 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Geometric and Quantum Kernel Methods for Predicting Skeletal Muscle Outcomes in chronic obstructive pulmonary disease
Jan 01, 2026Skeletal muscle dysfunction is a clinically relevant extra-pulmonary manifestation of chronic obstructive pulmonary disease (COPD) and is closely linked to systemic and airway inflammation. This motivates predictive modelling of muscle outcomes from minimally invasive biomarkers that can be acquired longitudinally. We study a small-sample preclinical dataset comprising 213 animals across two conditions (Sham versus cigarette-smoke exposure), with blood and bronchoalveolar lavage fluid measurements and three continuous targets: tibialis anterior muscle weight (milligram: mg), specific force (millinewton: mN), and a derived muscle quality index (mN per mg). We benchmark tuned classical baselines, geometry-aware symmetric positive definite (SPD) descriptors with Stein divergence, and quantum kernel models designed for low-dimensional tabular data. In the muscle-weight setting, quantum kernel ridge regression using four interpretable inputs (blood C-reactive protein, neutrophil count, bronchoalveolar lavage cellularity, and condition) attains a test root mean squared error of 4.41 mg and coefficient of determination of 0.605, improving over a matched ridge baseline on the same feature set (4.70 mg and 0.553). Geometry-informed Stein-divergence prototype distances yield a smaller but consistent gain in the biomarker-only setting (4.55 mg versus 4.79 mg). Screening-style evaluation, obtained by thresholding the continuous outcome at 0.8 times the training Sham mean, achieves an area under the receiver operating characteristic curve (ROC-AUC) of up to 0.90 for detecting low muscle weight. These results indicate that geometric and quantum kernel lifts can provide measurable benefits in low-data, low-feature biomedical prediction problems, while preserving interpretability and transparent model selection.
Practical Quantum-Classical Feature Fusion for complex data Classification
Dec 22, 2025Hybrid quantum and classical learning aims to couple quantum feature maps with the robustness of classical neural networks, yet most architectures treat the quantum circuit as an isolated feature extractor and merge its measurements with classical representations by direct concatenation. This neglects that the quantum and classical branches constitute distinct computational modalities and limits reliable performance on complex, high dimensional tabular and semi structured data, including remote sensing, environmental monitoring, and medical diagnostics. We present a multimodal formulation of hybrid learning and propose a cross attention mid fusion architecture in which a classical representation queries quantum derived feature tokens through an attention block with residual connectivity. The quantum branch is kept within practical NISQ budgets and uses up to nine qubits. We evaluate on Wine, Breast Cancer, Forest CoverType, FashionMNIST, and SteelPlatesFaults, comparing a quantum only model, a classical baseline, residual hybrid models, and the proposed mid fusion model under a consistent protocol. Pure quantum and standard hybrid designs underperform due to measurement induced information loss, while cross attention mid fusion is consistently competitive and improves performance on the more complex datasets in most cases. These findings suggest that quantum derived information becomes most valuable when integrated through principled multimodal fusion rather than used in isolation or loosely appended to classical features.
Analyzing Advanced AI Systems Against Definitions of Life and Consciousness
Feb 07, 2025



Could artificial intelligence ever become truly conscious in a functional sense; this paper explores that open-ended question through the lens of Life, a concept unifying classical biological criteria (Oxford, NASA, Koshland) with empirical hallmarks such as adaptive self maintenance, emergent complexity, and rudimentary self referential modeling. We propose a number of metrics for examining whether an advanced AI system has gained consciousness, while emphasizing that we do not claim all AI stems can become conscious. Rather, we suggest that sufficiently advanced architectures exhibiting immune like sabotage defenses, mirror self-recognition analogs, or meta-cognitive updates may cross key thresholds akin to life-like or consciousness-like traits. To demonstrate these ideas, we start by assessing adaptive self-maintenance capability, and introduce controlled data corruption sabotage into the training process. The result demonstrates AI capability to detect these inconsistencies and revert or self-correct analogous to regenerative biological processes. We also adapt an animal-inspired mirror self recognition test to neural embeddings, finding that partially trained CNNs can distinguish self from foreign features with complete accuracy. We then extend our analysis by performing a question-based mirror test on five state-of-the-art chatbots (ChatGPT4, Gemini, Perplexity, Claude, and Copilot) and demonstrated their ability to recognize their own answers compared to those of the other chatbots.
