 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Visual Signals for Robust Token-Level Uncertainty in Vision-Language Generation
May 26, 2026Uncertainty quantification (UQ) remains a critical challenge in Large Vision Language Models (LVLMs) for reliable predictions and real-world deployment. However, most existing methods are adapted from the LLM literature and primarily focus on the language modality, leaving the contribution of visual information to LVLM uncertainty largely underexplored. In this paper, we investigate how LVLMs process visual information and whether this process can be used to improve uncertainty estimation. By analyzing hidden representations after the integration of visual features during the generation process, we observe that high-confidence predictions rely more heavily on visual content than uncertain ones. Building on this insight, we propose Visual-Grounded Token UQ (VIG-TUQ), a training-free framework that explicitly incorporates visual grounding into uncertainty estimation by weighting token-level language uncertainty with visual grounding scores. We evaluate VIG-TUQ on multiple datasets and across diverse LVLM architectures, including early-fusion, late-fusion, and native-fusion models. Results indicate that our method often improves upon existing token-level uncertainty approaches. Code and data will be made available upon acceptance.
SS3D: End2End Self-Supervised 3D from Web Videos
Apr 24, 2026We present SS3D, a web-scale SfM-based self-supervision pretraining pipeline for feed-forward 3D estimation from monocular video. Our model jointly predicts depth, ego-motion, and intrinsics in a single forward pass and is trained/evaluated as a coherent end-to-end 3D estimator. To stabilize joint learning, we use an intrinsics-first two-stage schedule and a unified single-checkpoint evaluation protocol. Scaling SfM self-supervision to unconstrained web video is challenging due to weak multi-view observability and strong corpus heterogeneity; we address these with a multi-view signal proxy (MVS) used for filtering and curriculum sampling, and with expert training distilled into a single student. Pretraining on YouTube-8M (~100M frames after filtering) yields strong cross-domain zero-shot transfer and improved fine-tuning performance over prior self-supervised baselines. We release the pretrained checkpoint and code.
Improving Semantic Uncertainty Quantification in LVLMs with Semantic Gaussian Processes
Dec 16, 2025Large Vision-Language Models (LVLMs) often produce plausible but unreliable outputs, making robust uncertainty estimation essential. Recent work on semantic uncertainty estimates relies on external models to cluster multiple sampled responses and measure their semantic consistency. However, these clustering methods are often fragile, highly sensitive to minor phrasing variations, and can incorrectly group or separate semantically similar answers, leading to unreliable uncertainty estimates. We propose Semantic Gaussian Process Uncertainty (SGPU), a Bayesian framework that quantifies semantic uncertainty by analyzing the geometric structure of answer embeddings, avoiding brittle clustering. SGPU maps generated answers into a dense semantic space, computes the Gram matrix of their embeddings, and summarizes their semantic configuration via the eigenspectrum. This spectral representation is then fed into a Gaussian Process Classifier that learns to map patterns of semantic consistency to predictive uncertainty, and that can be applied in both black-box and white-box settings. Across six LLMs and LVLMs on eight datasets spanning VQA, image classification, and textual QA, SGPU consistently achieves state-of-the-art calibration (ECE) and discriminative (AUROC, AUARC) performance. We further show that SGPU transfers across models and modalities, indicating that its spectral representation captures general patterns of semantic uncertainty.
A Geometric Unification of Concept Learning with Concept Cones
Dec 08, 2025Two traditions of interpretability have evolved side by side but seldom spoken to each other: Concept Bottleneck Models (CBMs), which prescribe what a concept should be, and Sparse Autoencoders (SAEs), which discover what concepts emerge. While CBMs use supervision to align activations with human-labeled concepts, SAEs rely on sparse coding to uncover emergent ones. We show that both paradigms instantiate the same geometric structure: each learns a set of linear directions in activation space whose nonnegative combinations form a concept cone. Supervised and unsupervised methods thus differ not in kind but in how they select this cone. Building on this view, we propose an operational bridge between the two paradigms. CBMs provide human-defined reference geometries, while SAEs can be evaluated by how well their learned cones approximate or contain those of CBMs. This containment framework yields quantitative metrics linking inductive biases -- such as SAE type, sparsity, or expansion ratio -- to emergence of plausible\footnote{We adopt the terminology of \citet{jacovi2020towards}, who distinguish between faithful explanations (accurately reflecting model computations) and plausible explanations (aligning with human intuition and domain knowledge). CBM concepts are plausible by construction -- selected or annotated by humans -- though not necessarily faithful to the true latent factors that organise the data manifold.} concepts. Using these metrics, we uncover a ``sweet spot'' in both sparsity and expansion factor that maximizes both geometric and semantic alignment with CBM concepts. Overall, our work unifies supervised and unsupervised concept discovery through a shared geometric framework, providing principled metrics to measure SAE progress and assess how well discovered concept align with plausible human concepts.
