 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Model Merging Unlocks Simple and Scalable Multimodal Data Mixture Optimization
Feb 04, 2026Selecting the best data mixture is critical for successful Supervised Fine-Tuning (SFT) of Multimodal Large Language Models. However, determining the optimal mixture weights across multiple domain-specific datasets remains a significant bottleneck due to the combinatorial search space and the high cost associated with even a single training run. This is the so-called Data Mixture Optimization (DMO) problem. On the other hand, model merging unifies domain-specific experts through parameter interpolation. This strategy is efficient, as it only requires a single training run per domain, yet oftentimes leads to suboptimal models. In this work, we take the best of both worlds, studying model merging as an efficient strategy for estimating the performance of different data mixtures. We train domain-specific multimodal experts and evaluate their weighted parameter-space combinations to estimate the efficacy of corresponding data mixtures. We conduct extensive experiments on 14 multimodal benchmarks, and empirically demonstrate that the merged proxy models exhibit a high rank correlation with models trained on actual data mixtures. This decouples the search for optimal mixtures from the resource-intensive training process, thereby providing a scalable and efficient strategy for navigating the complex landscape of mixture weights. Code is publicly available at https://github.com/BerasiDavide/mLLMs_merging_4_DMO.
Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models
Mar 21, 2025Vision-Language Models (VLMs) learn a shared feature space for text and images, enabling the comparison of inputs of different modalities. While prior works demonstrated that VLMs organize natural language representations into regular structures encoding composite meanings, it remains unclear if compositional patterns also emerge in the visual embedding space. In this work, we investigate compositionality in the image domain, where the analysis of compositional properties is challenged by noise and sparsity of visual data. We address these problems and propose a framework, called Geodesically Decomposable Embeddings (GDE), that approximates image representations with geometry-aware compositional structures in the latent space. We demonstrate that visual embeddings of pre-trained VLMs exhibit a compositional arrangement, and evaluate the effectiveness