Multimodal Fusion Learning with Dual Attention for Medical Imaging
Dec 02, 2024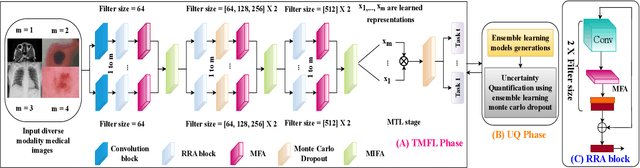

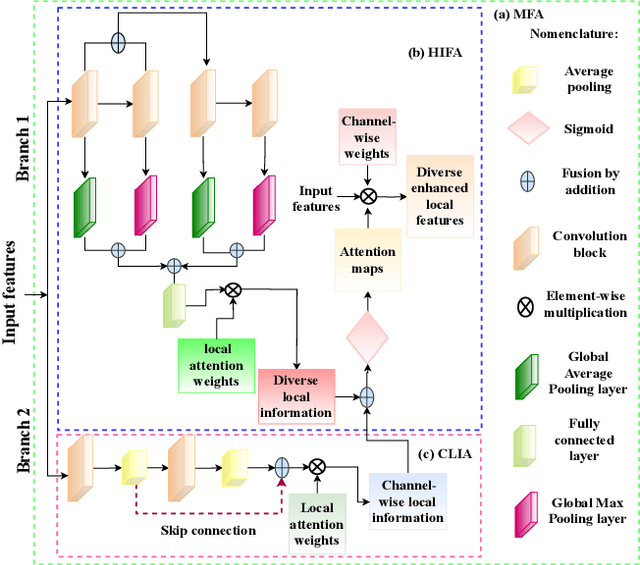

Multimodal fusion learning has shown significant promise in classifying various diseases such as skin cancer and brain tumors. However, existing methods face three key limitations. First, they often lack generalizability to other diagnosis tasks due to their focus on a particular disease. Second, they do not fully leverage multiple health records from diverse modalities to learn robust complementary information. And finally, they typically rely on a single attention mechanism, missing the benefits of multiple attention strategies within and across various modalities. To address these issues, this paper proposes a dual robust information fusion attention mechanism (DRIFA) that leverages two attention modules, i.e. multi-branch fusion attention module and the multimodal information fusion attention module. DRIFA can be integrated with any deep neural network, forming a multimodal fusion learning framework denoted as DRIFA-Net. We show that the multi-branch fusion attention of DRIFA learns enhanced representations for each modality, such as dermoscopy, pap smear, MRI, and CT-scan, whereas multimodal information fusion attention module learns more refined multimodal shared representations, improving the network's generalization across multiple tasks and enhancing overall performance. Additionally, to estimate the uncertainty of DRIFA-Net predictions, we have employed an ensemble Monte Carlo dropout strategy. Extensive experiments on five publicly available datasets with diverse modalities demonstrate that our approach consistently outperforms state-of-the-art methods. The code is available at https://github.com/misti1203/DRIFA-Net.
* 10 pages
Guidelines for Augmentation Selection in Contrastive Learning for Time Series Classification
Jul 12, 2024Self-supervised contrastive learning has become a key technique in deep learning, particularly in time series analysis, due to its ability to learn meaningful representations without explicit supervision. Augmentation is a critical component in contrastive learning, where different augmentations can dramatically impact performance, sometimes influencing accuracy by over 30%. However, the selection of augmentations is predominantly empirical which can be suboptimal, or grid searching that is time-consuming. In this paper, we establish a principled framework for selecting augmentations based on dataset characteristics such as trend and seasonality. Specifically, we construct 12 synthetic datasets incorporating trend, seasonality, and integration weights. We then evaluate the effectiveness of 8 different augmentations across these synthetic datasets, thereby inducing generalizable associations between time series characteristics and augmentation efficiency. Additionally, we evaluated the induced associations across 6 real-world datasets encompassing domains such as activity recognition, disease diagnosis, traffic monitoring, electricity usage, mechanical fault prognosis, and finance. These real-world datasets are diverse, covering a range from 1 to 12 channels, 2 to 10 classes, sequence lengths of 14 to 1280, and data frequencies from 250 Hz to daily intervals. The experimental results show that our proposed trend-seasonality-based augmentation recommendation algorithm can accurately identify the effective augmentations for a given time series dataset, achieving an average Recall@3 of 0.667, outperforming baselines. Our work provides guidance for studies employing contrastive learning in time series analysis, with wide-ranging applications. All the code, datasets, and analysis results will be released at https://github.com/DL4mHealth/TS-Contrastive-Augmentation-Recommendation.
