 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Symbolic Representation Learning for Heterogeneous Time-series Classification
Dec 05, 2016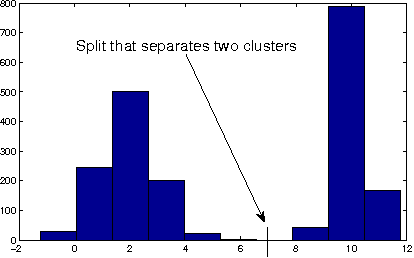

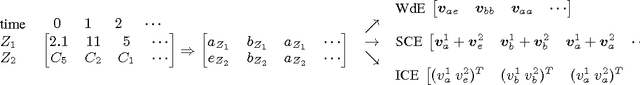

In this paper, we consider the problem of event classification with multi-variate time series data consisting of heterogeneous (continuous and categorical) variables. The complex temporal dependencies between the variables combined with sparsity of the data makes the event classification problem particularly challenging. Most state-of-art approaches address this either by designing hand-engineered features or breaking up the problem over homogeneous variates. In this work, we propose and compare three representation learning algorithms over symbolized sequences which enables classification of heterogeneous time-series data using a deep architecture. The proposed representations are trained jointly along with the rest of the network architecture in an end-to-end fashion that makes the learned features discriminative for the given task. Experiments on three real-world datasets demonstrate the effectiveness of the proposed approaches.
Comparative Study of Deep Learning Software Frameworks
Mar 30, 2016

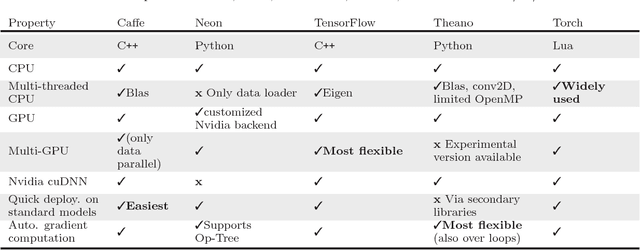
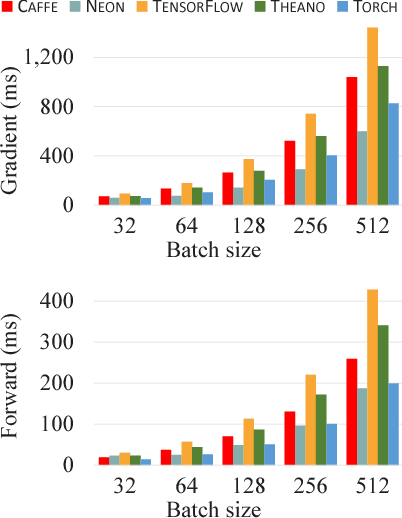
Deep learning methods have resulted in significant performance improvements in several application domains and as such several software frameworks have been developed to facilitate their implementation. This paper presents a comparative study of five deep learning frameworks, namely Caffe, Neon, TensorFlow, Theano, and Torch, on three aspects: extensibility, hardware utilization, and speed. The study is performed on several types of deep learning architectures and we evaluate the performance of the above frameworks when employed on a single machine for both (multi-threaded) CPU and GPU (Nvidia Titan X) settings. The speed performance metrics used here include the gradient computation time, which is important during the training phase of deep networks, and the forward time, which is important from the deployment perspective of trained networks. For convolutional networks, we also report how each of these frameworks support various convolutional algorithms and their corresponding performance. From our experiments, we observe that Theano and Torch are the most easily extensible frameworks. We observe that Torch is best suited for any deep architecture on CPU, followed by Theano. It also achieves the best performance on the GPU for large convolutional and fully connected networks, followed closely by Neon. Theano achieves the best performance on GPU for training and deployment of LSTM networks. Caffe is the easiest for evaluating the performance of standard deep architectures. Finally, TensorFlow is a very flexible framework, similar to Theano, but its performance is currently not competitive compared to the other studied frameworks.
Multimodal Task-Driven Dictionary Learning for Image Classification
Oct 27, 2015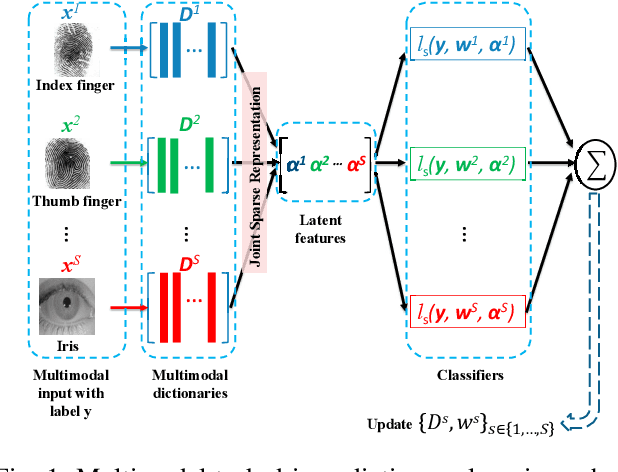