of this property in the tasks of compositional classification and group robustness. GDE achieves stronger performance in compositional classification compared to its counterpart method that assumes linear geometry of the latent space. Notably, it is particularly effective for group robustness, where we achieve higher results than task-specific solutions. Our results indicate that VLMs can automatically develop a human-like form of compositional reasoning in the visual domain, making their underlying processes more interpretable. Code is available at https://github.com/BerasiDavide/vlm_image_compositionality.
Rethinking Few-Shot Adaptation of Vision-Language Models in Two Stages
Mar 14, 2025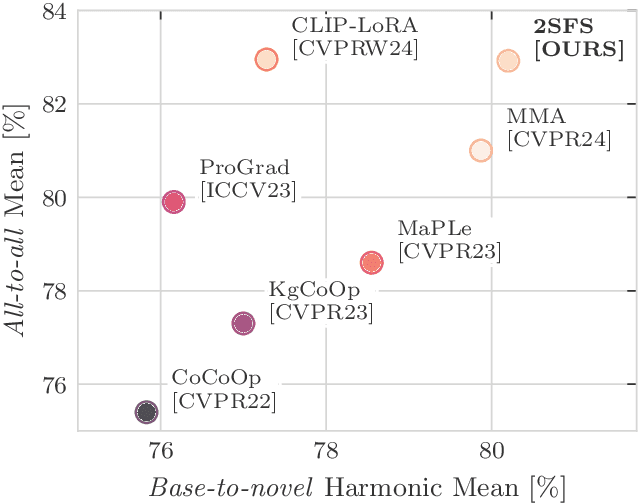
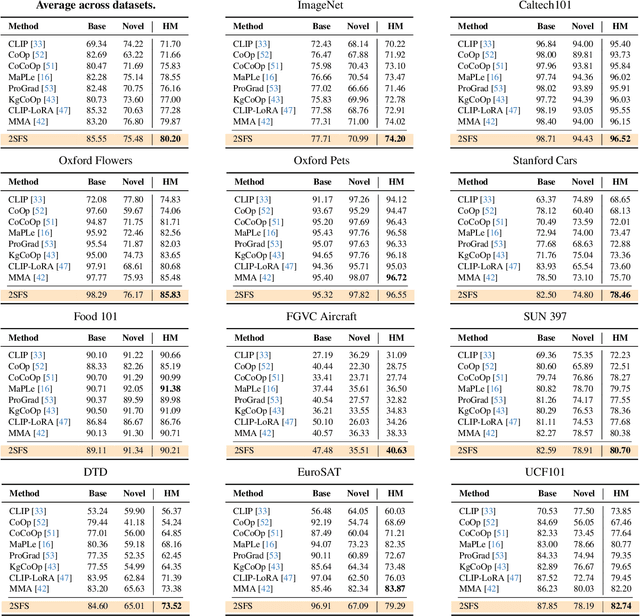
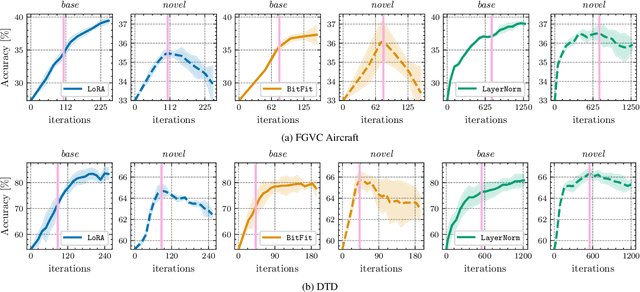
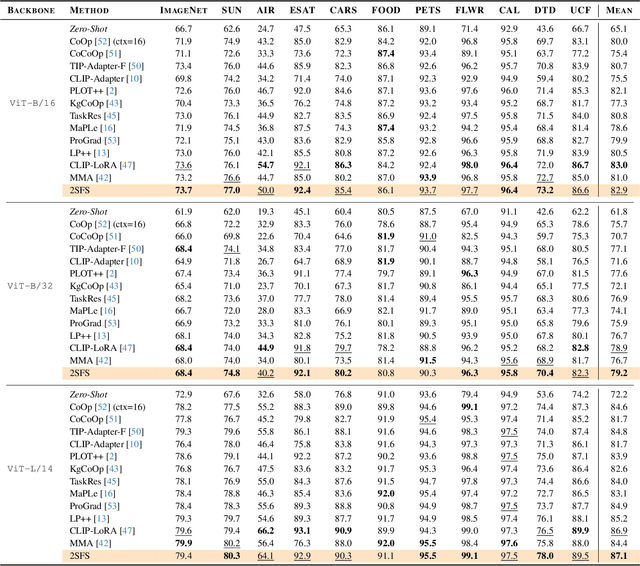
An old-school recipe for training a classifier is to (i) learn a good feature extractor and (ii) optimize a linear layer atop. When only a handful of samples are available per category, as in Few-Shot Adaptation (FSA), data are insufficient to fit a large number of parameters, rendering the above impractical. This is especially true with large pre-trained Vision-Language Models (VLMs), which motivated successful research at the intersection of Parameter-Efficient Fine-tuning (PEFT) and FSA. In this work, we start by analyzing the learning dynamics of PEFT techniques when trained on few-shot data from only a subset of categories, referred to as the ``base'' classes. We show that such dynamics naturally splits into two distinct phases: (i) task-level feature extraction and (ii) specialization to the available concepts. To accommodate this dynamic, we then depart from prompt- or adapter-based methods and tackle FSA differently. Specifically, given a fixed computational budget, we split it to (i) learn a task-specific feature extractor via PEFT and (ii) train a linear classifier on top. We call this scheme Two-Stage Few-Shot Adaptation (2SFS). Differently from established methods, our scheme enables a novel form of selective inference at a category level, i.e., at test time, only novel categories are embedded by the adapted text encoder, while embeddings of base categories are available within the classifier. Results with fixed hyperparameters across two settings, three backbones, and eleven datasets, show that 2SFS matches or surpasses the state-of-the-art, while established methods degrade significantly across settings.