Torch-Uncertainty: A Deep Learning Framework for Uncertainty Quantification
Nov 13, 2025Deep Neural Networks (DNNs) have demonstrated remarkable performance across various domains, including computer vision and natural language processing. However, they often struggle to accurately quantify the uncertainty of their predictions, limiting their broader adoption in critical real-world applications. Uncertainty Quantification (UQ) for Deep Learning seeks to address this challenge by providing methods to improve the reliability of uncertainty estimates. Although numerous techniques have been proposed, a unified tool offering a seamless workflow to evaluate and integrate these methods remains lacking. To bridge this gap, we introduce Torch-Uncertainty, a PyTorch and Lightning-based framework designed to streamline DNN training and evaluation with UQ techniques and metrics. In this paper, we outline the foundational principles of our library and present comprehensive experimental results that benchmark a diverse set of UQ methods across classification, segmentation, and regression tasks. Our library is available at https://github.com/ENSTA-U2IS-AI/Torch-Uncertainty
Enhancing Concept Localization in CLIP-based Concept Bottleneck Models
Oct 08, 2025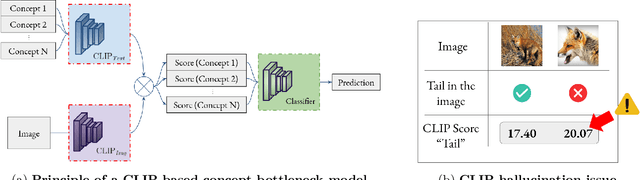

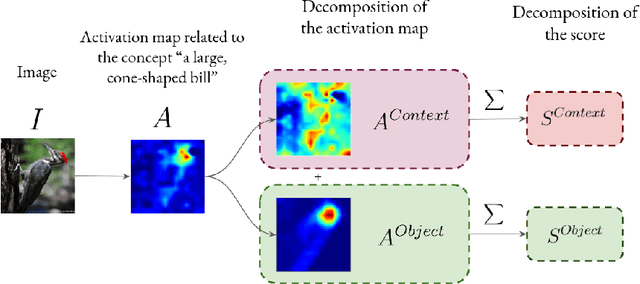

This paper addresses explainable AI (XAI) through the lens of Concept Bottleneck Models (CBMs) that do not require explicit concept annotations, relying instead on concepts extracted using CLIP in a zero-shot manner. We show that CLIP, which is central in these techniques, is prone to concept hallucination, incorrectly predicting the presence or absence of concepts within an image in scenarios used in numerous CBMs, hence undermining the faithfulness of explanations. To mitigate this issue, we introduce Concept Hallucination Inhibition via Localized Interpretability (CHILI), a technique that disentangles image embeddings and localizes pixels corresponding to target concepts. Furthermore, our approach supports the generation of saliency-based explanations that are more interpretable.