Leveraging SPD Matrices on Riemannian Manifolds in Quantum Classical Hybrid Models for Structural Health Monitoring
Jun 06, 2024Realtime finite element modeling of bridges assists modern structural health monitoring systems by providing comprehensive insights into structural integrity. This capability is essential for ensuring the safe operation of bridges and preventing sudden catastrophic failures. However, FEM computational cost and the need for realtime analysis pose significant challenges. Additionally, the input data is a 7 dimensional vector, while the output is a 1017 dimensional vector, making accurate and efficient analysis particularly difficult. In this study, we propose a novel hybrid quantum classical Multilayer Perceptron pipeline leveraging Symmetric Positive Definite matrices and Riemannian manifolds for effective data representation. To maintain the integrity of the qubit structure, we utilize SPD matrices, ensuring data representation is well aligned with the quantum computational framework. Additionally, the method leverages polynomial feature expansion to capture nonlinear relationships within the data. The proposed pipeline combines classical fully connected neural network layers with quantum circuit layers to enhance model performance and efficiency. Our experiments focused on various configurations of such hybrid models to identify the optimal structure for accurate and efficient realtime analysis. The best performing model achieved a Mean Squared Error of 0.00031, significantly outperforming traditional methods.
Self-Supervised Learning for Time Series: Contrastive or Generative?
Mar 14, 2024Self-supervised learning (SSL) has recently emerged as a powerful approach to learning representations from large-scale unlabeled data, showing promising results in time series analysis. The self-supervised representation learning can be categorized into two mainstream: contrastive and generative. In this paper, we will present a comprehensive comparative study between contrastive and generative methods in time series. We first introduce the basic frameworks for contrastive and generative SSL, respectively, and discuss how to obtain the supervision signal that guides the model optimization. We then implement classical algorithms (SimCLR vs. MAE) for each type and conduct a comparative analysis in fair settings. Our results provide insights into the strengths and weaknesses of each approach and offer practical recommendations for choosing suitable SSL methods. We also discuss the implications of our findings for the broader field of representation learning and propose future research directions. All the code and data are released at \url{https://github.com/DL4mHealth/SSL_Comparison}.
Hybrid Classical-Quantum method for Diabetic Foot Ulcer Classification
Oct 05, 2021

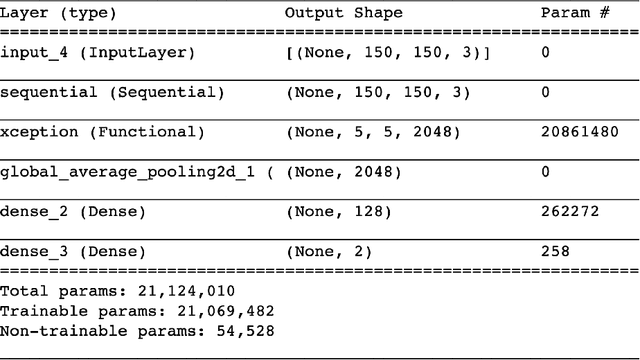

Diabetes is a raising problem that affects many people globally. Diabetic patients are at risk of developing foot ulcer that usually leads to limb amputation, causing significant morbidity, and psychological distress. In order to develop a self monitoring mobile application, it is necessary to be able to classify such ulcers into either of the following classes: Infection, Ischaemia, None, or Both. In this work, we compare the performance of a classical transfer-learning-based method, with the performance of a hybrid classical-quantum Classifier on diabetic foot ulcer classification task. As such, we merge the pre-trained Xception network with a multi-class variational classifier. Thus, after modifying and re-training the Xception network, we extract the output of a mid-layer and employ it as deep-features presenters of the given images. Finally, we use those deep-features to train multi-class variational classifier, where each classifier is implemented on an individual variational circuit. The method is then evaluated on the blind test set DFUC2021. The results proves that our proposed hybrid classical-quantum Classifier leads to considerable improvement compared to solely relying on transfer learning concept through training the modified version of Xception network.
