 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Semantic Segmentation with Superpixel-Mix
Aug 02, 2021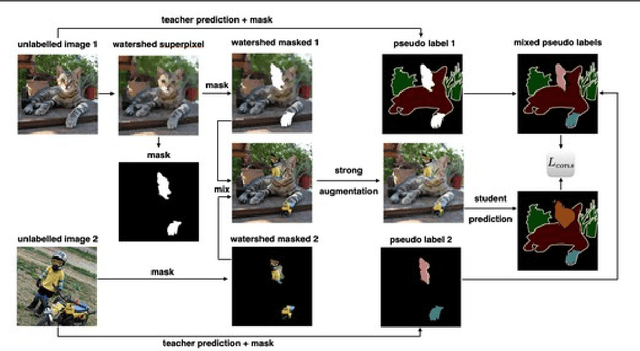
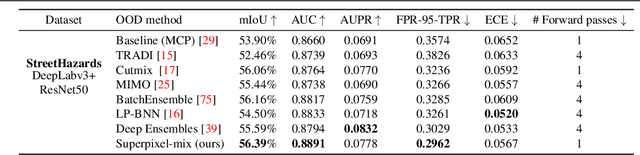
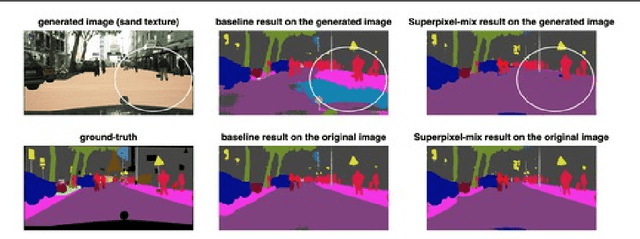
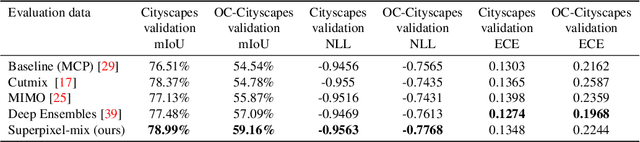
Along with predictive performance and runtime speed, reliability is a key requirement for real-world semantic segmentation. Reliability encompasses robustness, predictive uncertainty and reduced bias. To improve reliability, we introduce Superpixel-mix, a new superpixel-based data augmentation method with teacher-student consistency training. Unlike other mixing-based augmentation techniques, mixing superpixels between images is aware of object boundaries, while yielding consistent gains in segmentation accuracy. Our proposed technique achieves state-of-the-art results in semi-supervised semantic segmentation on the Cityscapes dataset. Moreover, Superpixel-mix improves the reliability of semantic segmentation by reducing network uncertainty and bias, as confirmed by competitive results under strong distributions shift (adverse weather, image corruptions) and when facing out-of-distribution data.
Learning a Discriminant Latent Space with Neural Discriminant Analysis
Jul 13, 2021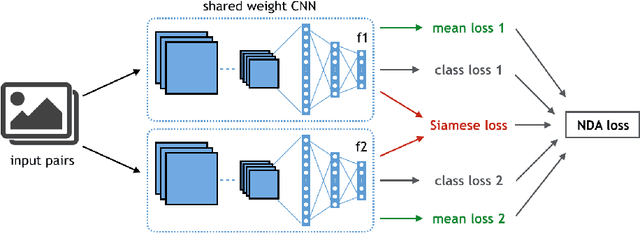

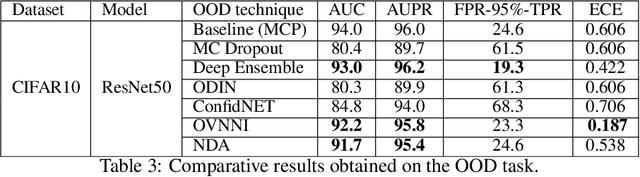
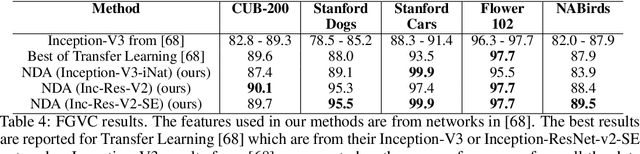
Discriminative features play an important role in image and object classification and also in other fields of research such as semi-supervised learning, fine-grained classification, out of distribution detection. Inspired by Linear Discriminant Analysis (LDA), we propose an optimization called Neural Discriminant Analysis (NDA) for Deep Convolutional Neural Networks (DCNNs). NDA transforms deep features to become more discriminative and, therefore, improves the performances in various tasks. Our proposed optimization has two primary goals for inter- and intra-class variances. The first one is to minimize variances within each individual class. The second goal is to maximize pairwise distances between features coming from different classes. We evaluate our NDA optimization in different research fields: general supervised classification, fine-grained classification, semi-supervised learning, and out of distribution detection. We achieve performance improvements in all the fields compared to baseline methods that do not use NDA. Besides, using NDA, we also surpass the state of the art on the four tasks on various testing datasets.
