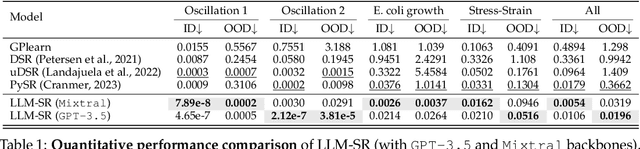

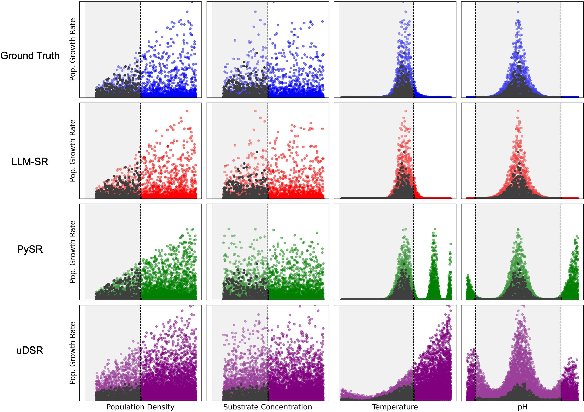
Mathematical equations have been unreasonably effective in describing complex natural phenomena across various scientific disciplines. However, discovering such insightful equations from data presents significant challenges due to the necessity of navigating extremely high-dimensional combinatorial and nonlinear hypothesis spaces. Traditional methods of equation discovery largely focus on extracting equations from data alone, often neglecting the rich domain-specific prior knowledge that scientists typically depend on. To bridge this gap, we introduce LLM-SR, a novel approach that leverages the extensive scientific knowledge and robust code generation capabilities of Large Language Models (LLMs) to discover scientific equations from data in an efficient manner. Specifically, LLM-SR treats equations as programs with mathematical operators and combines LLMs' scientific priors with evolutionary search over equation programs. The LLM iteratively proposes new equation skeletons, drawing from its physical understanding, which are then optimized against data to estimate skeleton parameters. We demonstrate LLM-SR's effectiveness across three diverse scientific domains, where it discovers physically accurate equations that provide significantly better fits to in-domain and out-of-domain data compared to the well-established equation discovery baselines
SNIP: Bridging Mathematical Symbolic and Numeric Realms with Unified Pre-training
Oct 19, 2023
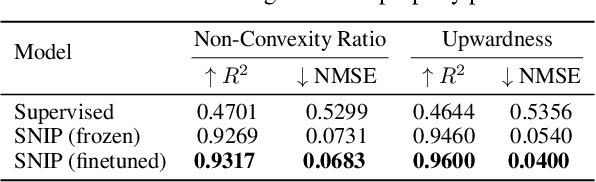
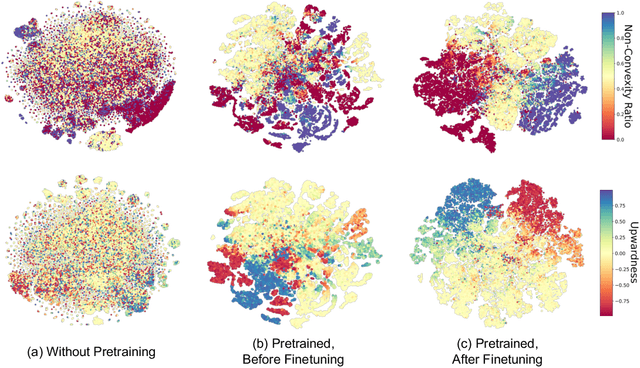
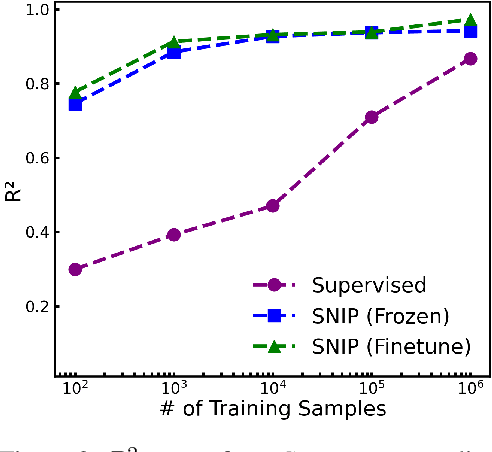
In an era where symbolic mathematical equations are indispensable for modeling complex natural phenomena, scientific inquiry often involves collecting observations and translating them into mathematical expressions. Recently, deep learning has emerged as a powerful tool for extracting insights from data. However, existing models typically specialize in either numeric or symbolic domains, and are usually trained in a supervised manner tailored to specific tasks. This approach neglects the substantial benefits that