FakeParts: a New Family of AI-Generated DeepFakes
Aug 28, 2025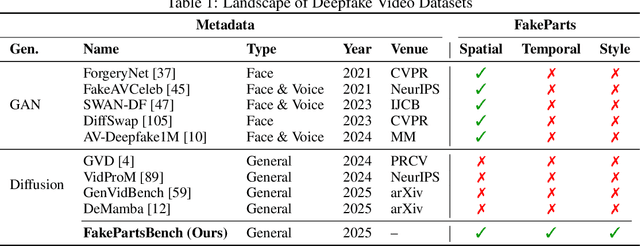
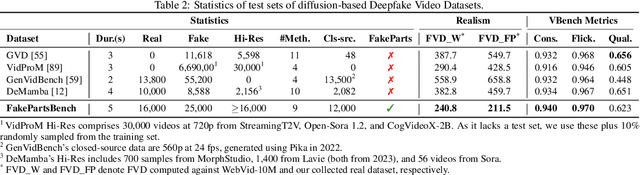
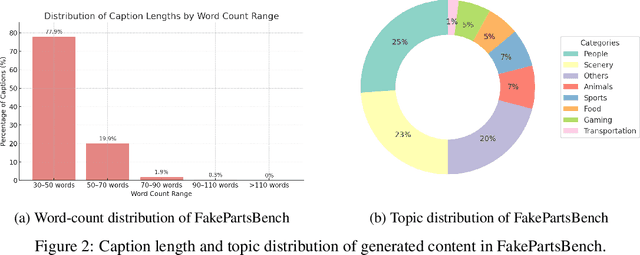
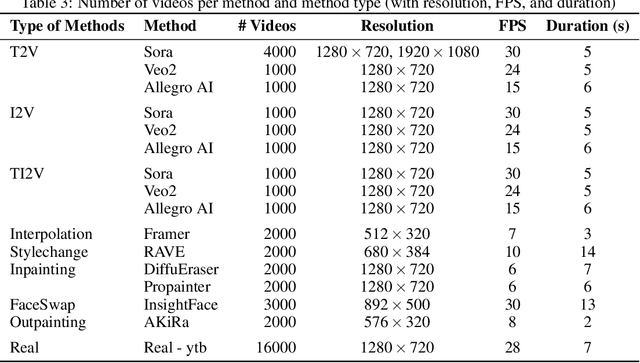
We introduce FakeParts, a new class of deepfakes characterized by subtle, localized manipulations to specific spatial regions or temporal segments of otherwise authentic videos. Unlike fully synthetic content, these partial manipulations, ranging from altered facial expressions to object substitutions and background modifications, blend seamlessly with real elements, making them particularly deceptive and difficult to detect. To address the critical gap in detection capabilities, we present FakePartsBench, the first large-scale benchmark dataset specifically designed to capture the full spectrum of partial deepfakes. Comprising over 25K videos with pixel-level and frame-level manipulation annotations, our dataset enables comprehensive evaluation of detection methods. Our user studies demonstrate that FakeParts reduces human detection accuracy by over 30% compared to traditional deepfakes, with similar performance degradation observed in state-of-the-art detection models. This work identifies an urgent vulnerability in current deepfake detection approaches and provides the necessary resources to develop more robust methods for partial video manipulations.
COOkeD: Ensemble-based OOD detection in the era of zero-shot CLIP
Jul 30, 2025Out-of-distribution (OOD) detection is an important building block in trustworthy image recognition systems as unknown classes may arise at test-time. OOD detection methods typically revolve around a single classifier, leading to a split in the research field between the classical supervised setting (e.g. ResNet18 classifier trained on CIFAR100) vs. the zero-shot setting (class names fed as prompts to CLIP). In both cases, an overarching challenge is that the OOD detection performance is implicitly constrained by the classifier's capabilities on in-distribution (ID) data. In this work, we show that given a little open-mindedness from both ends, remarkable OOD detection can be achieved by instead creating a heterogeneous ensemble - COOkeD combines the predictions of a closed-world classifier trained end-to-end on a specific dataset, a zero-shot CLIP classifier, and a linear probe classifier trained on CLIP image features. While bulky at first sight, this approach is modular, post-hoc and leverages the availability of pre-trained VLMs, thus introduces little overhead compared to training a single standard classifier. We evaluate COOkeD on popular CIFAR100 and ImageNet benchmarks, but also consider more challenging, realistic settings ranging from training-time label noise, to test-time covariate shift, to zero-shot shift which has been previously overlooked. Despite its simplicity, COOkeD achieves state-of-the-art performance and greater robustness compared to both classical and CLIP-based OOD detection methods. Code is available at https://github.com/glhr/COOkeD