Frustratingly Easy Test-Time Adaptation of Vision-Language Models
May 28, 2024



Vision-Language Models seamlessly discriminate among arbitrary semantic categories, yet they still suffer from poor generalization when presented with challenging examples. For this reason, Episodic Test-Time Adaptation (TTA) strategies have recently emerged as powerful techniques to adapt VLMs in the presence of a single unlabeled image. The recent literature on TTA is dominated by the paradigm of prompt tuning by Marginal Entropy Minimization, which, relying on online backpropagation, inevitably slows down inference while increasing memory. In this work, we theoretically investigate the properties of this approach and unveil that a surprisingly strong TTA method lies dormant and hidden within it. We term this approach ZERO (TTA with "zero" temperature), whose design is both incredibly effective and frustratingly simple: augment N times, predict, retain the most confident predictions, and marginalize after setting the Softmax temperature to zero. Remarkably, ZERO requires a single batched forward pass through the vision encoder only and no backward passes. We thoroughly evaluate our approach following the experimental protocol established in the literature and show that ZERO largely surpasses or compares favorably w.r.t. the state-of-the-art while being almost 10x faster and 13x more memory-friendly than standard Test-Time Prompt Tuning. Thanks to its simplicity and comparatively negligible computation, ZERO can serve as a strong baseline for future work in this field. The code is available at https://github.com/FarinaMatteo/zero.
MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning
Apr 08, 2024



While excellent in transfer learning, Vision-Language models (VLMs) come with high computational costs due to their large number of parameters. To address this issue, removing parameters via model pruning is a viable solution. However, existing techniques for VLMs are task-specific, and thus require pruning the network from scratch for each new task of interest. In this work, we explore a new direction: Task-Agnostic Vision-Language Pruning (TA-VLP). Given a pretrained VLM, the goal is to find a unique pruned counterpart transferable to multiple unknown downstream tasks. In this challenging setting, the transferable representations already encoded in the pretrained model are a key aspect to preserve. Thus, we propose Multimodal Flow Pruning (MULTIFLOW), a first, gradient-free, pruning framework for TA-VLP where: (i) the importance of a parameter is expressed in terms of its magnitude and its information flow, by incorporating the saliency of the neurons it connects; and (ii) pruning is driven by the emergent (multimodal) distribution of the VLM parameters after pretraining. We benchmark eight state-of-the-art pruning algorithms in the context of TA-VLP, experimenting with two VLMs, three vision-language tasks, and three pruning ratios. Our experimental results show that MULTIFLOW outperforms recent sophisticated, combinatorial competitors in the vast majority of the cases, paving the way towards addressing TA-VLP. The code is publicly available at https://github.com/FarinaMatteo/multiflow.
Quantum Multi-Model Fitting
Mar 27, 2023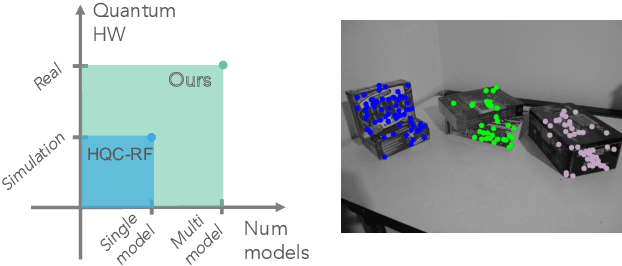
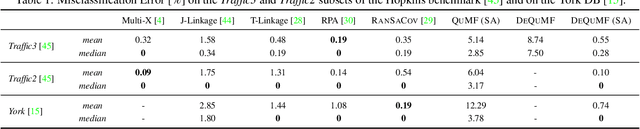


Geometric model fitting is a challenging but fundamental computer vision problem. Recently, quantum optimization has been shown to enhance robust fitting for the case of a single model, while leaving the question of multi-model fitting open. In response to this challenge, this paper shows that the latter case can significantly benefit from quantum hardware and proposes the first quantum approach to multi-model fitting (MMF). We formulate MMF as a problem that can be efficiently sampled by modern adiabatic quantum computers without the relaxation of the objective function. We also propose an iterative and decomposed version of our method, which supports real-world-sized problems. The experimental evaluation demonstrates promising results on a variety of datasets. The source code is available at: https://github.com/FarinaMatteo/qmmf.