 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Task-Driven Dictionary Learning for Image Classification
Paper and Code
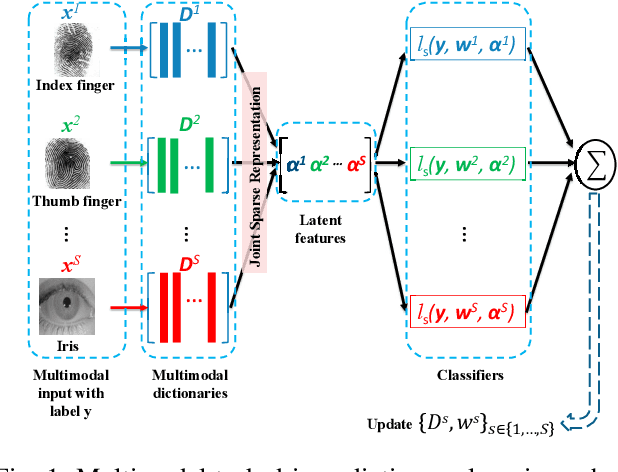

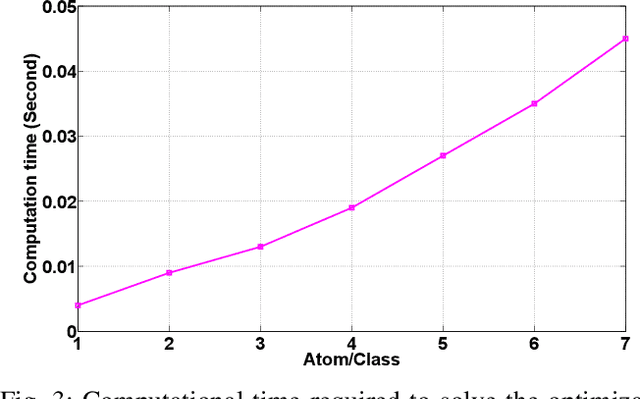
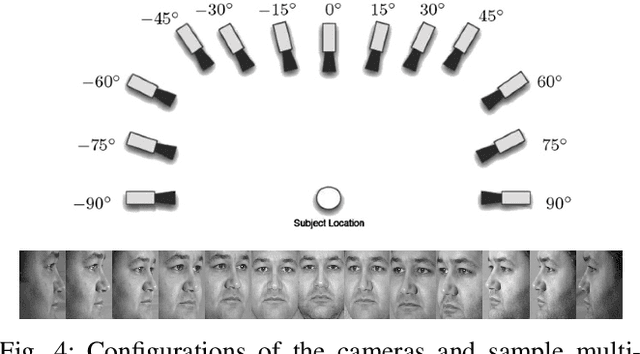
Dictionary learning algorithms have been successfully used for both reconstructive and discriminative tasks, where an input signal is represented with a sparse linear combination of dictionary atoms. While these methods are mostly developed for single-modality scenarios, recent studies have demonstrated the advantages of feature-level fusion based on the joint sparse representation of the multimodal inputs. In this paper, we propose a multimodal task-driven dictionary learning algorithm under the joint sparsity constraint (prior) to enforce collaborations among multiple homogeneous/heterogeneous sources of information. In this task-driven formulation, the multimodal dictionaries are learned simultaneously with their corresponding classifiers. The resulting multimodal dictionaries can generate discriminative latent features (sparse codes) from the data that are optimized for a given task such as binary or multiclass classification. Moreover, we present an extension of the proposed formulation using a mixed joint and independent sparsity prior which facilitates more flexible fusion of the modalities at feature level. The efficacy of the proposed algorithms for multimodal classification is illustrated on four different applications -- multimodal face recognition, multi-view face recognition, multi-view action recognition, and multimodal biometric recognition. It is also shown that, compared to the counterpart reconstructive-based dictionary learning algorithms, the task-driven formulations are more computationally efficient in the sense that they can be equipped with more compact dictionaries and still achieve superior performance.