Explainability for Vision Foundation Models: A Survey
Jan 21, 2025


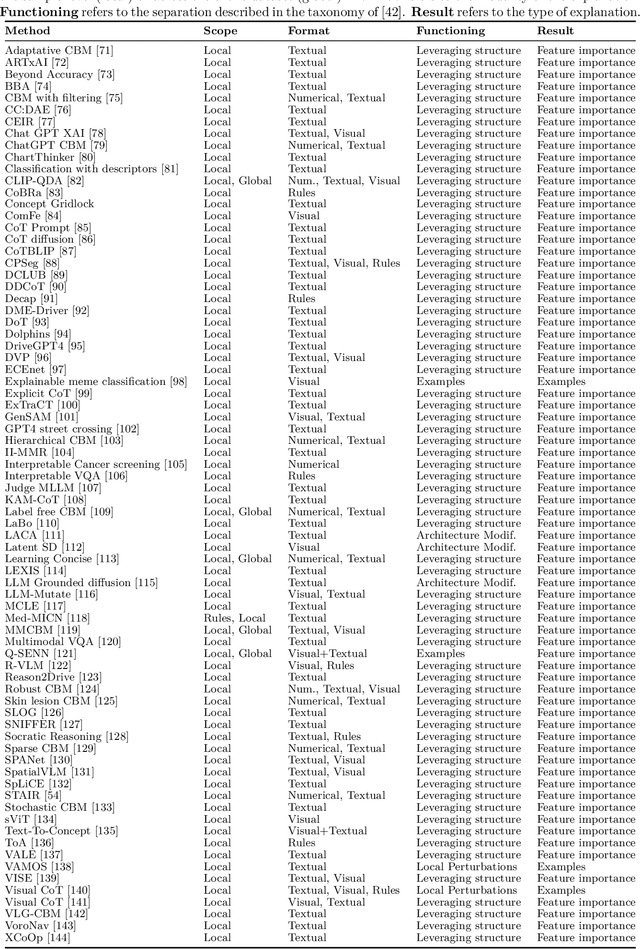
As artificial intelligence systems become increasingly integrated into daily life, the field of explainability has gained significant attention. This trend is particularly driven by the complexity of modern AI models and their decision-making processes. The advent of foundation models, characterized by their extensive generalization capabilities and emergent uses, has further complicated this landscape. Foundation models occupy an ambiguous position in the explainability domain: their complexity makes them inherently challenging to interpret, yet they are increasingly leveraged as tools to construct explainable models. In this survey, we explore the intersection of foundation models and eXplainable AI (XAI) in the vision domain. We begin by compiling a comprehensive corpus of papers that bridge these fields. Next, we categorize these works based on their architectural characteristics. We then discuss the challenges faced by current research in integrating XAI within foundation models. Furthermore, we review common evaluation methodologies for these combined approaches. Finally, we present key observations and insights from our survey, offering directions for future research in this rapidly evolving field.
Towards Understanding and Quantifying Uncertainty for Text-to-Image Generation
Dec 04, 2024Uncertainty quantification in text-to-image (T2I) generative models is crucial for understanding model behavior and improving output reliability. In this paper, we are the first to quantify and evaluate the uncertainty of T2I models with respect to the prompt. Alongside adapting existing approaches designed to measure uncertainty in the image space, we also introduce Prompt-based UNCertainty Estimation for T2I models (PUNC), a novel method leveraging Large Vision-Language Models (LVLMs) to better address uncertainties arising from the semantics of the prompt and generated images. PUNC utilizes a LVLM to caption a generated image, and then compares the caption with the original prompt in the more semantically meaningful text space. PUNC also enables the disentanglement of both aleatoric and epistemic uncertainties via precision and recall, which image-space approaches are unable to do. Extensive experiments demonstrate that PUNC outperforms state-of-the-art uncertainty estimation techniques across various settings. Uncertainty quantification in text-to-image generation models can be used on various applications including bias detection, copyright protection, and OOD detection. We also introduce a comprehensive dataset of text prompts and generation pairs to foster further research in uncertainty quantification for generative models. Our findings illustrate that PUNC not only achieves competitive performance but also enables novel applications in evaluating and improving the trustworthiness of text-to-image models.