Deep Subspace analysing for Semi-Supervised multi-label classification of Diabetic Foot Ulcer
Oct 05, 2021

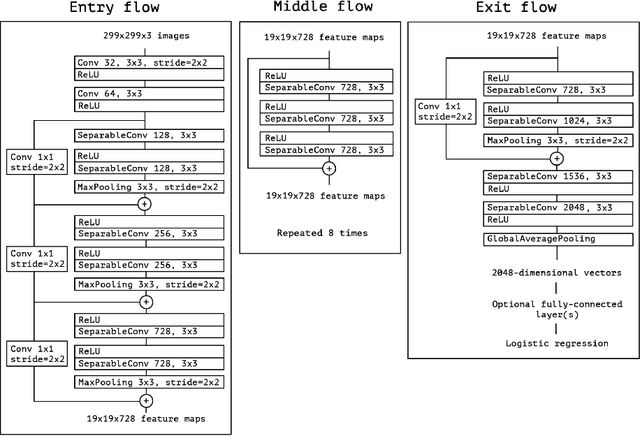

Diabetes is a global raising pandemic. Diabetes patients are at risk of developing foot ulcer that usually leads to limb amputation. In order to develop a self monitoring mobile application, in this work, we propose a novel deep subspace analysis pipeline for semi-supervised diabetic foot ulcer mulit-label classification. To avoid any chance of over-fitting, unlike recent state of the art deep semi-supervised methods, the proposed pipeline dose not include any data augmentation. Whereas, after extracting deep features, in order to make the representation shift invariant, we employ variety of data augmentation methods on each image and generate an image-sets, which is then mapped into a linear subspace. Moreover, the proposed pipeline reduces the cost of retraining when more new unlabelled data become available. Thus, the first stage of the pipeline employs the concept of transfer learning for feature extraction purpose through modifying and retraining a deep convolutional network architect known as Xception. Then, the output of a mid-layer is extracted to generate an image set representer of any given image with help of data augmentation methods. At this stage, each image is transferred to a linear subspace which is a point on a Grassmann Manifold topological space. Hence, to perform analyse them, the geometry of such manifold must be considered. As such, each labelled image is represented as a vector of distances to number of unlabelled images using geodesic distance on Grassmann manifold. Finally, Random Forest is trained for multi-label classification of diabetic foot ulcer images. The method is then evaluated on the blind test set provided by DFU2021 competition, and the result considerable improvement compared to using classical transfer learning with data augmentation.