could arise from a task-agnostic unified understanding between symbolic equations and their numeric counterparts. To bridge the gap, we introduce SNIP, a Symbolic-Numeric Integrated Pre-training, which employs joint contrastive learning between symbolic and numeric domains, enhancing their mutual similarities in the pre-trained embeddings. By performing latent space analysis, we observe that SNIP provides cross-domain insights into the representations, revealing that symbolic supervision enhances the embeddings of numeric data and vice versa. We evaluate SNIP across diverse tasks, including symbolic-to-numeric mathematical property prediction and numeric-to-symbolic equation discovery, commonly known as symbolic regression. Results show that SNIP effectively transfers to various tasks, consistently outperforming fully supervised baselines and competing strongly with established task-specific methods, especially in few-shot learning scenarios where available data is limited.
Graph-based Multi-ODE Neural Networks for Spatio-Temporal Traffic Forecasting
Jun 01, 2023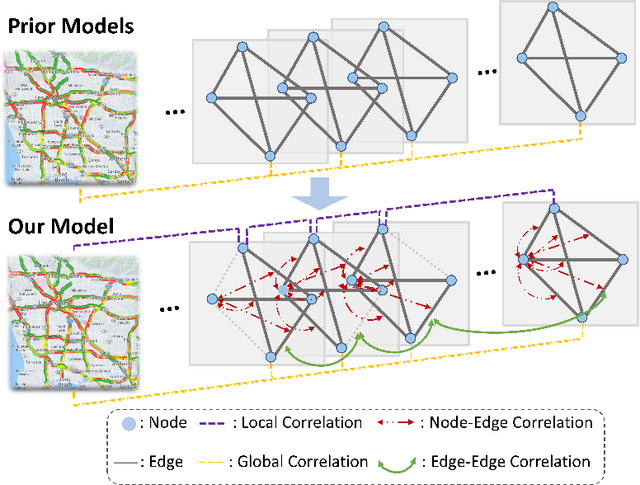
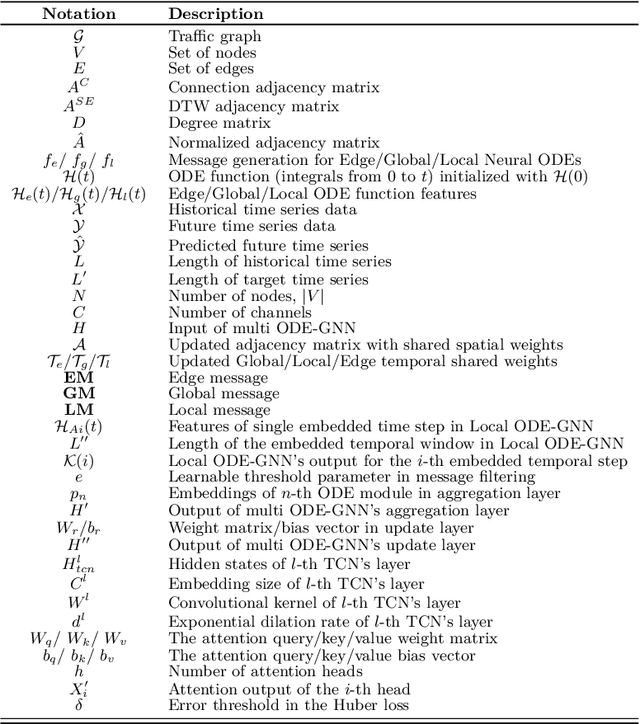
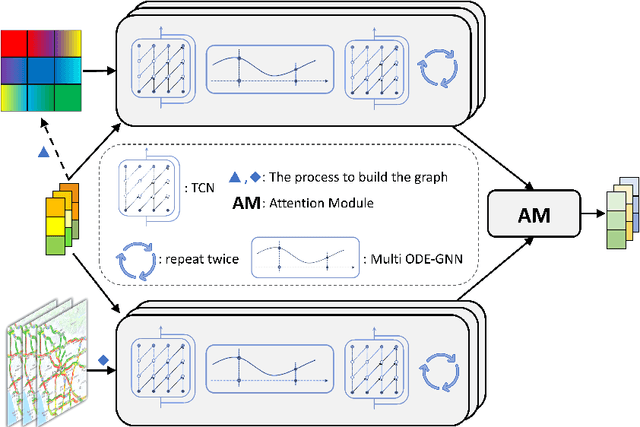
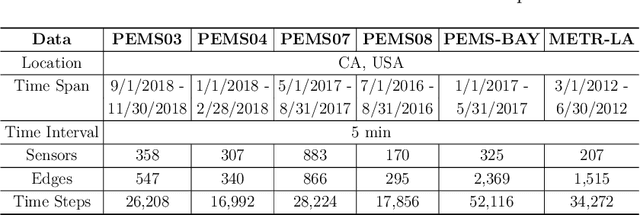
There is a recent surge in the development of spatio-temporal forecasting models in the transportation domain. Long-range traffic forecasting, however, remains a challenging task due to the intricate and extensive spatio-temporal correlations observed in traffic networks. Current works primarily rely on road networks with graph structures and learn representations using graph neural networks (GNNs), but this approach suffers from over-smoothing problem in deep architectures. To tackle this problem, recent methods introduced the combination of GNNs with residual connections or neural ordinary differential equations (ODE). However, current graph ODE models face two key limitations in feature extraction: (1) they lean towards global temporal patterns, overlooking local patterns that are important for unexpected events; and (2) they lack dynamic semantic edges in their architectural design. In this paper, we propose a novel architecture