Deep Ranking with Adaptive Margin Triplet Loss
Jul 13, 2021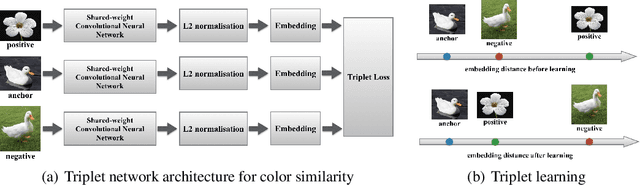



We propose a simple modification from a fixed margin triplet loss to an adaptive margin triplet loss. While the original triplet loss is used widely in classification problems such as face recognition, face re-identification and fine-grained similarity, our proposed loss is well suited for rating datasets in which the ratings are continuous values. In contrast to original triplet loss where we have to sample data carefully, in out method, we can generate triplets using the whole dataset, and the optimization can still converge without frequently running into a model collapsing issue. The adaptive margins only need to be computed once before the training, which is much less expensive than generating triplets after every epoch as in the fixed margin case. Besides substantially improved training stability (the proposed model never collapsed in our experiments compared to a couple of times that the training collapsed on existing triplet loss), we achieved slightly better performance than the original triplet loss on various rating datasets and network architectures.
3D Morphable Face Models -- Past, Present and Future
Sep 03, 2019
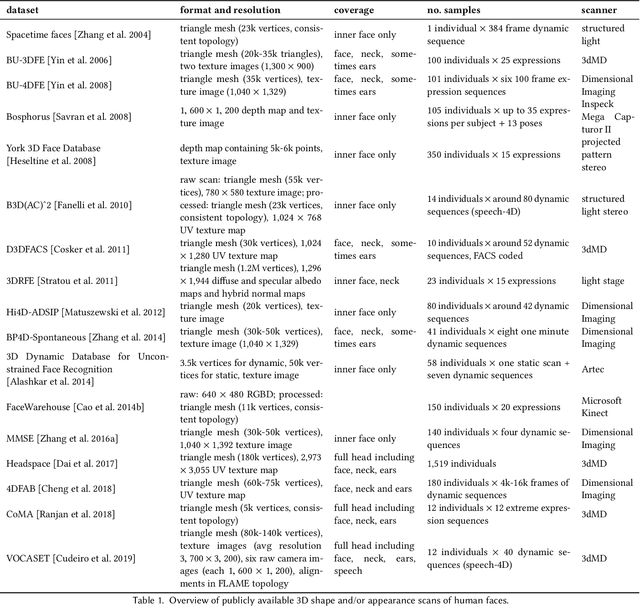
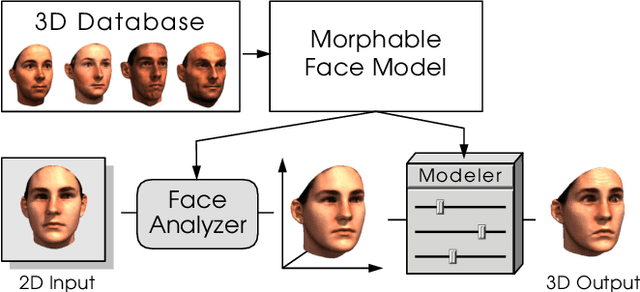
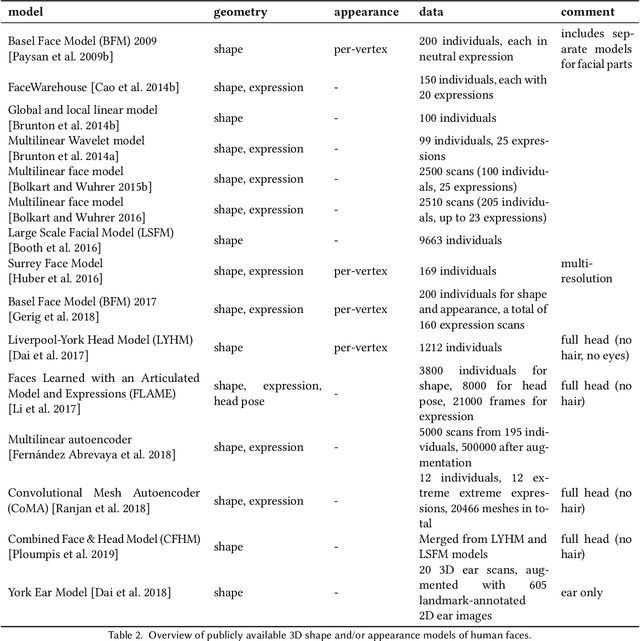
In this paper, we provide a detailed survey of 3D Morphable Face Models over the 20 years since they were first proposed. The challenges in building and applying these models, namely capture, modeling, image formation, and image analysis, are still active research topics, and we review the state-of-the-art in each of these areas. We also look ahead, identifying unsolved challenges, proposing directions for future research and highlighting the broad range of current and future applications.
Deep Convolutional Neural Networks in the Face of Caricature: Identity and Image Revealed