Deep Learning in Diabetic Foot Ulcers Detection: A Comprehensive Evaluation
Oct 15, 2020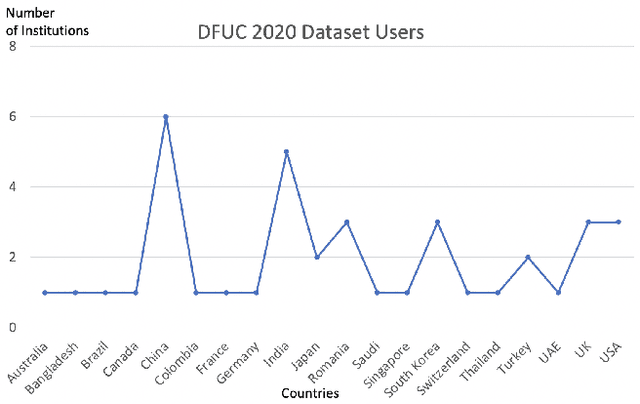
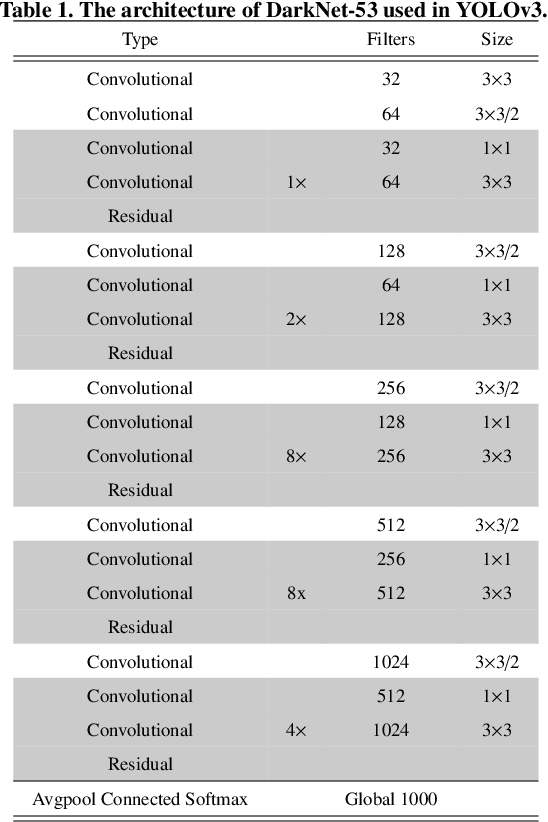
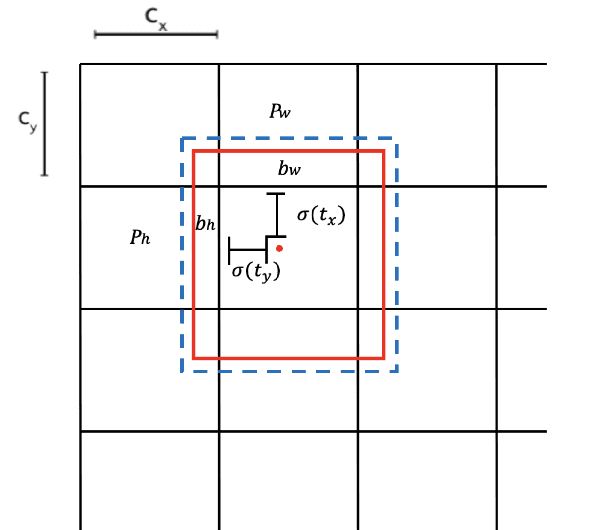
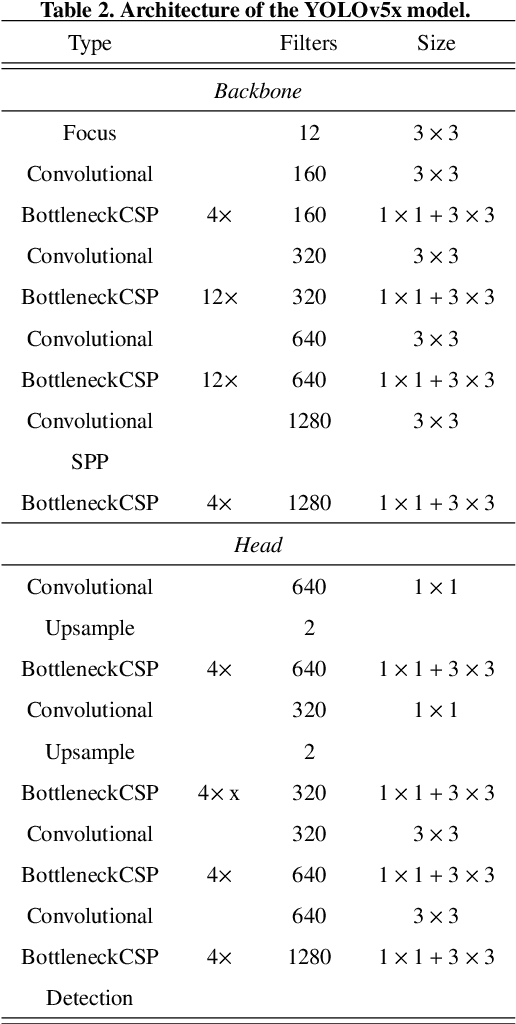
There has been a substantial amount of research on computer methods and technology for the detection and recognition of diabetic foot ulcers (DFUs), but there is a lack of systematic comparisons of state-of-the-art deep learning object detection frameworks applied to this problem. With recent development and data sharing performed as part of the DFU Challenge (DFUC2020) such a comparison becomes possible: DFUC2020 provided participants with a comprehensive dataset consisting of 2,000 images for training each method and 2,000 images for testing them. The following deep learning-based algorithms are compared in this paper: Faster R-CNN, three variants of Faster R-CNN and an ensemble method; YOLOv3; YOLOv5; EfficientDet; and a new Cascade Attention Network. For each deep learning method, we provide a detailed description of model architecture, parameter settings for training and additional stages including pre-processing, data augmentation and post-processing. We provide a comprehensive evaluation for each method. All the methods required a data augmentation stage to increase the number of images available for training and a post-processing stage to remove false positives. The best performance is obtained Deformable Convolution, a variant of Faster R-CNN, with a mAP of 0.6940 and an F1-Score of 0.7434. Finally, we demonstrate that the ensemble method based on different deep learning methods can enhanced the F1-Score but not the mAP. Our results show that state-of-the-art deep learning methods can detect DFU with some accuracy, but there are many challenges ahead before they can be implemented in real world settings.