 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinutiae-Guided Fingerprint Embeddings via Vision Transformers
Oct 26, 2022
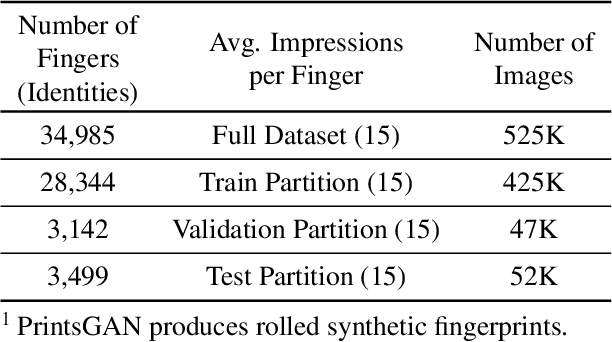


Minutiae matching has long dominated the field of fingerprint recognition. However, deep networks can be used to extract fixed-length embeddings from fingerprints. To date, the few studies that have explored the use of CNN architectures to extract such embeddings have shown extreme promise. Inspired by these early works, we propose the first use of a Vision Transformer (ViT) to learn a discriminative fixed-length fingerprint embedding. We further demonstrate that by guiding the ViT to focus in on local, minutiae related features, we can boost the recognition performance. Finally, we show that by fusing embeddings learned by CNNs and ViTs we can reach near parity with a commercial state-of-the-art (SOTA) matcher. In particular, we obtain a TAR=94.23% @ FAR=0.1% on the NIST SD 302 public-domain dataset, compared to a SOTA commercial matcher which obtains TAR=96.71% @ FAR=0.1%. Additionally, our fixed-length embeddings can be matched orders of magnitude faster than the commercial system (2.5 million matches/second compared to 50K matches/second). We make our code and models publicly available to encourage further research on this topic: https://github.com/tba.
PseudoProp: Robust Pseudo-Label Generation for Semi-Supervised Object Detection in Autonomous Driving Systems
Mar 11, 2022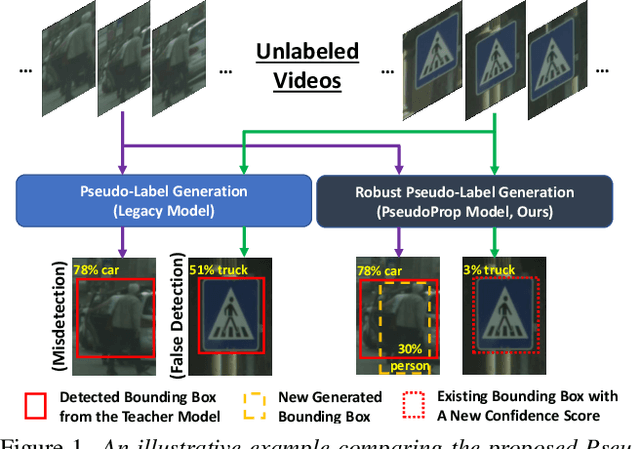
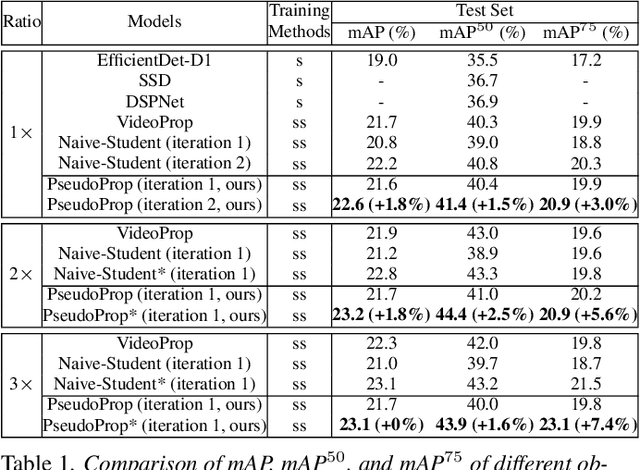
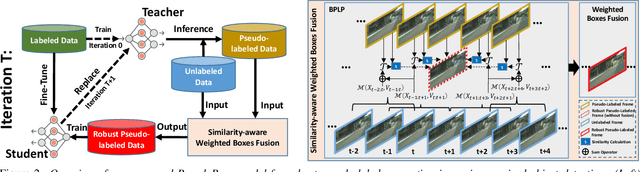
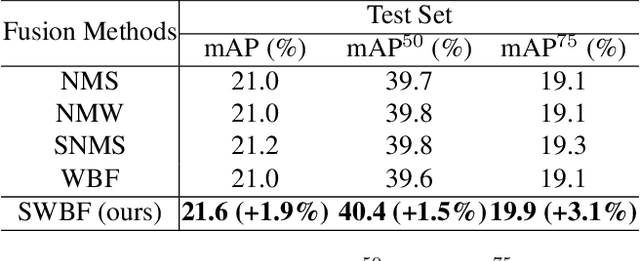
Semi-supervised object detection methods are widely used in autonomous driving systems, where only a fraction of objects are labeled. To propagate information from the labeled objects to the unlabeled ones, pseudo-labels for unlabeled objects must be generated. Although pseudo-labels have proven to improve the performance of semi-supervised object detection significantly, the applications of image-based methods to video frames result in numerous miss or false detections using such generated pseudo-labels. In this paper, we propose a new approach, PseudoProp, to generate robust pseudo-labels by leveraging motion continuity in video frames. Specifically, PseudoProp uses a novel bidirectional pseudo-label propagation approach to compensate for misdetection. A feature-based fusion technique is also used to suppress inference noise. Extensive experiments on the large-scale Cityscapes dataset demonstrate that our method outperforms the state-of-the-art semi-supervised object detection methods by 7.4% on mAP75.
Deep Symbolic Representation Learning for Heterogeneous Time-series Classification
Dec 05, 2016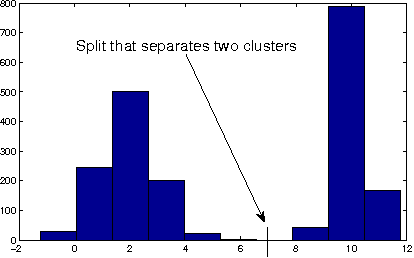