Dec 28, 2018

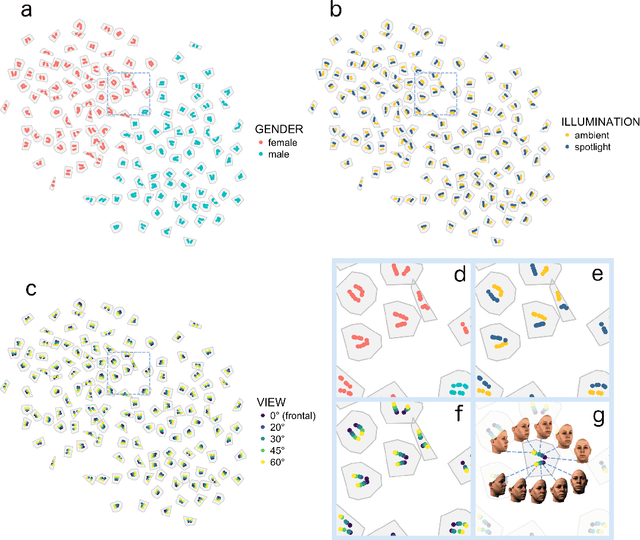
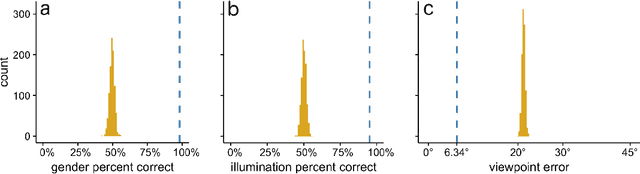
Real-world face recognition requires an ability to perceive the unique features of an individual face across multiple, variable images. The primate visual system solves the problem of image invariance using cascades of neurons that convert images of faces into categorical representations of facial identity. Deep convolutional neural networks (DCNNs) also create generalizable face representations, but with cascades of simulated neurons. DCNN representations can be examined in a multidimensional "face space", with identities and image parameters quantified via their projections onto the axes that define the space. We examined the organization of viewpoint, illumination, gender, and identity in this space. We show that the network creates a highly organized, hierarchically nested, face similarity structure in which information about face identity and imaging characteristics coexist. Natural image variation is accommodated in this hierarchy, with face identity nested under gender, illumination nested under identity, and viewpoint nested under illumination. To examine identity, we caricatured faces and found that network identification accuracy increased with caricature level, and--mimicking human perception--a caricatured distortion of a face "resembled" its veridical counterpart. Caricatures improved performance by moving the identity away from other identities in the face space and minimizing the effects of illumination and viewpoint. Deep networks produce face representations that solve long-standing computational problems in generalized face recognition. They also provide a unitary theoretical framework for reconciling decades of behavioral and neural results that emphasized either the image or the object/face in representations, without understanding how a neural code could seamlessly accommodate both.