called Graph-based Multi-ODE Neural Networks (GRAM-ODE) which is designed with multiple connective ODE-GNN modules to learn better representations by capturing different views of complex local and global dynamic spatio-temporal dependencies. We also add some techniques like shared weights and divergence constraints into the intermediate layers of distinct ODE-GNN modules to further improve their communication towards the forecasting task. Our extensive set of experiments conducted on six real-world datasets demonstrate the superior performance of GRAM-ODE compared with state-of-the-art baselines as well as the contribution of different components to the overall performance. The code is available at https://github.com/zbliu98/GRAM-ODE
* Published in Transactions on Machine Learning Research, 2023
Transformer-based Planning for Symbolic Regression
Mar 16, 2023



Symbolic regression (SR) is a challenging task in machine learning that involves finding a mathematical expression for a function based on its values. Recent advancements in SR have demonstrated the efficacy of pretrained transformer-based models for generating equations as sequences, which benefit from large-scale pretraining on synthetic datasets and offer considerable advantages over GP-based methods in terms of inference time. However, these models focus on supervised pretraining goals borrowed from text generation and ignore equation-specific objectives like accuracy and complexity. To address this, we propose TPSR, a Transformer-based Planning strategy for Symbolic Regression that incorporates Monte Carlo Tree Search into the transformer decoding process. TPSR, as opposed to conventional decoding strategies, allows for the integration of non-differentiable feedback, such as fitting accuracy and complexity, as external sources of knowledge into the equation generation process. Extensive experiments on various datasets show that our approach outperforms state-of-the-art methods, enhancing the model's fitting-complexity trade-off, extrapolation abilities, and robustness to noise. We also demonstrate that the utilization of various caching mechanisms can further enhance the efficiency of TPSR.