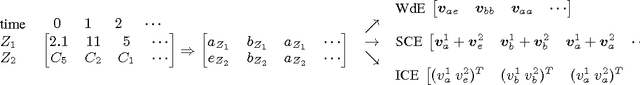

In this paper, we consider the problem of event classification with multi-variate time series data consisting of heterogeneous (continuous and categorical) variables. The complex temporal dependencies between the variables combined with sparsity of the data makes the event classification problem particularly challenging. Most state-of-art approaches address this either by designing hand-engineered features or breaking up the problem over homogeneous variates. In this work, we propose and compare three representation learning algorithms over symbolized sequences which enables classification of heterogeneous time-series data using a deep architecture. The proposed representations are trained jointly along with the rest of the network architecture in an end-to-end fashion that makes the learned features discriminative for the given task. Experiments on three real-world datasets demonstrate the effectiveness of the proposed approaches.
Universum Learning for Multiclass SVM
Sep 29, 2016

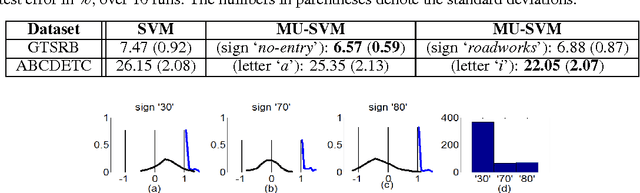

We introduce Universum learning for multiclass problems and propose a novel formulation for multiclass universum SVM (MU-SVM). We also propose a span bound for MU-SVM that can be used for model selection thereby avoiding resampling. Empirical results demonstrate the effectiveness of MU-SVM and the proposed bound.
Comparative Study of Deep Learning Software Frameworks
Mar 30, 2016

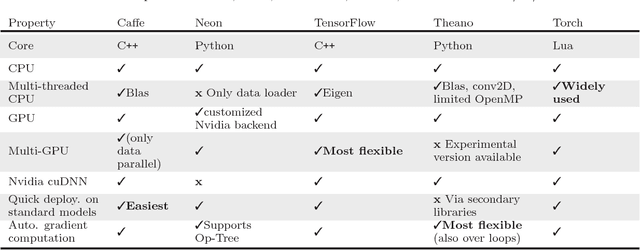
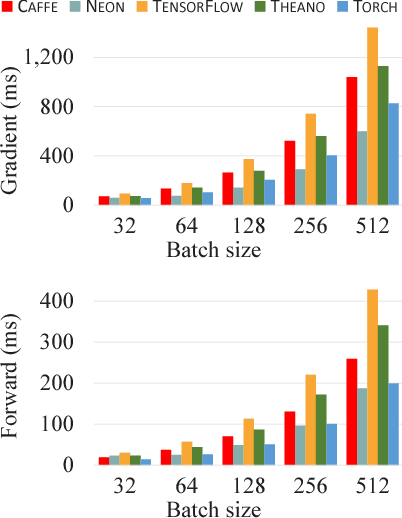
Deep learning methods have resulted in significant performance improvements in several application domains and as such several software frameworks have been developed to facilitate their implementation. This paper presents a comparative study of five deep learning frameworks, namely Caffe, Neon, TensorFlow, Theano, and Torch, on three aspects: extensibility, hardware utilization, and speed. The study is performed on several types of deep learning architectures and we evaluate the performance of the above frameworks when employed on a single machine for both (multi-threaded) CPU and GPU (Nvidia Titan X) settings. The speed performance metrics used here include the gradient computation time, which is important during the training phase of deep networks, and the forward time, which is important from the deployment perspective of trained networks. For convolutional networks, we also report how each of these frameworks support various convolutional algorithms and their corresponding performance. From our experiments, we observe that Theano and Torch are the most easily extensible frameworks. We observe that Torch is best suited for any deep architecture on CPU, followed by Theano. It also achieves the best performance on the GPU for large convolutional and fully connected networks, followed closely by Neon. Theano achieves the best performance on GPU for training and deployment of LSTM networks. Caffe is the easiest for evaluating the performance of standard deep architectures. Finally, TensorFlow is a very flexible framework, similar to Theano, but its performance is currently not competitive compared to the other studied frameworks.