 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidelines for Augmentation Selection in Contrastive Learning for Time Series Classification
Jul 12, 2024Self-supervised contrastive learning has become a key technique in deep learning, particularly in time series analysis, due to its ability to learn meaningful representations without explicit supervision. Augmentation is a critical component in contrastive learning, where different augmentations can dramatically impact performance, sometimes influencing accuracy by over 30%. However, the selection of augmentations is predominantly empirical which can be suboptimal, or grid searching that is time-consuming. In this paper, we establish a principled framework for selecting augmentations based on dataset characteristics such as trend and seasonality. Specifically, we construct 12 synthetic datasets incorporating trend, seasonality, and integration weights. We then evaluate the effectiveness of 8 different augmentations across these synthetic datasets, thereby inducing generalizable associations between time series characteristics and augmentation efficiency. Additionally, we evaluated the induced associations across 6 real-world datasets encompassing domains such as activity recognition, disease diagnosis, traffic monitoring, electricity usage, mechanical fault prognosis, and finance. These real-world datasets are diverse, covering a range from 1 to 12 channels, 2 to 10 classes, sequence lengths of 14 to 1280, and data frequencies from 250 Hz to daily intervals. The experimental results show that our proposed trend-seasonality-based augmentation recommendation algorithm can accurately identify the effective augmentations for a given time series dataset, achieving an average Recall@3 of 0.667, outperforming baselines. Our work provides guidance for studies employing contrastive learning in time series analysis, with wide-ranging applications. All the code, datasets, and analysis results will be released at https://github.com/DL4mHealth/TS-Contrastive-Augmentation-Recommendation.
Self-Supervised Learning for Time Series: Contrastive or Generative?
Mar 14, 2024Self-supervised learning (SSL) has recently emerged as a powerful approach to learning representations from large-scale unlabeled data, showing promising results in time series analysis. The self-supervised representation learning can be categorized into two mainstream: contrastive and generative. In this paper, we will present a comprehensive comparative study between contrastive and generative methods in time series. We first introduce the basic frameworks for contrastive and generative SSL, respectively, and discuss how to obtain the supervision signal that guides the model optimization. We then implement classical algorithms (SimCLR vs. MAE) for each type and conduct a comparative analysis in fair settings. Our results provide insights into the strengths and weaknesses of each approach and offer practical recommendations for choosing suitable SSL methods. We also discuss the implications of our findings for the broader field of representation learning and propose future research directions. All the code and data are released at \url{https://github.com/DL4mHealth/SSL_Comparison}.
An Efficient Protocol for Negotiation over Combinatorial Domains with Incomplete Information
Feb 14, 2012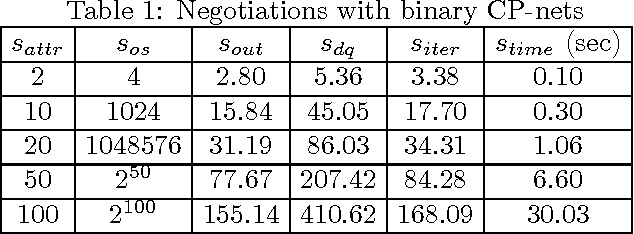
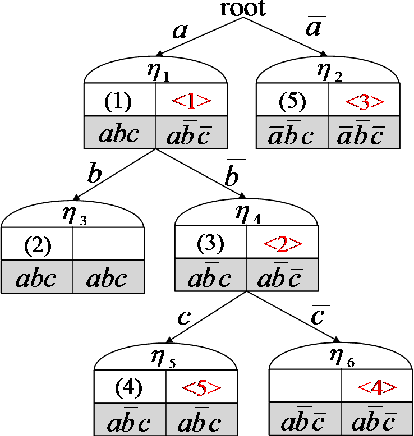
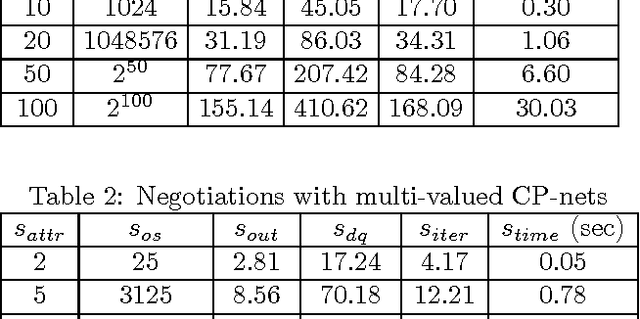

We study the problem of agent-based negotiation in combinatorial domains. It is difficult to reach optimal agreements in bilateral or multi-lateral negotiations when the agents' preferences for the possible alternatives are not common knowledge. Self-interested agents often end up negotiating inefficient agreements in such situations. In this paper, we present a protocol for negotiation in combinatorial domains which can lead rational agents to reach optimal agreements under incomplete information setting. Our proposed protocol enables the negotiating agents to identify efficient solutions using distributed search that visits only a small subspace of the whole outcome space. Moreover, the proposed protocol is sufficiently general that it is applicable to most preference representation models in combinatorial domains. We also present results of experiments that demonstrate the feasibility and computational efficiency of our approach.