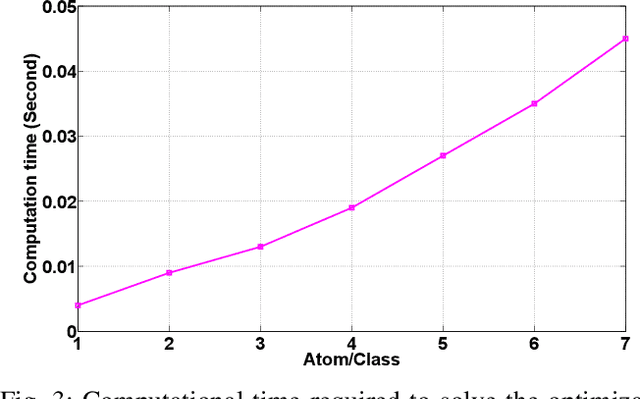
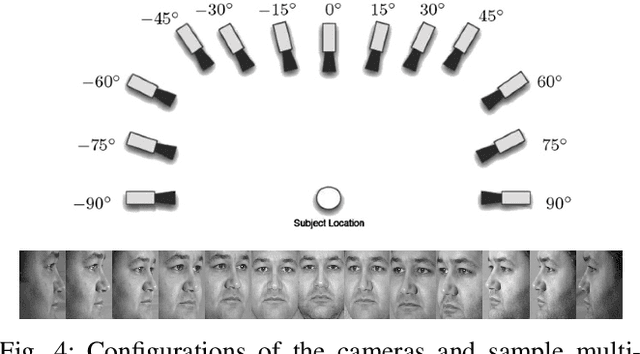
Dictionary learning algorithms have been successfully used for both reconstructive and discriminative tasks, where an input signal is represented with a sparse linear combination of dictionary atoms. While these methods are mostly developed for single-modality scenarios, recent studies have demonstrated the advantages of feature-level fusion based on the joint sparse representation of the multimodal inputs. In this paper, we propose a multimodal task-driven dictionary learning algorithm under the joint sparsity constraint (prior) to enforce collaborations among multiple homogeneous/heterogeneous sources of information. In this task-driven formulation, the multimodal dictionaries are learned simultaneously with their corresponding classifiers. The resulting multimodal dictionaries can generate discriminative latent features (sparse codes) from the data that are optimized for a given task such as binary or multiclass classification. Moreover, we present an extension of the proposed formulation using a mixed joint and independent sparsity prior which facilitates more flexible fusion of the modalities at feature level. The efficacy of the proposed algorithms for multimodal classification is illustrated on four different applications -- multimodal face recognition, multi-view face recognition, multi-view action recognition, and multimodal biometric recognition. It is also shown that, compared to the counterpart reconstructive-based dictionary learning algorithms, the task-driven formulations are more computationally efficient in the sense that they can be equipped with more compact dictionaries and still achieve superior performance.
Kernel Task-Driven Dictionary Learning for Hyperspectral Image Classification
Feb 10, 2015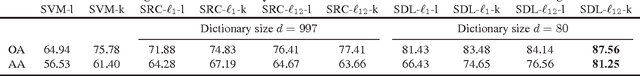

Dictionary learning algorithms have been successfully used in both reconstructive and discriminative tasks, where the input signal is represented by a linear combination of a few dictionary atoms. While these methods are usually developed under $\ell_1$ sparsity constrain (prior) in the input domain, recent studies have demonstrated the advantages of sparse representation using structured sparsity priors in the kernel domain. In this paper, we propose a supervised dictionary learning algorithm in the kernel domain for hyperspectral image classification. In the proposed formulation, the dictionary and classifier are obtained jointly for optimal classification performance. The supervised formulation is task-driven and provides learned features from the hyperspectral data that are well suited for the classification task. Moreover, the proposed algorithm uses a joint ($\ell_{12}$) sparsity prior to enforce collaboration among the neighboring pixels. The simulation results illustrate the efficiency of the proposed dictionary learning algorithm.
Quality-based Multimodal Classification Using Tree-Structured Sparsity
Mar 08, 2014



Recent studies have demonstrated advantages of information fusion based on sparsity models for multimodal classification. Among several sparsity models, tree-structured sparsity provides a flexible framework for extraction of cross-correlated information from different sources and for enforcing group sparsity at multiple granularities. However, the existing algorithm only solves an approximated version of the cost functional and the resulting solution is not necessarily sparse at group levels. This paper reformulates the tree-structured sparse model for multimodal classification task. An accelerated proximal algorithm is proposed to solve the optimization problem, which is an efficient tool for feature-level fusion among either homogeneous or heterogeneous sources of information. In addition, a (fuzzy-set-theoretic) possibilistic scheme is proposed to weight the available modalities, based on their respective reliability, in a joint optimization problem for finding the sparsity codes. This approach provides a general framework for quality-based fusion that offers added robustness to several sparsity-based multimodal classification algorithms. To demonstrate their efficacy, the proposed methods are evaluated on three different applications - multiview face recognition, multimodal face recognition, and target classification.
* To Appear in 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014)